ChatGPT 引爆向量数据库赛道
向量数据库和 Embedding 是现在 AI 领域的热门话题。
最近,为 ChatGPT 等生成式 AI 应用提供向量搜索、向量数据存储、向量嵌入等功能的向量数据库赛道突然走红,两家初创公司 Pinecone 和 Weaviate 共获 10 亿元融资,融资时间仅间隔6天,而 Shopify、Brex、Hubspot 等公司正在将向量数据库和 Embedding 作为其 AI 应用的基础。
事实上,在 ChatGPT 火爆出圈之前向量数据库非常小众,大量开发者涌向生成式 AI 应用开发领域,这使得蛰伏的向量数据库厂商终于迎来了曙光,其用户数量呈指数级增长,也是获得巨额投资的重要原因之一。
什么是向量 Embedding,如何工作?
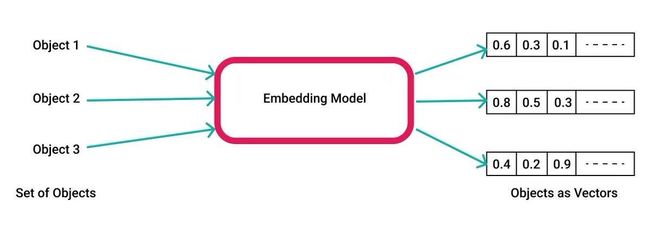
首先,所谓向量 Embedding 简单地说就是 N 维数字向量,可以代表任何东西,包括文本、音乐、视频等等,我们主要关注的是文本。要创建一个向量 Embedding,我们需要借助于 Embedding 模型(例如 OpenAI 的 Ada),把想要处理的文本内容输入到模型里面,就可以生成一个向量表示,并把它存储起来以备之后使用。
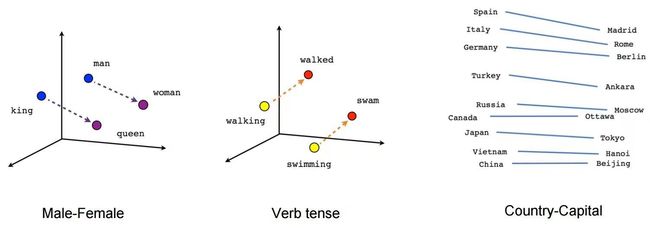
向量数据库与 Embedding 之所以非常重要,因为它使我们能够进行语义搜索,即通过相似性来搜索数据,比如寻找具有相似含义的文本。例如,在向量空间上建模男人、国王,女人和女王的关系时就能非常明确地看出它们之间的相关性。
更为直观的例子:
假设你是一个孩子,有一个大玩具盒子。现在你想找一些类似的玩具,比如玩具汽车和玩具巴士。它们都是交通工具,这就被称为“语义相似性”(事物有着相似的含义)。
再假设你有两个相关的玩具,但并不相同。例如一个玩具汽车和一条玩具道路。尽管它们不完全相同,但会被认为是相似的,因为汽车通常是开在道路上的。
为什么向量数据库与 Embedding 如此重要呢?
这是因为绝大多数 LLM 有其上下文限制,在理想情况下,我们可以将无限数量的单词拟合到 LLM 提示中,但目前这个限制通常被限制在约 4096 - 32k 个 tokens。
因此,我们受到 LLM 在"内存"方面的严格限制(即我们可以将多少单词拟合到其提示中),从而影响了与 LLM 交互的方式,这就是为什么你不能将整个 PDF 文档复制粘贴到 ChatGPT 中进行问答。
如何让 LLM 读取大文本呢?
假设你有一个巨大的 PDF 文件,你很懒不想读整个文件,而且你也不能把整个文件复制进去,因为它超过了一亿页,怎么办?
我们可以利用向量 Embedding 的优势来将相关文本注入 LLM 上下文窗口。对 PDF 进行向量 Embedding 并将其存储在向量数据库中。
具体做法:
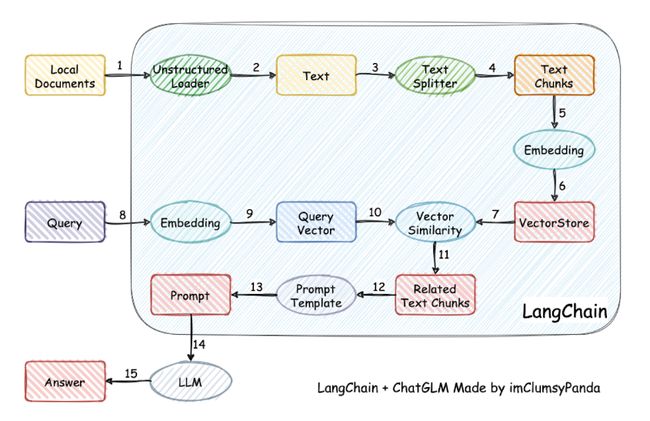
1)把 PDF 切分成小的文本片段,通过 Embedding 模型创建向量 Embedding 放到本地或远程向量数据库。
2)把用户的提问也创建成向量 Embedding,用它和之前创建的 PDF 向量比对,通过语义相似性搜索(比如余弦算法),找到最相关的文本片段。
3)把用户提问和相似文本片段发给 LLM,写 Prompt 要求 LLM 基于给定的内容生成回答,如果没有相似文本或关联度不高,则回答不知道。
这就是向量 Embedding 的最典型应用。Github 上非常火的 langchain-ChatGLM 项目,用的就是 LLM 结合向量 Embedding,来达到本地知识库问答的效果,后面树先生也会为大家带来相关教程。