一文带你彻底掌握Java Stream流
最近在看同事们的代码,发现很多地方都在用stream流进行集合的相关的操作,看了之后感觉确实很简洁、优雅,今天带着大家一起学习一下stream流的相关操作。
1.什么是stream流
Java 8 新增的 Stream 是为了解放程序员操作集合(Collection)时的生产力,之所以能解放,很大一部分原因可以归功于同时出现的 Lambda 表达式——极大的提高了编程效率和程序可读性。
从“Stream”这个单词上来看,它似乎和 java.io 包下的 InputStream 和 OutputStream 有些关系。实际上呢,没毛关系。Java 8 新增的 Stream 是为了解放程序员操作集合(Collection)时的生产力,之所以能解放,很大一部分原因可以归功于同时出现的 Lambda 表达式——极大的提高了编程效率和程序可读性。
同时stream不是一种数据结构,它只是某种数据源的一个视图,数据源可以是一个数组,Java容器或I/O channel等。在Stream中的操作每一次都会产生新的流,内部不会像普通集合操作一样立刻获取值,而是惰性 取值,只有等到用户真正需要结果的时候才会执行。并且对于现在调用的方法,本身都是一种高层次构件,与线程模型无关。因此在并行使用中,开发者们无需再去操心线程和锁了。Stream内部都已经做好了。
2.流操作详解
2.1 流创建
生成流的方式主要有五种
1.Stream创建
//创建一个顺序流
Stream<Integer> stream1 = Stream.of(1,2,3,4,5);
// 创建一个并行流
Stream<String> parallelStream = list.parallelStream();
stream是顺序流,由主线程按顺序对流执行操作,而parallelStream是并行流,内部以多线程并行执行的方式对流进行操作,但前提是流中的数据处理没有顺序要求。
以筛选集合中的奇数为例,来看看两者之间处理方式有何不同
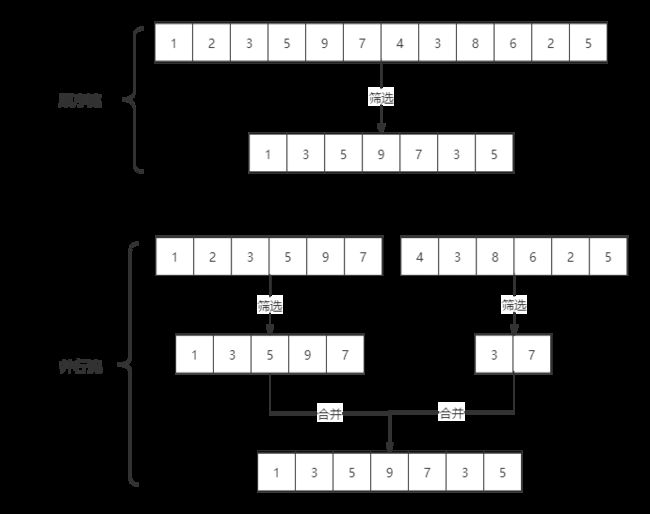
如果流中的数据量足够大,并行流可以加快处速度。
除了直接创建并行流,还可以通过parallel()把顺序流转换成并行流:
Optional<Integer> findFirst = list.stream().parallel().filter(x->x>100).findFirst();
2.Collection集合创建(实际使用中最常用的一种)
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
Stream<Integer> listStream = list.stream();
3.Array数组创建
int[] intArr = {1, 2, 3, 4, 5};
IntStream arrayStream = Arrays.stream(intArr);
值得我们注意的是通过Arrays.stream方法生成流,并且该方法生成的流是数值流【即IntStream】而不是 Stream
使用数值流可以避免计算过程中拆箱装箱,提高性能。
Stream API提供了mapToInt、mapToDouble、mapToLong三种方式将对象流,可以将Stream转换成对应的数值流,同时提供了boxed方法将数值流转换为对象流
4.文件创建
try {
Stream<String> fileStream = Files.lines(Paths.get("data.txt"), Charset.defaultCharset());
} catch (IOException e) {
e.printStackTrace();
}
通过Files.line方法得到一个流,并且得到的每个流是给定文件中的一行
5.函数创建
函数创建也有两种方式:
iterator
Stream<Integer> iterateStream = Stream.iterate(0, n -> n + 2).limit(5);
iterate方法接受两个参数,第一个为初始化值,第二个为进行的函数操作,因为iterator生成的流为无限流,通过limit方法对流进行了截断。
上面这段代码的含义则是:n从0开始,每次执行+2操作,并通过limit限制操作的次数,即生成5个偶数
generator
Stream<Double> generateStream = Stream.generate(Math::random).limit(5);
generate方法接受一个参数,方法参数类型为Supplier ,由它为流提供值。generate生成的流也是无限流,因此通过limit对流进行了截断
2.2 操作流
Stream 类提供了很多有用的操作流的方法,根据流的操作类型,主要分为:中间操作和终端操作
- 中间操作:会返回一个流,通过这种方式可以将多个中间操作连接起来,形成一个调用链,从而转换为另外 一个流。除非调用链后存在一个终端操作,否则中间操作对流不会进行任何结果处理。
- 终端操作:会返回一个具体的结果,如boolean、list、integer等
举个简单的例子来理解这两种操作类型
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
long count = list.stream().distinct().count();
System.out.println(count);
distinct() 方法是一个中间操作(去重),它会返回一个新的流(没有共同元素)。
Stream<T> distinct();
而count则是一个终端操作,因为它返回的是一个具体的结果
long count();
中间操作不会立即执行,只有等到终端操作的时候,流才开始真正地遍历,用于映射、过滤等。通俗点说,就是一次遍历执行多个操作,性能就大大提高了。
通常对于Stream的中间操作,可以视为是源的查询,并且是懒惰式的设计,对于源数据进行的计算只有在需要时才会被执行,与数据库中视图的原理相似;
Stream流的强大之处便是在于提供了丰富的中间操作,相比集合或数组这类容器,极大的简化源数据的计算复杂度
一个流可以跟随零个或多个中间操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用
这类操作都是惰性化的,仅仅调用到这类方法,并没有真正开始流的遍历,真正的遍历需等到终端操作时,常见的中间操作有下面即将介绍的 filter、map 等
| 流方法 | 含义 | 示例 |
|---|---|---|
| filter | 用于通过设置的条件过滤出元素 | List strings = Arrays.asList(“abc”, “”, “bc”, “efg”, “abcd”,“”, “jkl”); List filtered = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.toList()); |
| map | 接受一个函数作为参数。这个函数会被应用到每个元素上,并将其映射成一个新的元素(使用映射一词,是因为它和转换类似,但其中的细微差别在于它是“创建一个新版本”而不是去“修改”) | List strings = Arrays.asList(“abc”, “abc”, “bc”, “efg”, “abcd”,“jkl”, “jkl”); List mapped = strings.stream().map(str->str+“-IT”).collect(Collectors.toList()); |
| distinct | 返回一个元素各异(根据流所生成元素的hashCode和equals方法实现)的流 | List numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4);numbers.stream().filter(i -> i % 2 == 0).distinct().forEach(System.out::println); |
| sorted | 返回排序后的流 | List strings1 = Arrays.asList(“abc”, “abd”, “aba”, “efg”, “abcd”,“jkl”, “jkl”); List sorted1 = strings1.stream().sorted().collect(Collectors.toList()); |
| limit | 会返回一个不超过给定长度的流 | List strings = Arrays.asList(“abc”, “abc”, “bc”, “efg”, “abcd”,“jkl”, “jkl”); List limited = strings.stream().limit(3).collect(Collectors.toList()); |
| skip | 返回一个扔掉了前n个元素的流 | List strings = Arrays.asList(“abc”, “abc”, “bc”, “efg”, “abcd”,“jkl”, “jkl”); List skiped = strings.stream().skip(3).collect(Collectors.toList()); |
| flatMap | 使用flatMap方法的效果是,各个数组并不是分别映射成一个流,而是映射成流的内容。所有使用map(Arrays::stream)时生成的单个流都被合并起来,即扁平化为一个流 | List strings = Arrays.asList(“abc”, “abc”, “bc”, “efg”, “abcd”,“jkl”, “jkl”); Stream flatMap = strings.stream().flatMap(Java8StreamTest::getCharacterByString); |
| peek | 对元素进行遍历处理 | List strings = Arrays.asList(“abc”, “abc”, “bc”, “efg”, “abcd”,“jkl”, “jkl”); strings .stream().peek(str-> str + “a”).forEach(System.out::println); |
在进行具体的操作之前,大家可以mock一些数据进行测试
private static List<User> getUserList() {
List<User> userList = new ArrayList<>();
userList.add(new User(1,"张三",18,"上海"));
userList.add(new User(2,"王五",16,"上海"));
userList.add(new User(3,"李四",20,"上海"));
userList.add(new User(4,"张雷",22,"北京"));
userList.add(new User(5,"张超",15,"深圳"));
userList.add(new User(6,"李雷",24,"北京"));
userList.add(new User(7,"王爷",21,"上海"));
userList.add(new User(8,"张三丰",18,"广州"));
userList.add(new User(9,"赵六",16,"广州"));
userList.add(new User(10,"赵无极",26,"深圳"));
return userList;
}
public class User {//自己写构造函数和get set方法吧
Integer id;
String name;
int age;
String address;
}
filter:过滤、筛选
用于通过设置的条件过滤出元素,该方法会接收一个返回boolean的函数作为参数,终返回一个包括所有符合条件元素的流。
List<User> userList=getUserList();//getUserList方法在文章上面
//获取年龄大于等于20的用户
List<User> res=userList.stream().filter(user -> user.getAge()>=20).collect(Collectors.toList());
System.out.println(res);

我们看一下filter是如何实现元素的过滤的

此处可以看到filter方法接收了Predicate函数式接口。
Predicate函数式接口作用就是对某种数据类型的数据进行判断,结果返回一个boolean值

上面的代码逻辑大致如下:
首先判断predicate是否为null,如果为null,则抛出NullPointerException;
构建Stream,重写opWrapsink方法。
- 参数flags表示下一个sink的标识位,用于优化
- 参数sink将sink构造成单链
此时流已经构建好,但是因为begin()先执行,此时是无法确定流中后续会存在多少元素的,所以传递-1,代表无法确定。最后调用Pridicate中的test,进行条件判断,将符合条件数据放入流中。
distinct:数据去重
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 2, 2, 2, 2);
List<Integer> res=integers.stream().distinct().collect(Collectors.toList());
System.out.println(res);

我们上面实现了对整型数组中的元素去重,其本质是基于LinkedHashSet对流中数据进行去重,并终返回一个新的流。
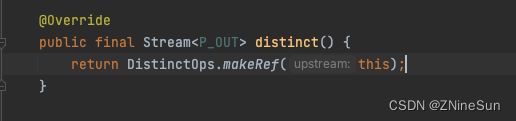
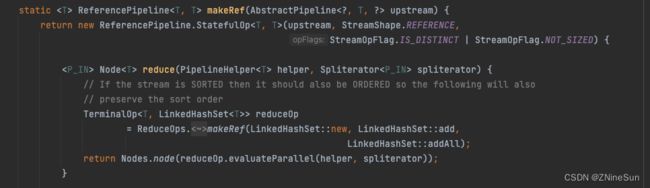
如果我们想通过对象中的某些属性作为判断重复的标准,那么我们仅仅通过distinct方法则难以实现,因为它是基于hashCode()和equals()工作的。
不过我们可以通过其它方法来实现:distinctByKey
public static <T> Predicate<T> distinctByKey(Function<? super T, ?> keyExtractor) {
Map<Object,Boolean> seen = new ConcurrentHashMap<>();
return t -> seen.putIfAbsent(keyExtractor.apply(t), Boolean.TRUE) == null;
}
List<User> res = userList.stream().filter(distinctByKey(b -> b.getAge())).collect(Collectors.toList());
System.out.println(res);
![]()
上面实现了通过年龄去重,如果是多个字段则可以按照下面这种构造实现
List<User> res = userList.stream()
.filter(distinctByKey(b -> b.getAge()))
.filter(distinctByKey(b -> b.getAddress()))
.collect(Collectors.toList());
上面这段代码则实现了通过年龄和地址两个字段进行去重
limit:实现数据的截取
该方法会返回一个不超过给定长度的流
List<User> res = userList.stream().limit(3).collect(Collectors.toList());
获取数组的前3个数据

对于limit方法,它会接收截取的长度,如果该值小于0,则抛出异常,否则会继续向下调用 SliceOps.makeRef()。

该方法中this代表当前流,skip代表需要跳过元素,比方说本来应该有4个元素,当跳过元素 值为2,会跳过前面两个元素,获取后面两个。maxSize代表要截取的长度

在makeRef方法中的unorderedSkipLimitSpliterator()中接收了四个参数Spliterator,skip(跳过个数)、limit(截取 个数)、sizeIfKnown(已知流大小)。
如果跳过个数小于已知流大小,则判断跳过个数是否大于0:
- 如果大于则取截取个数或已知流大小-跳过个数的两者小值
- 否则取已知流大小-跳过个数的结果
最后对集合基于跳过个数和截取个数进行切割。
skip:实现数据的跳过
List<User> res = userList.stream().skip(2).limit(3).collect(Collectors.toList());
System.out.println(res);
表示从集合第3个开始截取,取3个元素

List<User> res = userList.stream().limit(5).skip(2).collect(Collectors.toList());
System.out.println(res);
表示截取前五个元素,然后跳过取出后的前两个元素,从第三个元素开始取

同样,我们看看源码的实现:

在skip方法中接收的n代表的是要跳过的元素个数,如果n小于0,抛出非法参数异常,如果n等于0,则返回当前 流。如果n小于0,才会调用makeRef()。同时指定limit参数为-1.
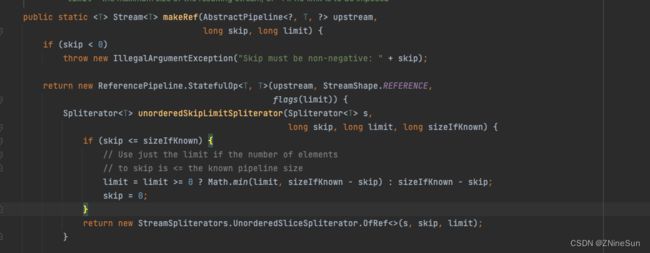
此时可以发现limit和skip都会进入到该方法中,在确定limit值时,如果limit<0,则获取已知集合大小长度-跳过的长度。最终进行数据切割。
map:实现元素的映射
List<String> res = userList.stream().map(User::getName).collect(Collectors.toList());
System.out.println(res);

源码解析:
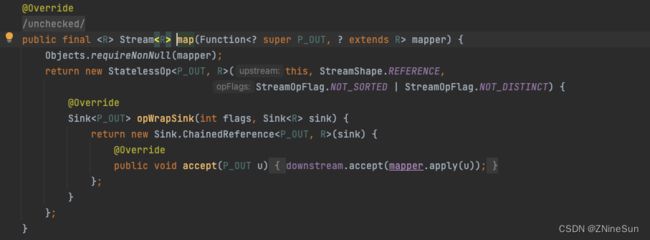
核心则是其内部对Function函数式接口中的apply方法进行实现,接收一个对象,返回另外一个对象,并把这个内容存入当前 流中,然后返回
foreach/find/match:遍历/匹配
Stream也是支持类似集合的遍历和匹配元素的,只是Stream中的元素是以Optional类型存在的。Stream的遍历、匹配非常简单。
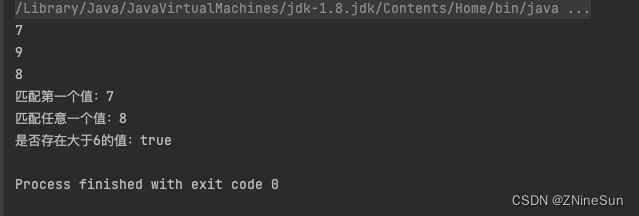
List<Integer> list = Arrays.asList(7, 6, 9, 3, 8, 2, 1);
list.stream().filter(x -> x > 6).forEach(System.out::println);
// 匹配第一个
Optional<Integer> findFirst = list.stream().filter(x -> x > 6).findFirst();
System.out.println("匹配第一个值:" + findFirst.get());
// 匹配任意(适用于并行流)
Optional<Integer> findAny = list.parallelStream().filter(x -> x > 6).findAny();
System.out.println("匹配任意一个值:" + findAny.get());
// 是否包含符合特定条件的元素
boolean anyMatch = list.stream().anyMatch(x -> x > 6);
System.out.println("是否存在大于6的值:" + anyMatch);
同样我们简单的分析一下上面实现的原理
- anyMatch
通过上面的操作可以看出当流中只要有一个符合条件的元素,则会立刻中止后续的操作,立即返回一个布尔值,无需遍历整个流

内部实现会调用makeRef(),其接收一个Predicate函数式接口,并接收一个枚举值,该值代表当前操作执行的是 ANY。

如果predicate.test()抽象方法执行返回值==MatchKind中any的stopOnPredicateMatches,则将stop中断置为true,value 也为true,然后进行返回,无需进行后续的流操作。
reduce:累积求和
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 2, 2, 2, 2);
Integer res = integers.stream().reduce(0,(int1,int2)->int1+int2);
System.out.println(res);
在上述代码中,在reduce里的第一个参数声明为初始值,第二个参数接收一个lambda表达式,代表当前流中的两 个元素,它会反复相加每一个元素,直到流被归约成一个终结果
Integer reduce = integers.stream().reduce(0,Integer::sum);
当然优化成上述所示也可以。
reduce还有一个不带初始值参数的重载方法,但是要对返回结果进行判断,因为如果流中没有任何元素的话,可能就没有结果了。具体方法如下所示
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 2, 2, 2, 2);
Optional<Integer> reduce = integers.stream().reduce(Integer::sum);
if(reduce.isPresent()){
System.out.println(reduce);
}else {
System.out.println("数据有误");
}


在上述方法中,对于流中元素的操作,当执行第一个元素,会进入begin方法,将初始化的值给到state,state就是最后的返回结果。
执行accept方法,对state和第一个元素根据传入的操作,对两个值进行计算。并把终计算结果赋给state。 当执行到流中第二个元素,直接执行accept方法,对state和第二个元素对两个值进行计算,并把终计算结果赋 给state。后续依次类推。
获取流中元素的最大值、最小值
最大值
/**
* 获取集合中的最大值
*/
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 2, 2, 2, 2);
//方法一
Optional<Integer> max1 = integers.stream().reduce(Integer::max);
if (max1.isPresent()) {
System.out.println(max1);
}
//方法二
Optional<Integer> max2 = integers.stream().max(Integer::compareTo);
if (max2.isPresent()) {
System.out.println(max2);
}
/**
* 获取实体列表中的年龄的最大值
*/
Optional<Integer> max11 = userList.stream().map(user -> user.getAge()).reduce(Integer::max);
if (max11.isPresent()) {
System.out.println(max11);
}
Optional<String> max21 = userList.stream().map(user -> user.getAddress()).max(String::compareTo);
if (max11.isPresent()) {
System.out.println(max21);
}
最小值
/**
* 获取集合中的最小值
*/
//方法一
Optional<Integer> min1 = integers.stream().reduce(Integer::min);
if(min1.isPresent()){
System.out.println(min1);
}
//方法二
Optional<Integer> min2 = integers.stream().min(Integer::compareTo);
if(min2.isPresent()){
System.out.println(min2);
}
Collectors:收集器
通过使用收集器,可以让代码更加方便的进行简化与重用。其内部主要核心是通过Collectors完成更加复杂的计算 转换,从而获取到终结果。并且Collectors内部提供了非常多的常用静态方法,直接拿来就可以了。比方说: toList。
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.function.Function;
import java.util.function.Predicate;
import java.util.stream.Collectors;
public class Demo02 {
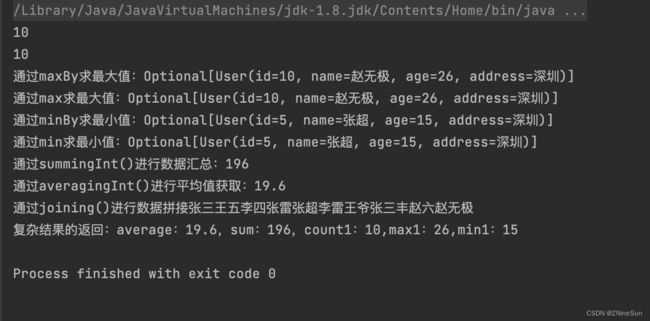
public static void main(String[] args) {
List<User> userList = getUserList();
/**
* 统计集合数
*/
//方法1:counting
Long collect = userList.stream().collect(Collectors.counting());
System.out.println(collect);
//方法2:count()
collect = userList.stream().count();
System.out.println(collect);
/**
* 求最大值
*/
//1.通过maxBy求最大值
Optional<User> collect1 = userList.stream().collect(Collectors.maxBy(Comparator.comparing(User::getAge)));
if (collect1.isPresent()) {
System.out.println("通过maxBy求最大值:" + collect1);
}
//2.通过max求最大值
collect1 = userList.stream().max(Comparator.comparing(User::getAge));
if (collect1.isPresent()) {
System.out.println("通过max求最大值:" + collect1);
}
/**
* 求最小值
*/
//通过minBy求最小值
Optional<User> collect2 = userList.stream().collect(Collectors.minBy(Comparator.comparing(User::getAge)));
if (collect2.isPresent()) {
System.out.println("通过minBy求最小值:" + collect2);
}
//通过min求最小值
Optional<User> min = userList.stream().min(Comparator.comparing(User::getAge));
if (min.isPresent()) {
System.out.println("通过min求最小值:" + min);
}
/**
* 通过summingInt()进行数据汇总
*/
Integer collect3 = userList.stream().collect(Collectors.summingInt(User::getAge));
System.out.println("通过summingInt()进行数据汇总:" + collect3);
/**
* 通过averagingInt()进行平均值获取
*/
Double collect4 = userList.stream().collect(Collectors.averagingInt(User::getAge));
System.out.println("通过averagingInt()进行平均值获取:" + collect4);
/**
* 通过joining()进行数据拼接
*/
String collect5 = userList.stream().map(User::getName).collect(Collectors.joining());
System.out.println("通过joining()进行数据拼接" + collect5);
/**
* 复杂结果的返回
*/
IntSummaryStatistics collect6 = userList.stream().collect(Collectors.summarizingInt(User::getAge));
double average = collect6.getAverage();
long sum = collect6.getSum();
long count1 = collect6.getCount();
int max1 = collect6.getMax();
int min1 = collect6.getMin();
System.out.println("复杂结果的返回:average:" + average + ",sum:" + sum + ",count1:" + count1 + ",max1:" + max1 + ",min1:" + min1);
}
private static List<User> getUserList() {
List<User> userList = new ArrayList<>();
userList.add(new User(1, "张三", 18, "上海"));
userList.add(new User(2, "王五", 16, "上海"));
userList.add(new User(3, "李四", 20, "上海"));
userList.add(new User(4, "张雷", 22, "北京"));
userList.add(new User(5, "张超", 15, "深圳"));
userList.add(new User(6, "李雷", 24, "北京"));
userList.add(new User(7, "王爷", 21, "上海"));
userList.add(new User(8, "张三丰", 18, "广州"));
userList.add(new User(9, "赵六", 16, "广州"));
userList.add(new User(10, "赵无极", 26, "深圳"));
return userList;
}
}
分组
在数据库操作中,经常会通过group by对查询结果进行分组。同时在日常开发中,也经常会涉及到这一类操作, 如通过性别、地址等对用户集合进行分组。
如果通过普通编码的方式需要编写大量代码且可读性不好,对于这个问题的解决,java8也提供了简化书写的方式。通过 Collectors。groupingBy()即可。
Map<String, List<User>> collect = userList.stream().collect(Collectors.groupingBy(User::getAddress));
Set<String>keys=collect.keySet();
for (String key:keys){
System.out.println(key+"->"+collect.get(key));
}

多级分组
刚才已经使用groupingBy()完成了分组操作,但是只是通过单一的属性值进行分组,那现在如果需求发生改变,还要按照年龄进行分组的话,我们同样也可以利用groupingBy()方法进行实现,对于groupingBy()它提供了两个参数的重载方法,用于完成这种需求。
这个重载方法在接收普通函数之外,还会再接收一个Collector类型的参数,其会在内层分组(第二个参数)结果,传 递给外层分组(第一个参数)作为其继续分组的依据。
Map<String, Map<Integer, List<User>>> collect1 = userList.stream().collect(Collectors.groupingBy(User::getAddress, Collectors.groupingBy(User::getAge)));
System.out.println(collect1);
![]()
看到此处,想必你对stream的功能和用法已经掌握了,自己可以尝试着去优化一下自己之前写的代码,让你的代码风格更加优雅。
相关文章推荐:
- 《Optional的使用详解》