正则表达式详解[C#]
正则表达式常用功能:匹配,捕获,替换。匹配是基础,捕获是关键,替换就是在前面基础上调整一下位置。
[url重写:正则表达式替换]
1 string lookFor="^~/root/(\w{1,20})/somepage/(\d{1,8})/(\w)*?/(\d{1,8}).aspx$" 2 string SendTo="~/root/$1/somepage.aspx?categoryid=$2&pageindex=$4"; 3 var regex = new Regex(lookFor, RegexOptions.IgnoreCase); 4 if (regex.IsMatch(oldurl)) 5 { 6 string newurl=regex.Replace(oldurl,SendTo); 7 }
替url添加一些过滤条件或限制条件,过滤同级的页面,避免冲突:
url Partten output 描述
/(abc|service)partner$ /partners/$1 (A|B)表示选择A或B
/support/((?!courses|search|thankyou)[^/]+)$ /support/faqs/$1 (?!A|B|C)表示排除A,B,C
[替换中的 特殊正则表达式符号]
1 Console.WriteLine(Regex.Replace("$$$1.30", @"(\$*(\d*(\.+\d+)?){1})", 2 "[$&}\"", RegexOptions.IgnoreCase));// $& 替换整个匹配项的一个副本。 3 Console.WriteLine(Regex.Replace("gggAAAB,BCCDD", @"(?<A3>A+)B+(?<dot>,)B+", 4 "((所有输入的文本:$_ ,匹配前的文本:$`,匹配后的文本:$',名字为A3捕获的内容:'${A3}'," 5 +"第二个捕获组的内容:'$2', 最后捕获的组:'$+',美元符号:$$.))", RegexOptions.IgnoreCase)); 6 //如果匹配组中有一个是命名方式 那么最后一个 即是最后一个命名的组

[获取百度|谷歌搜索每页的快照跟Title所对应的Url:正则表达式多个匹配]
1 const string Snapshot_UrlExpression = "<a[^>]*href=[\"']?([^>\"'\\s]+)[\"']?[^>]*>[\u4e00-\u9fa5]*快照</a>"; 2 const string Title_UrlExpress ="<h3[^>]*class=\"[rt]\"[^>]*><a[^>]*href=[\"']?([^>\"'\\s]+)[\"']?[^>]*>[\\.\\n\u0000-\uffff]*</a></h3>"; 3 4 Regex Snapshot_UrlReg = new Regex(Snapshot_UrlExpression, RegexOptions.ECMAScript | RegexOptions.Compiled); 5 Regex Title_UrlReg = new Regex(Title_UrlExpress, RegexOptions.ECMAScript | RegexOptions.Compiled); 6 7 public List<string> Urls2Snapshot() 8 { 9 List<string> urllist = new List<string>(); 10 MatchCollection collection = Snapshot_UrlReg.Matches(Content); 11 foreach (Match m in collection) 12 urllist.Add(m.Groups[1].Value); 13 return urllist; 14 } 15 public List<string> Urls2Title() 16 { 17 List<string> urllist = new List<string>(); 18 MatchCollection collection = Title_UrlReg.Matches(Content); 19 foreach (Match m in collection) 20 urllist.Add(m.Groups[1].Value); 21 return urllist; 22 }
[小结]
定位控制符(6个):\,^,$,\b,\B,\cx
量词(6个): *,+,?,{n},{n,},{n,m}
名词(6个):\d,\D,\w,\W,\s,\S
谓词(6个):获取匹配[(pattern)]:匹配结果保存在Matches集合中,反之则不保存.
非获取匹配[(?:pattern),预查操作 (?=pattern),(?!pattern),(?<=pattern),(?<!pattern) ]
预查指的是匹配的指针不消耗字符,预查部分是已经匹配的或下一次匹配的
副词(?):?用在量词的后边修饰,代表非贪心匹配,例如<h5>wang</h5>使用<.*>将匹配整个,而<.*?>只匹配<h5>
等价:\d=[0-9],\D=[^\d],\w=[a-zA-Z0-9_],\W=[^\w],\s=[\f\n\r\t\v],\S=[^\s],.=[^\n],[.\n]=[\s\S]
转义值:\xn(两位十六进制:ASCII),\un(四位十六进制:Unicode),
\n(如果在此其有n个子表达式则为匹配的引用,否则为八进制的转义字符
中括号使用:A.连字符"-",开始字符值小于连字符,而结束字符值等于或大于连字符:例如[!--] [!-~]
B.匹配连字符"-",需要转义"\-",如果出现在列表的开始或结尾,则代表它本身,不需要转义.(例如[-a-z] [a-z-]代表小写字母和连字符)
C.插入符"^",须放在列表的开头。如果插入字符出现在列表中的其他任何位置,则它匹配其本身,这里不需要转义就代表它本身.
特殊字符(需要转义的14-15个):*,+,?,{,},[,],(,),^,$,.,|,\
1 static void Main(string[] args) 2 { 3 string Content = "123windows126windows128windowsNT"; 4 string regExpress = @"\d*(\w+?(?=dow|NT))"; //(?=pattern) 零宽度正预测先行断言。 5 6 string regExpress3 = @"((?<=\d+)[a-zA-Z]+)[\d]*";//(?<=pattern) 零宽度正回顾后发断言。 7 string regExpress4 = @"\d+([a-zA-Z]+)[\d]+"; 8 9 string Content2 = "123nnnww789mmmttuuvv"; 10 string regExpress2 = @"\d*(\w)\1\1"; //\n 11 string regExpress22 = @"\d*(?<double>\w)\k<double>\k<double>"; //功能跟regExpress2相同,用命名方式,优先级高 12 13 Regex reg = new Regex(regExpress, RegexOptions.ECMAScript | RegexOptions.Compiled); 14 MatchCollection collection = reg.Matches(Content); 15 foreach (Match m in collection) 16 Console.WriteLine(m.Groups[0].Value+":"+m.Groups[1].Value); 17 18 Console.WriteLine(); 19 Regex reg2 = new Regex(regExpress2, RegexOptions.ECMAScript | RegexOptions.Compiled); 20 MatchCollection collection2 = reg2.Matches(Content2); 21 foreach (Match m in collection2) 22 Console.WriteLine(m.Groups[0].Value+":"+m.Groups[1].Value); 23 24 Console.WriteLine(); 25 Regex reg3 = new Regex(regExpress3, RegexOptions.ECMAScript | RegexOptions.Compiled); 26 MatchCollection collection3 = reg3.Matches(Content); 27 foreach (Match m in collection3) 28 Console.WriteLine(m.Groups[0].Value + ":" + m.Groups[1].Value); 29 30 31 Console.WriteLine(); 32 Regex reg4 = new Regex(regExpress4, RegexOptions.ECMAScript | RegexOptions.Compiled); 33 MatchCollection collection4 = reg4.Matches(Content); 34 foreach (Match m in collection4) 35 Console.WriteLine(m.Groups[0].Value + ":" + m.Groups[1].Value); 36 37 Console.ReadKey(); 38 }
![正则表达式详解[C#]](http://img.e-com-net.com/image/product/f5fe7d101e2445b09f37556f6e0c23b7.png)
[替换匹配构造]针对不同的匹配结果,再选择一个子匹配.
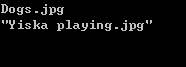
1 static void Region() 2 { 3 string Content = @"Dogs.jpg ""Yiska playing.jpg"""; //如果不包含双引号就是用第二个匹配方案 4 string regExpress = @"(?<quoted>"")?(?(quoted).+?""|\S+\s)"; //定义捕获名 (?<quoted>"")? 5 string regExpress2 = @"(?("").+?""|\S+\s)"; //两个匹配结果一样 6 7 Regex reg = new Regex(regExpress, RegexOptions.ECMAScript | RegexOptions.Compiled); 8 MatchCollection collection = reg.Matches(Content); 9 foreach (Match m in collection) 10 Console.WriteLine(m.Value); 11 }
[常用正则表达式]
邮箱地址:邮箱地址名+@+邮件服务商域名+域名商域名(有可能是多级域名)
电子邮件地址只能包含字母、数字、句点(.)、连字符(-)和下划线(_)。域名包含字母、数字、连字符(-)、不同级域名间用点号(.)(例如.com.cn)
所以:Email:@"^[a-z0-9A-Z]+[\w\-\.]*@[a-z0-9\-]+(?>\.\w+){1,4}$";
无嵌套的Html: <\s*(\S+)(\s[^>]*)?>[\s\S]*<\s*\/\1\s*>|<\s*(\S+)(\s[^>]*)?\/>
[C#]http://msdn.microsoft.com/zh-cn/library/vstudio/az24scfc.aspx#character_classes
[js] http://msdn.microsoft.com/zh-cn/library/yhzf4dct%28v=vs.80%29.aspx