从RNN到Attention到Transformer-LSTM介绍
深度学习知识点总结
专栏链接:
深度学习知识点总结_Mr.小梅的博客-CSDN博客本专栏主要总结深度学习中的知识点,从各大数据集比赛开始,介绍历年冠军算法;同时总结深度学习中重要的知识点,包括损失函数、优化器、各种经典算法、各种算法的优化策略Bag of Freebies (BoF)等。
本章介绍LSTM及其手动计算过程。
从RNN到Attention到Transformer系列文章RNN系列-RNN介绍、手动计算验证_Mr.小梅的博客-CSDN博客
目录
3.2 LSTM
3.2.1 LSTM介绍
3.2.2 分步 LSTM 演练
3.2.3 PyTorch中LSTM的计算
3.2.4 LSTM变形-加入peepholes (窥视孔)
3.2.5 LSTM变形-忘记门和输入门使用耦合的LSTM
3.2.6 LSTM变形-GRU
3.2 LSTM
3.2.1 LSTM介绍
长短期记忆网络 - 通常简称为“LSTM” - 是一种特殊的RNN,能够学习长期依赖关系。它们由Hochreiter&Schmidhuber(1997)引入,并在随后的工作中被许多人改进和推广。它们在各种各样的问题上都非常出色,现在被广泛使用。
LSTM 是显式设计的,以避免长期依赖关系问题。长时间记住信息实际上是他们的默认行为,而不是他们努力学习的东西!
所有递归神经网络都具有神经网络重复模块链的形式。在标准RNN中,这个重复模块将具有非常简单的结构,例如单个tanh层。
 标准 RNN 中的重复模块包含单个层
标准 RNN 中的重复模块包含单个层
LSTM也具有这种链状结构,但重复模块具有不同的结构。不是一个神经网络层,而是有四个,以一种非常特殊的方式进行交互。
 LSTM 中的重复模块包含四个交互层
LSTM 中的重复模块包含四个交互层

在上图中,每条线都携带一个完整的向量,从一个节点的输出到其他节点的输入。粉红色圆圈表示逐点操作,如矢量加法,而黄色框是学习的神经网络层。行合并表示串联,而行分叉表示其内容被复制,副本转到不同的位置。
LSTM 背后的核心思想:
LSTM 的关键是单元状态,即贯穿图顶部的水平线。
单元状态有点像传送带。它直接沿着整个链条运行,只有一些小的线性相互作用。信息很容易沿着它原封不动地流动。

LSTM确实能够去除或向细胞状态添加信息,由称为门的结构仔细调节。门是一种选择性地让信息通过的方法。它们由sigmoid神经网络层和逐点乘法运算组成。
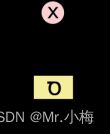
Sigmoid层输出0到1之间的数字,描述每个组件应允许通过多少。值为0表示“不让任何内容通过”,而值为 1 表示“让一切通过!”
LSTM具有三个这样的门,以保护和控制细胞状态。
3.2.2 分步 LSTM 演练
忘记门:
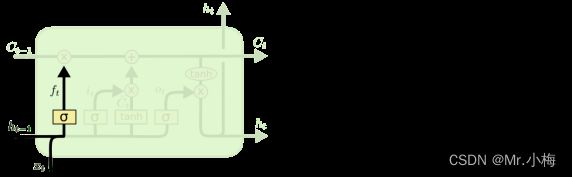
LSTM的第一步是决定要从细胞状态中丢弃哪些信息。这个决定是由一个叫做“忘记门”的sigmoid层做出的。把它看成是ht−1和xt断续器,并输出一个介于0和1对于cell状态,1表示“完全保留此”,而0代表“完全摆脱这个”。
拿语言模型示例,该示例试图根据所有以前的单词预测下一个单词。在这样的问题中,单元格状态可能包括当前主语的性别,以便可以使用正确的代词。当我们看到一个新主题时,我们想要忘记旧主题的性别。
输入门:
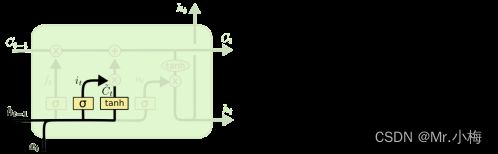
下一步是确定要在cell状态中存储哪些新信息。这分为两部分。首先,称为“输入门”的 sigmoid 层决定了我们将更新哪些值。接下来,tanh 图层创建新候选值的向量~Ct,将其添加到状态中。在下一步中,我们将这两者结合起来,以创建对状态的更新。
例如在语言模型示例中,我们希望将新主题的性别添加到cell状态中,以替换我们忘记的旧主题。
更新状态:

现在是时候更新旧的cell状态了Ct−1,进入新的cell状态Ct断续器.前面的步骤已经决定了要做什么,我们只需要实际去做。
我们将旧状态乘以ft断续器,忘记了我们之前决定忘记的事情。然后我们添加我it∗Ct.这是新的候选值,按我们决定更新每个状态值的程度进行缩放。
在语言模型的情况下,这是我们实际上删除有关旧主题性别的信息并添加新信息的地方,正如我们在前面的步骤中决定的那样。
输出门:
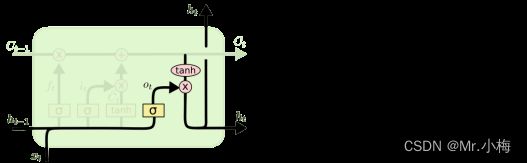
最后,我们需要决定要输出的内容。此输出将基于我们的cell状态,是经过筛选的版本。首先,我们运行一个sigmoid层,它决定了我们要输出的细胞状态的哪些部分。然后,我们将cell状态通过tanh(将值推送到介于−1和1),并将其乘以 sigmoid 栅极的输出,以便我们只输出我们决定输出的部分。
对于语言模型示例,由于它只看到了一个主题,因此它可能希望输出与动词相关的信息,以防万一这是接下来要执行的内容。例如,它可能会输出主语是单数还是复数,如果这是接下来的内容,以便我们知道动词应该以什么形式共轭。
汇总:

3.2.3 PyTorch中LSTM的计算
CLASS torch.nn.LSTM(*args, **kwargs)

初始化LSTM所需参数:
Parameters:
-
input_size – 输入x的特征数,例如每句话中每个单词的特征数
-
hidden_size – 隐藏层特征数,一般就是RNN输出的特征数
-
num_layers – 隐藏层层数,默认为1
-
nonlinearity – 非线性函数 'tanh' or 'relu'. Default: 'tanh'
-
bias – 是否使用bias( b_ih and b_hh). Default: True
-
batch_firsts – 如果设置为True的话,输入batchsize放到前面,Default: False
-
dropout – Default: 0
-
bidirectional – 设置为True变成双向RNN Default: False
-
proj_size – 如果大于0,将使用具有相应大小投影的LSTM,Default: 0
使用LSTM时的输入参数:
Inputs: input, h_0
-
input: batch_first=False时尺寸为(L,N,Hin )batch_first=True时尺寸为(N, L, H_{in})
-
h_0:输入尺寸为(D∗num_layers,N,H_out) ,不输入时默认为0。
-
c_0:输入尺寸为(D∗num_layers,N,H_cell) ,不输入时默认为0。
LSTM的输出:
Outputs: output, h_n
- output:当batch_first=False时输出尺寸为(L, N, D * H_{out});当batch_first=True时输出尺寸为(N, L, D * H_{out})
-
h_n:(D∗num_layers,N,Hout) 各个隐藏状态参数
-
c_n:(D∗num_layers,N,Hcell) 各个cell状态参数
以上各个字母的解释:
-
N=batch size
-
L=sequence length输入序列的长度
-
D=2 if bidirectional=True otherwise 1
-
H_in =input_size输入特征长度
-
H_cell =hidden_size cell特征长度
-
H_out =proj_size if proj_size >0 else hidden_size输出特征长度
RNN中可训练的参数
-
LSTM.weight_ih_l[k] – 第k层输入层-隐藏层权重(W_ii|W_if|W_ig|W_io),k = 0时shape=(4*hidden_size, input_size) ,k>0时shape=(4*hidden_size,num_directions * hidden_size)
-
LSTM.weight_hh_l[k] – 第k层隐藏-隐藏层权重(W_hi|W_hf|W_hg|W_ho),shape=(4*hidden_size, hidden_size)
-
LSTM.weight_hr_l[k] – proj_size大于0时存在,shape=(proj_size, hidden_size)
-
LSTM.bias_ih_l[k] – 第k层输入层-隐藏层bias(b_ii|b_if|b_ig|b_io),shape=(4*hidden_size)
-
LSTM.bias_hh_l[k] – 第k层隐藏-隐藏层bias(b_hi|b_hf|b_hg|b_ho),shape=(4*hidden_size)
所有可训练参数初始化范围(-sqrt(k),sqrt(k)),k=1/(hidden_size)
3.2.4 LSTM变形-加入peepholes (窥视孔)
由Gers& Schmidhuber(2000)引入的一个流行的LSTM变体正在添加“窥视孔连接”。这意味着我们让栅极层查看单元状态。

上图为所有门添加了窥视孔,但许多论文会给出一些窥视孔,而不是其他窥视孔。
另一种变体是使用耦合的忘记和输入门。我们不是单独决定忘记什么以及应该添加新信息,而是一起做出这些决定。我们只会忘记何时要在它的位置上输入一些东西。只有当我们忘记了旧的东西时,我们才会向状态输入新的值。
3.2.5 LSTM变形-忘记门和输入门使用耦合的LSTM
另一种变体是使用耦合的忘记和输入门。我们不是单独决定忘记什么以及应该添加新信息,而是一起做出这些决定。我们只会忘记何时要在它的位置上输入一些东西。只有当我们忘记了旧的东西时,我们才会向状态输入新的值。
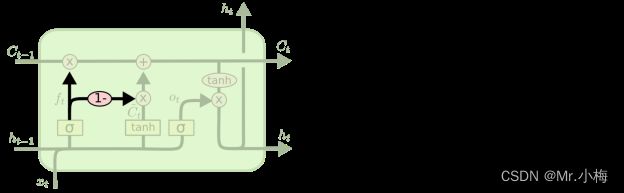
3.2.6 LSTM变形-GRU
LSTM的一个稍微戏剧性的变化是由Cho等人(2014)引入的Gated Recurrent Unit或GRU。它将忘记和输入门组合成一个“更新门”。它还合并单元格状态和隐藏状态,并进行一些其他更改。由此产生的模型比标准LSTM模型更简单,并且越来越受欢迎。

LSTM 是我们使用 RNN 所能实现的一大步。人们很自然地想知道:还有一大步吗?研究人员的普遍看法是:“是的!还有下一步,那就是Attention!这个想法是让RNN的每个步骤从一些更大的信息集合中选择要查看的信息。例如,如果使用 RNN 创建描述图像的标题,则它可能会为输出的每个单词选取图像的一部分进行查看
在介绍Attention之前,先了解下Decode-Encode原来。