分布式文件管理系统HDFS
1.HDFS(Hadoop Distributed File System )分布式文件管理系统
1.1.1 概述
在现代的企业环境中,单机容量往往无法存储大量数据,需要跨机器存储。统一管理分布在集群上的文件系统称为分布式文件系统 。
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目. Hadoop 非常适于存储大型数据 (比如 TB 和 PB), 其就是使用 HDFS 作为存储系统. HDFS 使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统.
分布式文件系统解决的问题就是大数据存储。它们是横跨在多台计算机上的存储系统。分布式文件系统在大数据时代有着广泛的应用前景,它们为存储和处理超大规模数据提供所需的扩展能力。
设计目标:
1:HDFS可以解决硬件故障问题,通过副本机制
2:不适合和用户实时交互,适合大数据量存储
3:HDFS合适存大文件,不适合存小文件
4:HDFS的文件数据,一旦写入,不要修改,HDFS理论上只支持追加写入,不支持随机修改
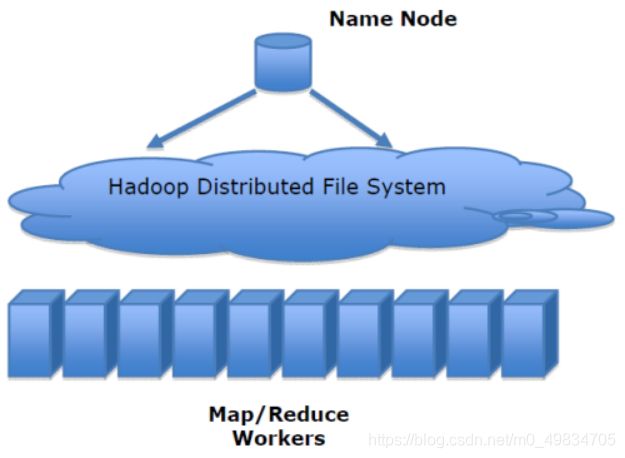
1.1.2 架构(掌握)
HDFS:Hadoop Distributed File System 分布式文件管理系统
一个文件(不管大小为 1k 还是 1T) 占 150字节
架构: 主从架构,一旦主节点挂了,将无法工作.
架构组件:
Client
1:对上传文件进行切片,每片128M
2:当客户端要上传或者下载文件时,先要和和NameNode进行交互
3:具体的文件上传和下载的操作是需要和DataNode之间进行交互
4:客户端需要提供一些命令:hadoop fs -put
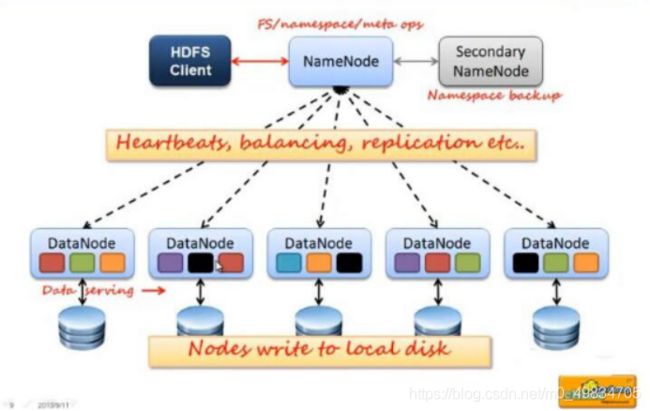
NameNode
1:是HDFS的主节点,管理元数据信息
2:Name可以对外将每个文件都封装一个路径,用户只要访问这个路径就能下载该文件
3:管理每一个Block块所在的主机列表
4:管理副本策略,NameNode用来决定每一个副本都放在哪一台主机
DataNode
1:是HDFS从节点
2:DataNode存储具体的数据
3:执行具体的数据读写操作
4: 定时向NameNode汇报Block块信息
SecondaryNameNode
帮助NameNode管理元数据
1.1.3 HDFS的副本机制
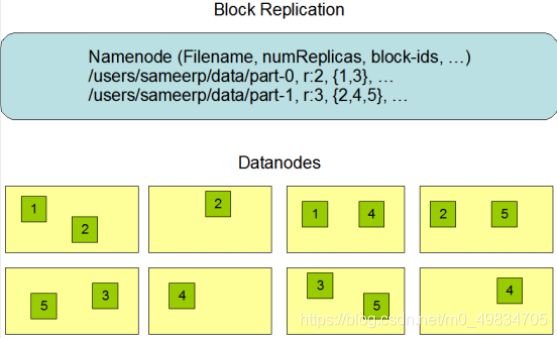
HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件存储成一系列的数据块,这个数据块被称为block,除了最后一个,所有的数据块都是同样大小的。
为了容错,文件的所有block都会有副本。每个文件的数据块大小和副本系数都是可配置的。
所有的文件都是以 block 块的方式存放在 HDFS 文件系统当中,作用如下
1、一个文件有可能大于集群中任意一个磁盘,引入块机制,可以很好的解决这个问题
2、使用块作为文件存储的逻辑单位可以简化存储子系统
3、块非常适合用于数据备份进而提供数据容错能力
4、副本优点是安全,缺点是占空间。
(要理解掌握哦):
1.每一个文件上传时都会被切成很多个block(块),每一个block最多
是128M,最少1个字节,设置在hdfs.site.xml中.
2. block只是一个逻辑单位,不够128M也算是一个block.
3. 每一个block副本数默认为3,设置在 hdfs-site.xml中.
(cd /export/server/hadoop-2.7.5/etc/hadoop/;
vim hdfs-site.xml)
例如一个 300M的文件上传到HDFS 会有3个Block
一个 100M的文件上传到HDFS 只有1个Block 但是都有3个副本(每一个主机上一个)
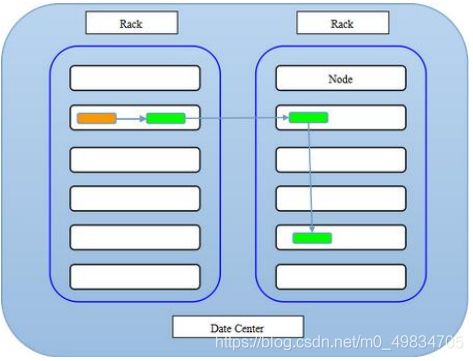
1.1.4 HDFS副本放置策略(机架感知)
HDFS分布式文件系统的内部有一个副本存放策略,默认副本数为3,在这里以副本数=3为例:
第一副本:优先放置到离写入客户端最近的DataNode节点,如果上传节点就是DataNode,则直接上传到该节点,如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
第二个副本:放置在于第一个副本不同的机架的节点上(随机选择)
第三个副本:与第二个副本相同机架的不同节点中。
2 .HDFS的Shell命令行使用
2.1.1 Shell命令行客户端
HDFS是存取数据的分布式文件系统,那么对HDFS的操作,就是文件系统的基本操作,比如文件的创建、修改、删除、修改权限等,文件夹的创建、删除、重命名等。对HDFS的操作命令类似于Linux的shell对文件的操作,如ls、mkdir、rm等。
(要理解掌握哦):
HDFS的shell命令操作:
-ls:
1.hadoop fs -ls / 显示 hdfs 下的 / 的文件列表
2.hadoop fs -lsr / 递归显示 会出现已经过时
3.hadoop fs -ls -R 递归显示 新的写法
-mkdir:
1.hadoop fs -mkdir /aaa 创建文件夹
2.hadoop fs -mkdir -p /aaa/bbb/ccc 递归创建
-put 上传(复制 上传本地不会消失):
1.hadoop fs -put a.txt(目录或者文件名字) /
-moveFromLocal类似put (剪切 上传本地会消失):
1.hadoop fs -moveFromLocal a.txt / (了解)
-get: 从HDFS下载文件到本地
1.hadoop fs -get /a.txt /root(目标路径)
ll -lh(linux中) : 查看文件大小
-mv: HDFS文件之间的移动
1.hadoop fs -mv /a.txt(文件路径) /aaa(目标路径)
-rm: 删除 HDFS上的文件
1.hadoop fs -rm /a.txt 实际是移动到了回收站 指定时间可以恢复(我设置的7天)
2.hadoop fs -rm -r -skipTrash /ccc/ddd/ffff 递归删除
-cp: 文件在HDFS上复制
1.hadoop fs -cp /a.txt /aaa/bbb/ccc
-cat: 显示HDFS文件的内容
1.hadoop fs -cat /a.txt
-du: 显示文件或者文件夹大小
1.hadoop fs -du /
-chmod: 修改HDFS文件权限
1.hadoop fs -chmod 777 /a.txt
-chown: 改变HDFS所属用户和所属用户组
先创建用户: useradd liuafu
设置用户密码: passwd 123456
创建新的用户组: groupadd bigdata
将a.txt的用户和用户组设置成 liuafu:bigdata
1.hadoop fs -chown liuafu:bigdata /a.txt
-appendToFile: 将本地小文件合并成大文件 上传到HDFS
1.hadoop fs -appendToFile *.txt /a.txt
2.1.2 HDFS的原理
1:NameNode内存的容量决定了整个HDFS集群的规模
64G的内容理论上,HDFS可以存放4亿个文件
2:DataNode是存放具体的文件数据,存放的路径是由hdfs-site.xml来设置
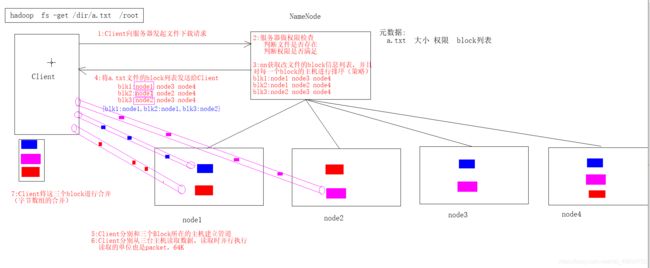
2.1.2 HDFS的读写流程(掌握)
写流程: 顺序写

读流程: 并发读
3. HDFS的其他功能(掌握)
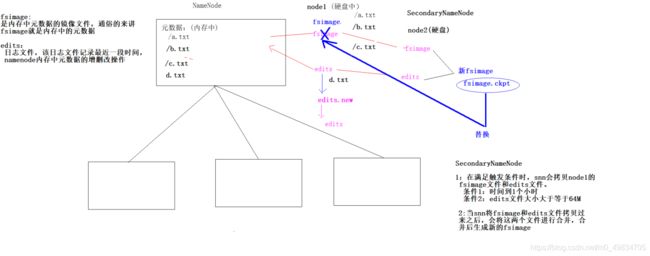
3.1 HDFS的元数据管理
3.2 Archive归档
意义:
1:HDFS不适合小文件存储,因为每个小文件都需要占用一条元数据
2:如何处理这些小文件,最理想的办法是将这些小文件进行归档
3:归档之后,我们既可以访问其中每一个小文件,又使这个归档文件只占用一条元数据
4:以后我们还可以解压归档文件
具体操作:
命令: hadoop archive -archiveName test.har -p /config/outputdir
解释:
hadoop archive -archiveName 固定写法;
test.har 归档名字 随意 .har结尾
-p /config 要将哪一个文件归档 名字随意
/outputdir 归档后存在哪一个目录 名字随意
具体步骤:
1. 将hadoop配置文件的xml都上传到aaa文件夹
hadoop fs -put *.xml /aaa #*.xml代表所有以xml结尾的文件
2. 将aaa文件夹下的所有小文件进行归档
hadoop archive -archiveName ach.har -p /aaa /outputdir
此时aaa 文件夹可以删除了 因为已经归档 占空间.
3: 查看归档文件中的所有小文件名字
hadoop fs -ls har://hdfs-afu01:8020/outputdir/ach.har
4. 查看归档文件中某一个小文件的具体内容:
hadoop fs -cat har://hdfs-afu01:8020/outputdir/ach.har/a.txt
或者
hadoop fs -cat har:///outputdir/ach.har/core-site.xml
5. 解压归档文件:
5.1 在HDFS的/创建一个文件夹:
hadoop fs -mkdir /input
5.2 开始解压:
hadoop fs -cp har:///outputdir/ach.har/* /input
3.3 HDFS的快照功能
意义: 快照可以帮助我们恢复原来目录文件的状态
1、开启指定目录的快照功能
hdfs dfsadmin -allowSnapshot 路径
2、禁用指定目录的快照功能(默认就是禁用状态)
hdfs dfsadmin -disallowSnapshot 路径
3、给某个路径创建快照snapshot
hdfs dfs -createSnapshot 路径
4、恢复快照
hdfs dfs -cp -ptopax 快照路径 恢复路径
5、删除快照snapshot
hdfs dfs -deleteSnapshot <path> <snapshotName>
具体操作:
1. 开启允许快照的功能:
hdfs dfsadmin -allowSnapshot /input
2. 拍快照
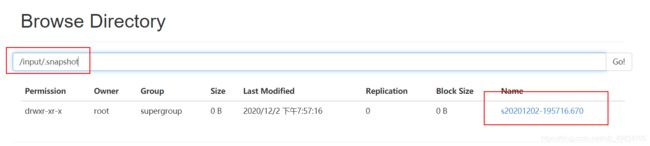
hdfs dfs -createSnapshot /input
拍的快照会被保存在HDFS的.snapshot目录下,该目录为隐藏目录 看不见的
3. 恢复快照
hdfs dfs -cp -ptopax /input/.snapshot /input1
4. 删除快照
hdfs dfs -deleteSnapshot <path> <snapshotName>