HDFS 分布式文件系统
目录
1,Hadoop 是什么?------分布式文件系统架构 (核心是HDFS 和 MapReduce)
2,HDFS 是什么?--------分布式文件系统
1, 计算机集群 与 分布式文件系统?
2,节点:
3,HDFS 采用块的概念:
4,通信协议:
5,HDFS编程实践:
1,Hadoop 是什么?------分布式文件系统架构 (核心是HDFS 和 MapReduce)
2,HDFS 是什么?--------分布式文件系统
1, 计算机集群 与 分布式文件系统?
【物理结构】~【计算机集群】: 分布式文件系统把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群。
【逻辑结构】~ 【分布式文件系统】:分布式文件系统在物理结构上是由计算机集群中的多个节点构成的。
2,节点:
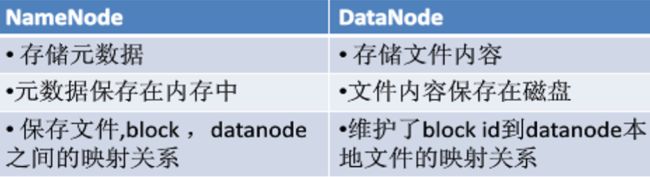
● 主节点(NameNode):名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问。
【与从节点关系】: 记录了每个文件中各个块所在的数据节点的位置信息;
● 从节点(DataNode):负责处理文件系统客户端的读/写请求,
【与 主节点关系】负责数据的存储和读取,在名称节点的统一调度下进行数据块的创建、删除和复制等操作。
ps:一般,一个数据节点运行一个数据节点的进程。而且定期向名称节点发送自己所存储的块的列表。
每个数据节点的数据实际上是保存在本地Linux文件系统中的。
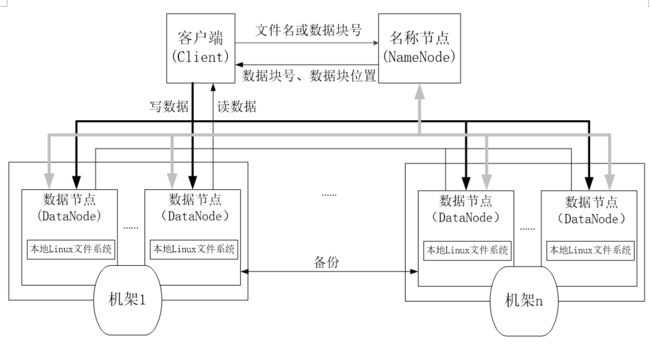
3,HDFS 采用块的概念:
- 简化了存储管理: 因为文件块大小是固定的,这样就可以很容易计算出一个节点可以存储多少文件块;
- 方便了元数据的管理,元数据不需要和文件块一起存储,可以由其他系统负责管理元数据.
4,通信协议:
- HDFS是一个部署在集群上的分布式文件系统,因此,很多数据需要通过网络进行传输
- 所有的HDFS通信协议都是构建在TCP/IP协议基础之上的
- 【客户端与名称节点】:
- 客户端通过一个可配置的端口向名称节点主动发起TCP连接,并使用客户端协议与名称节点进行交互
- 【客户端与数据节点】客户端与数据节点的交互是通过RPC(Remote Procedure Call)来实现的。在设计上,
名称节点不会主动发起RPC,而是响应来自客户端和数据节点的RPC请求
~~~~~~~~~~~~~~~~~模型~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
客户端 “发送数据包”
-》 服务器(名称节点)~监听到当前活跃的客户端~传入客户端处理器
-》 客户端处理器(数据节点)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
ps:客户端:可以支持打开、读取、写入等常见的操作, 并且提供了类似Shell的命令行方式来访问HDFS中的数据。 此外,HDFS也提供了Java API,作为应用程序访问文件系统的客户端编程接口。
5,HDFS编程实践:
背景: Hadoop提供了关于HDFS在Linux操作系统上进行文件操作的常用Shell命令以及Java API。同时还可以利用Web界面查看和管理Hadoop文件系统。 备注:Hadoop安装成功后,已经包含HDFS和MapReduce,不需要额外安装。而HBase等其他组件,则需要另外下载安装。
在学习HDFS编程实践前,我们需要启动Hadoop。执行如下命令:(之前格式化了,第二条格式的命令就不要执行了,否则如果出现了bug:
WARN hdfs.DFSClient: DataStreamer Exception org.apache.hadoop.ipc.RemoteException问题)

ps:WARN hdfs.DFSClient: DataStreamer Exception org.apache.hadoop.ipc.RemoteException问题 的解决:
■ 前提:切换到hadoop安装目录;
① 停止集群:
./sbin/stop-all.sh② 删除在core-site.xml中配置的hadoop.tmp.dir 对应的目录,例如配置时是:
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
那么删除命令:
rm -rf /usr/local/hadoop/tmp/dfs/name③ 重新格式化namenode,然后执行命令:
./bin/hadoop namenode -format④ 重新启动hadoop集群:
./sbin/start-all.sh参考文章:《Hadoop解决WARN hdfs.DFSClient: DataStreamer Exception org.apache.hadoop.ipc.RemoteException问题》
Hadoop解决WARN hdfs.DFSClient: DataStreamer Exception org.apache.hadoop.ipc.RemoteException问题_好吗好的~的技术博客-CSDN博客