数据分析 | Pandas 200道练习题,每日10道题,学完必成大神(7)
文章目录
-
- 前期准备
- 1. 以df的列名创建一个DataFrame
- 2. 打印所有换手率为非数字的行
- 3. 删除所有换手率为非数字的行
- 4. 重置df的行号
- 5. 绘制‘还手’密度曲线
- 6. 计算后一天和前一天收盘价的差值
- 7. 计算后一天与前一天收盘价的变化率
- 8. 设置时间索引
- 9. 使用时间索引,分别按年份,月份取值
- 10. 以5个数据作为数据滑动窗口 在这5个数据上取均值(收盘价)
本章使用还是金融数据集,不仅回顾的旧的知识点,还拓展了一些新的内容,主要的难点在于重置索引
reset_index(),计算一列的差分diff(),时间索引的操作,滑动窗口的使用rolling()
前期准备
import pandas as pd
import numpy as np
# 导入绘图工具
from matplotlib import pyplot as plt
# 使图形中的中文正常编码显示
plt.rcParams['font.sans-serif'] = ['SimHei']
# 使坐标轴刻度表签正常显示正负号
plt.rcParams['axes.unicode_minus'] = False
# 导入数据,删除有任何空值的行
df = pd.read_excel(r'D:\Python work space\jupyter\Pandas必刷100道题\600000.SH.xls')
df.dropna(axis=0,how='any',inplace=True)
df
1. 以df的列名创建一个DataFrame
创建的DataFrame只有列名,并没有数据
# 以df的列名创建一个DataFrame
temp = pd.DataFrame(columns=df.columns)
temp

2. 打印所有换手率为非数字的行
由表可知我们能够发现还手率都是小数,我们只需要判断该元素的数据类型是否为float类型
temp = [] # 存放所有的非数字的行号
for i in range(len(df)):
if type(df['换手率(%)'][i]) != float: # 判断该元素的数据类型是不是float类型
temp.append(i) # 记录不是数字的行索引
df.iloc[temp]
由图我们可以知道 换手率非数字的值均为--
3. 删除所有换手率为非数字的行
因为还手率的非数字行的会影响后面的分析,所以我们要将其删除
本次例题因为后面只分析还手率,所以就直接删原数据了,但是在实际中,可能其他数据还有用,不能轻易的删除
temp = [] # 存放所有的非数字的行号
for i in range(len(df)):
if type(df['换手率(%)'][i]) != float:
temp.append(i)
df= df.drop(labels=temp)
df
4. 重置df的行号
因为删除过部分行之后,索引就不连续了,不便于观察数据一共有多少行,会影响一些分析,所以我们就要删除一部分数据
使用是reset_index函数
参数
drop=True删除上次的索引,默认不会删除inplace=True修改原数据,默认不会修改原数据,会返回一个新的对象
# 重置data的行号
df.reset_index(drop=True,inplace=True)
df
观察最后几行,能够发现索引已经更新
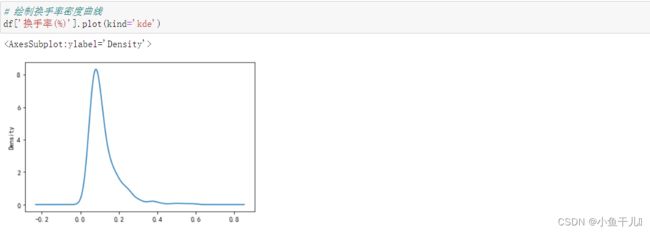
5. 绘制‘还手’密度曲线
绘制这个图形主要是能够让我们直观的观察到还手率集中到那个地方
df['换手率(%)'].plot(kind='kde')
从图中我们能够直观的发现数据多集中在0.0-0.2之间
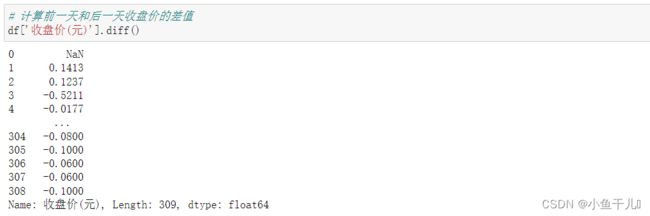
6. 计算后一天和前一天收盘价的差值
- 使用
shift()函数
shift(n)当n为正数该列向下移动n行,当n负数时该列向上移动|n|行
# 后一天减去前一天
df['收盘价(元)'] - df['收盘价(元)'].shift(1)
- 使用
diff()函数 默认为一阶差分
进一步简化了同一列差值的计算
df[].diff(n)等价于df[] - df[]..shift(n)
df['收盘价(元)'].diff() # 默认值为1,叫做一阶差分
# 等价于df['收盘价(元)'] - df['收盘价(元)'].shift(1)
7. 计算后一天与前一天收盘价的变化率
pct_change()也是一个简化的形式
具体情况看代码部分
# 计算前一天与后一天收盘价的变化率
df['收盘价(元)'].pct_change()
# 等价于df['收盘价(元)'].diff()/df['收盘价(元)']

8. 设置时间索引
设置索引,当所设置的列表示的是时间,就代表该索引是时间索引,时间索引值在实际生活中非常常见,时间索引也有自己独特的操作方式,按月取值,按周取值,取一年中的第几天等这些在普通索引看来非常困难的事情,对于时间索引来说却非常简单
df.set_index('日期')
9. 使用时间索引,分别按年份,月份取值
- 只取2016年的数据
df['2016']
- 取2017年3月份的数据
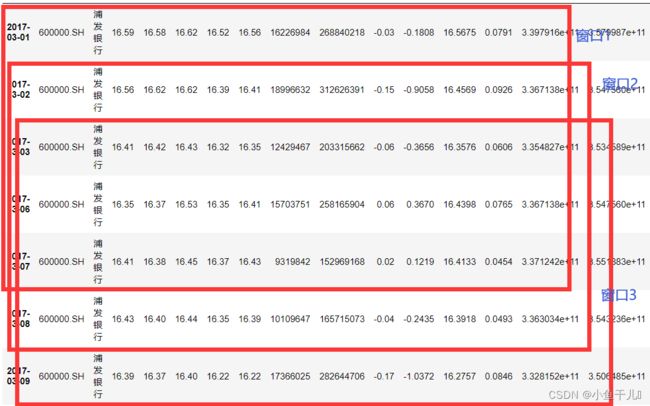
df['2017-3']
另外还可以按照季度,周目,获取某一年的第几天,时间索引的操作我会单独
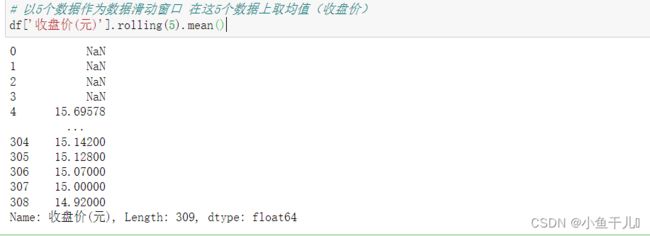
10. 以5个数据作为数据滑动窗口 在这5个数据上取均值(收盘价)
滑动窗口,每次移动一个单位,窗口内的数据始终是5个,
df['收盘价(元)'].rolling(5).mean() # 计算每次窗口内的平均值