基于Linux的C++轻量级web服务器/webserver/httpserver——线程池
1. 背景
什么是线程池?
线程池技术是池化技术的一种。除了线程池,还是内存池、连接池等其他池化技术。打个比方来说,线程池是将若干个随时可以执行任务的线程放在“池子”这种容器中,当我们要使用线程的时候,从线程池中取出即可;使用完成后再将线程归还给线程池,以便下次或者其他用户使用。
本项目为什么需要线程池?
使用线程池技术的最大好处是服务器可以避免因重复的建立和销毁线程带来的开销,从而提高服务器对客户端的响应速度。
此外,一个线程从诞生到结束,在系统中存在的时间可以分成三个阶段:创建耗时t1, 工作时间t2,销毁耗时t3。
n = t 2 t 1 + t 2 + t 3 n = \frac{t2}{t1+t2+t3} n=t1+t2+t3t2
为了提高服务器的效率,我们应该尽可能的增大t2,减少t1和t3。但一般来说,减少t1和t3是一个比较困难的事情,所以自然而然的会想到提高t2的时间。
目前,线程池技术的应用已经是一件很常见的事情了。该技术原理并不复杂,实现起来也较为容易。对于网络编程人员来说,这是一个必须得掌握的知识。
2. 实现
在编写一个线程池类之前,你需要具备以下知识:
- Linux多线程编程;
- 常见的数据结构;
- C++11编程;
在理解了线程池的工作原理后,自己动手实现一个并不算难。下面po出一张线程池的原理示意图:
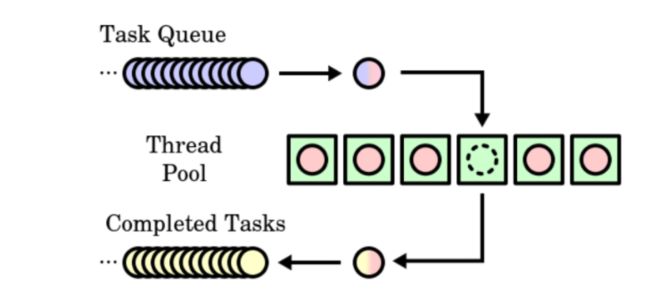
线程池类设计要点:
- 如何定义线程需要去执行的“任务”(Tasks):
- 首先要明确的一点是,“任务”是函数。无论你是使用Linux C的pthread库,还是C++的库,创建一个线程,为了让线程工作,都需要向线程传递一个函数。
- 然而,这个函数是需要预先声明和定义的。但是在线程池工作的时候,如果我们想要线程执行不同功能的函数,不可能提前知道并声明和定义好。所以,为了让线程执行不同的函数,传递给线程的函数中,会调用其他的函数以实现执行正确的任务;
- 选择合适的容器:对于线程,数组这类容器就能满足要求;而对于工作队列(Task Queue),可以选择队列或者链表。
- 正确的上锁:本质上,线程池类可以简化成生产者/消费者模型。线程执行task是在消耗资源,往线程池中添加task是在生产资源。这里的资源指的就是需要执行的函数。生产者/消费者模型中,有好几种上锁的方式:互斥锁+条件变量、信号量等。选择一种你习惯使用的就行。
如果你理解到线程池的本质是生产者/消费者模型后,其实如何编写这个类已经清晰很多了。你可能对于如何向线程池中添加不同的函数还感到疑惑,别着急,接着往下看。
我们可以把函数看做是一个对象,在线程池类的接口中,传递不同的函数,也就是传递不同类型的对象。这里引用C++的模板编程(template)。像我们常用的STL容器,例如vector, queue都是使用模板。在定义的时候并不知道,将来使用时将会是什么类型。
基于C++的模板编程,线程池类的对外接口append定义如下:
class ThreadPool
{
public:
/* ... */
template<class F>
void append(F &&task)
{
// 上锁
m_resEmpty.wait();
m_mtx.wait();
m_jobQueue.emplace(std::forward<F>(task));
// 解锁
m_resource.post();
m_mtx.post();
}
}
代码非常的简短啊,但是却能实现将不同类型的函数,添加进工作队列中。
当然,为了让工作队列能够存放不同类型的函数,同时编译不发生错误,我是这样定义的:
std::queue<std::function<void()>> m_jobQueue; // 工作队列
std::vector<std::thread> m_workThreads; // 线程
对外接口append函数中,除了上述提到的template模板,还使用了C++11的【右值引用】、【完美转发】、【function】以及【信号量】。右值引用和完美转发一般来说是都会是成对出现的。使用右值引用的原因是为了能够让函数能够接受临时变量作为参数,而完美转发简单来说是让左值始终是左值,右值始终是右值,不改变变量在这方面的属性。function是一个通用的多态函数包装器。在这可以理解成一种不定类型函数,向队列中添加任何类型的函数都不会发生冲突。
在外部调用对外接口append时,我们应该如何传递参数呢?这里就要用到C++11的bind了:
void add(int a, int b); // 定义一个加法函数
ThreadPool pool(8, 200); // 创建线程池
pool.append(std::bind(add, 1, 2)); // 向线程池中添加“任务”
bind可以看做是一种函数适配器,它可以接受一个可调用对象(实际函数),并且生成一个新的可调用对象。由bind产生的新的调用对象势必是一个临时变量,这也是我们为什么会在定义append参数列表时采用右值引用的原因了。
完整的代码如下所示:
#ifndef __THREADPOOLV5_H__
#define __THREADPOOLV5_H__
#include 写在后面:
如果你只学习了Linux C的pthread库,可能会对我代码中使用到的C++ thread感到困惑。别担心,其实thread的底层依然是Linux C的pthread库函数,多了一层类的封装罢了,相信好学的你通过在网上查阅相关的资源是可以解决这个问题的。如果你时间充裕,那我也建议可以读一下《C++并发编程实战》第二版,因为我就是通过这本书学习了一些thread库的知识。
*
我其实编写过两个版本的线程库,一个是用Linux C的库函数 + class写的,具体代码你可以在我的仓库里找找看。在使用更多C++11的特性进行重新编写后,一个很明显的感受就是代码量变少了很多。不得不说,拥抱更新的技术一定程度上能够减少程序员的工作量。