R语言-基于豆瓣电影详情数据的清洗和多元回归分析
R语言-基于豆瓣电影详情数据的清洗和多元回归分析
文章目录
- 前言
- 一、数据源说明
- 二、数据合并
-
- 1.RData合并
- 2.csv合并
- 三、数据清洗
-
- 1.导入数据
- 2.总体缺失值、异常值识别
-
- 2.1缺失值识别
- 2.2缺失值补充
- 2.3异常值识别
- 2.4重复值查找(一些尝试)
- 3.部分字段数据清洗
-
- 3.1日期处理
- 3.2分类变量--语言
- 3.3连续变量1--片长 数据清洗
- 3.4连续变量2--好评1+好评2 数据清洗
-
- 3.4.1处理"好于1"这一列
- 3.4.2处理"好于2"这一列
- 3.4.3 好于1+好于2
- 3.5连续变量3--短评数+话题数+影评数 数据清洗
-
- 3.5.1 短评数、话题数、影评数处理
- 3.5.2 相加
- 3.6连续变量4--想看人数、看过人数 数据清洗
- 4.多元回归分析
- 总结
前言
深圳大学传播学院-数据抓取与清洗课程(2021-2022学年第二学期)-微专业期末大作业

老师学期后段R语言讲得飞快,后面期末大作业布置时也改过几次要求,很多微专业同学面对这个作业都比较难受,题主自己也是在解决完其他课程ddl才开始在csdn上现学R语言┭┮﹏┭┮,在课程最终评分时老师给到高分。
那几个晚上熬夜赶工,根据作业的要求从不同博客中人工检索需要的语句,因此想分享到csdn给之后的同学R语言学习作一个参考~
**主要是将自己那几天完工的作业代码放了上来,ddl在即,确实没有很多的时间去钻研,可能并不一定是最优方法,欢迎评论区一起讨论~ **
如果有刚好是深大的网新/微专业同学(或者学弟学妹们),也欢迎随时私聊我交流学习~
第一篇博客,如有错误或者其他的,欢迎评论区指正~
一、数据源说明
豆瓣上7845部电影详情,共有34个字段。
在课程前期的作业一,老师随机给班级近80多个同学随机分配了约100+电影详情的抓取任务,通过八爪鱼软件进行抓取。
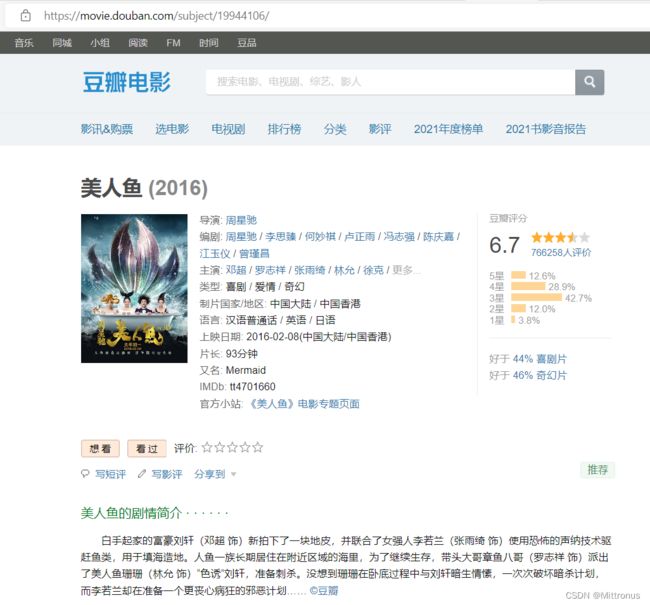
豆瓣电影详情页面 参考如下:
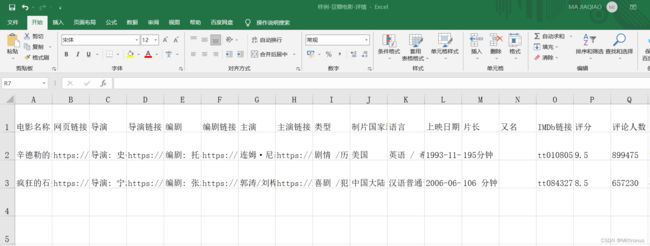
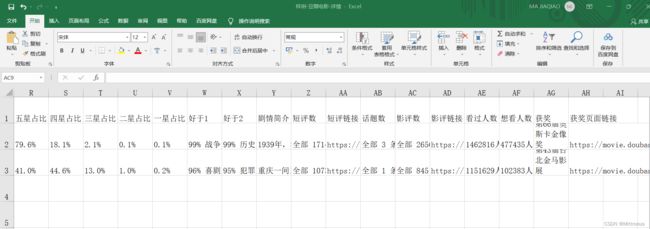
抓取字段内容及格式 示例:
共有34个字段,包括“电影名称”、“导演链接”、“上映日期”、“获奖链接”等等。(分成2张图截取)
二、数据合并
1.RData合并
同学们完成电影详情的抓取后,保存为csv或excel格式,导入R语言,存成RData格式,作业要求一为合并全班同学的RData文件,并存成新的movie1中,在后续数据清洗中使用。
RData合并老师有给出代码 这里以供参考
install.packages('stringr')
library(stringr)
setwd('d:\\douban\\detail') #设置工作目录,将同学们的RData文件都放在该目录下
files <- list.files(path = '.\\') # 列出detail文件夹里面所有的文件名
movie <- data.frame()
for(i in 1:length(files) ){
load(file = files[i])
temp <- movie1
row.file <- str_split(files[i],pattern = '_')[[1]]
row.file <- str_remove(row.file[length(row.file)],'\\.Rdata')
if( row.file == nrow(temp)){
movie <- rbind(movie,temp)
} else cat(files[i],'文件名为',row.file,'条','实际为',nrow(temp),'条') #查看文件名登记条数与实际条数的差异
}
files[i] # 查看是哪个文件错误
setdiff(colnames(movie1),colnames(movie)) # 查看列名错误
save(movie1,file = 'xxxx.Rdata') #将合并成功后的movie存成RData文件,准备下一步数据清洗工作
2.csv合并
install.packages('stringr')
library(stringr)
files <- list.files(path = 'd:\\douban\\detail', pattern = '.csv$') #列出detail文件夹里面所有以“csv”结尾的文件名
setwd("d:\\douban\\detail")
movie <- data.frame()
for(i in 1:length(files) ){
temp <- read.csv(file = files[i])
movie <- rbind(movie,temp)
}
三、数据清洗
作业要求再pose一遍~

这一部分提交Rmarkdown文件,代码块中#为一级标题注释,##为二级标题注释,另起一行红色代码块为运行结果,因为部分结果太长,仅保留前6行或后6行。
1.导入数据
#将合并后的RData导入
movie1<-load(file="C:\\workplace\\douban\\finish\\2020081024_detail_raw.RData")
#查看movie列名数量、核对条数等等
dim(movie)
[1] 7845 34
2.总体缺失值、异常值识别
作业要求:数据清洗,对错误字段或空白字段补充完整
这一部分识别、清洗缺失值和异常值较为草率,主要在于后面选取字段进行多元回归分析时,会对该字段作更细致的处理。
2.1缺失值识别
###利用is.na函数判断变量各值是否为缺失值,并返回True或FALSE组成的向量
is.na(movie$电影名称)
###统计缺失值与非缺失值的个数
table(is.na(movie))
FALSE TRUE
257818 8912
###sum()和mean()函数来统计缺失值的个数和占比
sum(is.na(movie))
mean(is.na(movie))
[1] 8912
[1] 0.03341206
###利用complete.cases函数查看完整实例
sum(complete.cases(movie))
[1] 4283
###载入‘mice’
library("mice")
###生成一个以矩阵或数据框形式展示缺失值模式的表格
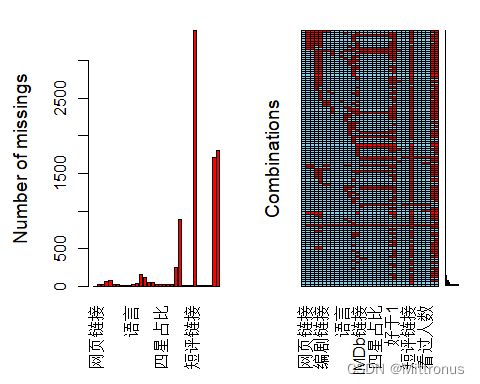
md.pattern(movie)
因为数据量太大了 图有点丑2333 挺难看的
###载入‘VIM’
library('VIM')
###用aggr函数对数据的缺失值模式进行可视化
aggr(movie[,-1],prop=FALSE,numbers=TRUE)
## Warning in plot.aggr(res, ...): not enough vertical space to display frequencies
## (too many combinations)
2.2缺失值补充
不同电影详情字段的缺失,可能为本身没有(即为0,抓取该电影数据的同学可能没有同意把空白值补为0),如果直接删除可能造成数据不全或缺失,所以对于缺失值采用的是补0;
对于部分数值型字段的缺失,想尝试用随机森林等算法进行插补,但因为时间不足,会在之后继续探索。
movie[is.na(movie)]<-'0'
2.3异常值识别
###提取数值字段
nums<-unlist(lapply(movie, is.numeric))
nums_data<-movie[,nums]
head(nums_data)
A tibble: 6 × 0
发现movie中不含numeric类型变量,均为character字符串类型变量,不作异常值处理
2.4重复值查找(一些尝试)
###安装dplyr
library('dplyr')
###查找movie中是否存在每个字段都一样的重复行,并进行去重
movie_de_dup <- distinct(movie,.keep_all = T)
dim(movie_de_dup)
[1] 7843 34
仅剔除两行,说明movie数据中基本无重复,不确定是否为完全相同,暂作保留,后面仍以movie作为分析对象
3.部分字段数据清洗
作业要求:任选电影详情的5个字段进行数据清洗,要求分类变量1个,连续变量4个
老师提示,如下图

#载入stringr包
library('stringr')
#载入plyr包,提取数字时需要
library(plyr)
3.1日期处理
###分隔字符串
time<-str_split_fixed(movie$上映日期,'\\(',n=2)
###提取第一个字段
time<- time[,1]
head(time)
[1] "2018-01-12" "2019-06-21" "2013-10-10" "2011-07-16" "2014-01-10"
###将字符串前后空格去掉
trimws(time,which = c("both","left","right"),whitespace = "[\t\r\n]")
[7837] " 2016-12-31"
[7838] " 2011-10-27"
[7839] " 1988-12-09"
[7840] " 1992-08-20"
[7841] " 2013-08-12"
[7842] " 1997-09-12"
[7843] " 2004-04-22"
[7844] " 2014-03-20"
[7845] " 2019-08-08"
time<-as.Date(time,format='%Y-%m-%d')
###去除空白
str_trim(time)
###将部分上映日期中的/替换成-
str_replace_all(time,"/","-")
[7816] "2010-04-24" "2005-09-13" "2017-02-11" "2013-01-18" "1960-05-15"
[7821] "2012-01-27" "1962-05-03" "2008-07-12" "2018-12-19" "2012-09-08"
[7826] "2010-02-09" "1932-01-20" "1999-12-17" "2007-10-18" "2001-07-09"
[7831] "1992-09-01" "1984-07-11" "2019-03-15" "2015-10-02" "2019-04-09"
[7836] "2013-06-05" "2016-12-31" "2011-10-27" "1988-12-09" "1992-08-20"
[7841] "2013-08-12" "1997-09-12" "2004-04-22" "2014-03-20" "2019-08-08"
3.2分类变量–语言
对数据中的语言进行排序统计
lang<-movie$语言
top_lang<-unlist(lang)
df<-as.data.frame(table(top_lang))
df<-arrange(df,desc(Freq))
head(df)
top_lang Freq
1 英语 2188
2 汉语普通话 1024
3 日语 751
4 粤语 474
5 韩语 300
6 法语 170
因此该分类变量的处理中,将根据上方排序结果,选取包含英语的赋值4,汉语普通话的赋值3,日韩的赋值2,其他的赋值为1。
for(i in 1:length(movie$语言)){
if(grepl("英语",movie$语言[i]))
{
movie$语言[i]<-4
}
else if (grepl("普通话",movie$语言[i])){
movie$语言[i]<-3
}
else if (grepl("日语",movie$语言[i])||grepl("韩语",movie$语言[i])){
movie$语言[i]<-2
}
else
movie$语言[i]<-1
}
head(movie$语言)
[1] "3" "4" "4" "2" "4" "3"
类型转换:数据中均为character类型,需转换为数值型。
class(movie$语言)
## Rmarkdown中的结果表示
## [1] "character"
language<-as.numeric(movie$语言)
class(language)
## [1] "numeric"
3.3连续变量1–片长 数据清洗
head(movie$片长) #查看数据情况
[1] "138分钟" "100分钟"
[3] "115分钟 / 125分钟(加长版)" "91分钟"
[5] "99分钟(中国大陆) / 98分钟(美国)" "93分钟"
缺失值补0
###缺失值补0
movie$片长[is.na(movie$片长)]<-0
table(is.na(movie$片长))
FALSE
7845
###将字符串前后空格去掉
trimws(movie$片长,which = c("both","left","right"),whitespace = "[\t\r\n]")
###分割字符串
flen=str_split_fixed(string=movie$片长,pattern = '分钟',n=2)
#str_split_fixed返回矩阵格式,定义一个新变量filmlen,将flen第一行赋给filmlen
flimlen<-flen[,1]
flimlen
仍存在部分值为“Canada:105”,采用提取数字的方法
fl1<-str_extract_all(flimlen,regex("[0-9/]"),simplify=TRUE)
fl1
Rmarkdown导出word结果

fl2<-function(x,data){
y<-paste0(data[x,],collapse="")
return(y)
}
ldply(lapply(c(1:nrow(fl1)), data = fl1, fl2))
合并后结果

filmlenok<-ldply(lapply(c(1:nrow(fl1)), data = fl1, fl2))
dim(filmlenok)
[1] 7845 1
filmlenok<-filmlenok[,1]
filmlenok
[1] "138" "100" "115" "91" "99"
[6] "93" "113" "100" "120" "212"
[11] "114" "104" "96" "108" "95"
[16] "89" "108" "99" "133" "116"
[21] "104" "118" "97" "96" "132"
[26] "130" "87" "115" "109" "145"
类型转换
## Rmarkdown中的结果表示
filmlenok<-as.numeric(filmlenok)
## Warning: 强制改变过程中产生了NA
class(filmlenok)
## [1] "numeric"
length(filmlenok)
## [1] 7845
filmlenok
## [1] 138 100 115 91 99 93 113 100 120 212 114 104
## [13] 96 108 95 89 108 99 133 116 104 118 97 96
## [25] 132 130 87 115 109 145 126 143 132 107 124 80
## [37] 85 123 104 101 96 99 110 113 108 135 117 129
## [49] 110 95 124 105 123 130 138 92 122 155 120 83
## [61] 160 151 104 154 122 81 103 107 118 105 87 99
table(is.na(filmlenok))
##
## FALSE TRUE
## 7790 55
#缺失值补0
filmlenok[is.na(filmlenok)]<-0
3.4连续变量2–好评1+好评2 数据清洗
3.4.1处理"好于1"这一列
head(movie$好于1)
## [1] "52% 剧情片" "85% 动画片" "83% 犯罪片" "66% 动画片" "89% 喜剧片"
## [6] "15% 悬疑片"
better1=str_split_fixed(string=movie$好于1,pattern = '%',n=2)
head(better1)
## [,1] [,2]
## [1,] "52" " 剧情片"
## [2,] "85" " 动画片"
## [3,] "83" " 犯罪片"
## [4,] "66" " 动画片"
## [5,] "89" " 喜剧片"
## [6,] "15" " 悬疑片"
better1rate<-better1[,1]
better1[,1]
## [1] "52" "85" "83"
## [4] "66" "89" "15"
## [7] "75" "21" "60"
## [10] "0" "88" "62"
## [13] "17" "52" "19"
## [16] "35" "86" "10"
better1r<-as.numeric(better1rate)
## Warning: 强制改变过程中产生了NA
class(better1r)
## [1] "numeric"
####缺失值补0
better1r[is.na(better1r)]<-0
table(is.na(better1r))
##
## FALSE
## 7845
3.4.2处理"好于2"这一列
head(movie$好于2)
## [1] "69% 爱情片" "95% 喜剧片" "85% 悬疑片" "74% 剧情片" "71% 动画片"
## [6] "9% 惊悚片"
better2=str_split_fixed(string=movie$好于2,pattern = '%',n=2)
head(better2)
## [,1] [,2]
## [1,] "69" " 爱情片"
## [2,] "95" " 喜剧片"
## [3,] "85" " 悬疑片"
## [4,] "74" " 剧情片"
## [5,] "71" " 动画片"
## [6,] "9" " 惊悚片"
better2rate<-better2[,1]
better2r<-as.numeric(better2rate)
####缺失值补0
better2r[is.na(better2r)]<-0
table(is.na(better2r))
##
## FALSE
## 7845
3.4.3 好于1+好于2
betterrate<-better1r+better2r
class(betterrate)
## [1] "numeric"
length(betterrate)
## [1] 7845
3.5连续变量3–短评数+话题数+影评数 数据清洗
3.5.1 短评数、话题数、影评数处理
可参考前处理“片长” 提取数字 方法相同 代码参考如下(只给出短评数处理代码,其他基本相同)
dp2<-str_extract_all(movie$短评数,regex("[0-9/]"),simplify=TRUE)
dp2
## [,1] [,2] [,3] [,4] [,5] [,6]
## [1,] "2" "1" "5" "0" "5" "9"
## [2,] "9" "2" "9" "0" "3" ""
## [3,] "1" "0" "9" "5" "1" "7"
## [4,] "3" "2" "0" "9" "0" ""
## [5,] "7" "6" "1" "9" "1" ""
## [6,] "1" "7" "3" "4" "" ""
dp3<-function(x,data){
y<-paste0(data[x,],collapse="")
return(y)
}
ldply(lapply(c(1:nrow(dp2)), data = dp2, dp3))
## V1
## 1 215059
## 2 92903
## 3 109517
## 4 32090
## 5 76191
## 6 1734
dpover<-ldply(lapply(c(1:nrow(dp2)), data = dp2, dp3))
dim(dpover)
## [1] 7845 1
dpover1<-dpover[,1]
dpover1<-as.numeric(dpover1)
class(dpover1)
## [1] "numeric"
length(dpover1)
## [1] 7845
3.5.2 相加
commentnum<-dpover1+htover1+ypover1
class(commentnum)
## [1] "numeric"
length(commentnum)
## [1] 7845
3.6连续变量4–想看人数、看过人数 数据清洗
同前 提取数字+合并+类型转换
4.多元回归分析
基于对movie中的语言进行排序号,依次为“英语”、“普通话”、“日语韩语”等,
将其转换为数值(4,3,2,1),由高到低排序对应不同排序的语言,可以作连续变量处理。
analyall<-data.frame(language,betterrate,filmlenok,commentnum,peoplenum)
analyall
## language betterrate filmlenok commentnum peoplenum
## 1 3 121 138 224567 1571751
## 2 4 180 100 93828 618937
## 3 4 168 115 110124 1008538
## 4 2 140 91 32528 212985
## 5 4 160 99 76430 851965
## 6 3 24 93 1794 9217
## 7840 4 44 95 NA 10961
## 7841 2 0 27 NA 9551
## 7842 1 156 93 NA 27932
## 7843 4 62 86 NA 13549
## 7844 3 0 92 NA 5623
## 7845 4 35 118 NA 10184
head(analyall)
## language betterrate filmlenok commentnum peoplenum
## 1 3 121 138 224567 1571751
## 2 4 180 100 93828 618937
## 3 4 168 115 110124 1008538
## 4 2 140 91 32528 212985
## 5 4 160 99 76430 851965
## 6 3 24 93 1794 9217
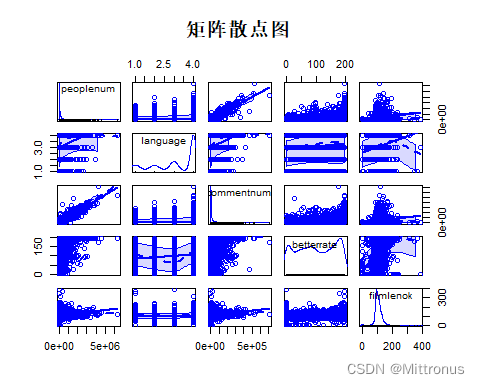
绘制矩阵散点图
library(car)
###绘制矩阵散点图
scatterplotMatrix(~peoplenum+language+commentnum+betterrate+filmlenok,data = analyall,main="矩阵散点图")
回归计算
lm.sol=lm(peoplenum~commentnum+betterrate+filmlenok+language,data = analyall)
summary(lm.sol)
##
## Call:
## lm(formula = peoplenum ~ commentnum + betterrate + filmlenok +
## language, data = analyall)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2524363 -31447 -3360 20967 2110513
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -2.916e+04 1.146e+04 -2.545 0.011 *
## commentnum 7.926e+00 4.988e-02 158.895 <2e-16 ***
## betterrate 4.100e+02 4.025e+01 10.187 <2e-16 ***
## filmlenok 1.597e+01 9.466e+01 0.169 0.866
## language -6.795e+02 2.121e+03 -0.320 0.749
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 151500 on 4213 degrees of freedom
## (因为不存在,3627个观察量被删除了)
## Multiple R-squared: 0.8792, Adjusted R-squared: 0.8791
## F-statistic: 7667 on 4 and 4213 DF, p-value: < 2.2e-16
可以看到,调整R2为0.8792;回归方程显著性的F检验中,P值小于显著性水平α(假设取0.05),表明选择线性模型合理。
在回归系数显著性检验中,片长filmlenok、language不显著,所以把这两个变量剔除。
remodel.lm=lm(peoplenum~commentnum+betterrate,data = analyall)
summary(remodel.lm)
##
## Call:
## lm(formula = peoplenum ~ commentnum + betterrate, data = analyall)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2524834 -31313 -3350 20884 2110273
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -2.954e+04 4.354e+03 -6.784 1.33e-11 ***
## commentnum 7.926e+00 4.910e-02 161.418 < 2e-16 ***
## betterrate 4.104e+02 3.902e+01 10.519 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 151500 on 4215 degrees of freedom
## (因为不存在,3627个观察量被删除了)
## Multiple R-squared: 0.8792, Adjusted R-squared: 0.8792
## F-statistic: 1.534e+04 on 2 and 4215 DF, p-value: < 2.2e-16
F检验:同样是非常显著,p-value < 2.2e-16
调整后的R^2:相关性非常强为0.8792
多重共线性检验
vif(remodel.lm)
## commentnum betterrate
## 1.124029 1.124029
从多重共线性检验效果来看,VIF<10,多重共线性还可以
三个平方和
SSR=deviance(remodel.lm)
SSR
## [1] 9.674236e+13
R2=summary(remodel.lm)$r.squared
SST=SSR/(1-R2)
SST
## [1] 8.00899e+14
SSE=SST-SSR
SSE
## [1] 7.041566e+14
求置信区间
confint(remodel.lm)
## 2.5 % 97.5 %
## (Intercept) -38074.338099 -21001.16265
## commentnum 7.829552 8.02208
## betterrate 333.950278 486.94827
remodel.lm
##
## Call:
## lm(formula = peoplenum ~ commentnum + betterrate, data = analyall)
##
## Coefficients:
## (Intercept) commentnum betterrate
## -29537.750 7.926 410.449
综上:设y=peoplenum,x1为commentnum,x2为betterrate
多元回归方程y=-29537.750+7.926x1+410.449x2
总结
本文基于7845条豆瓣电影详情数据,进行部分字段的清洗,并进行多元线性回归。
在实践中,可以增加对于R语言的掌握,get提取字段中数字的方法、类型转换的方法、以及stringr包的掌握(删除字符前后空格、提取字段等等)。