InnoDB原理篇:Change Buffer是如何提升索引性能的
前言
相信很多小伙伴设计索引时,考虑更多的是索引是否能覆盖大部分的业务场景,却忽略了索引的性能。
什么?不同的索引,性能还不一样?
是的,这要从change buffer说起。
Change Buffer是什么
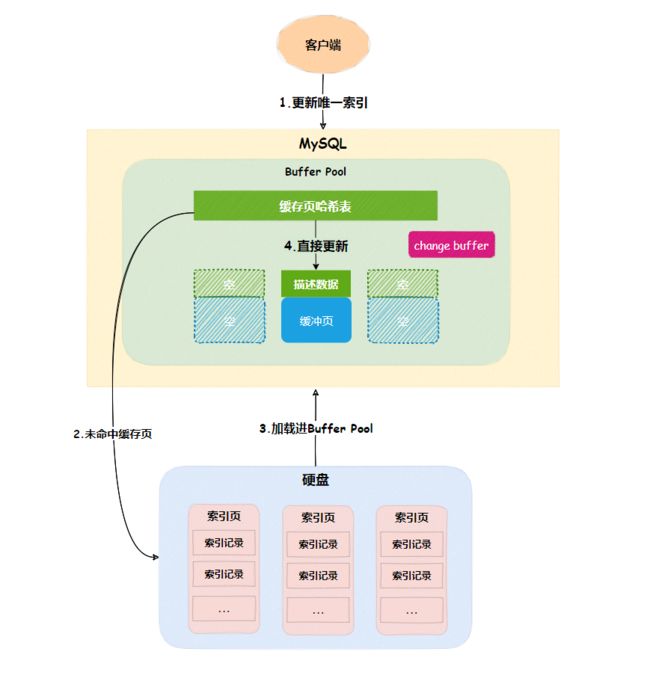
MySQL在启动成功后,会向内存申请一块内存空间,这块内存空间称为Buffer Pool。

Buffer Pool内维护了很多内容,比如缓存页、各种链表、redo log buff、change buffer等等。
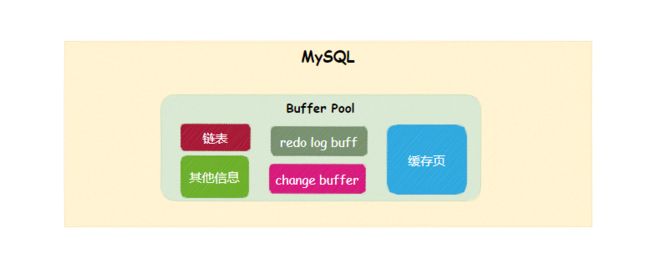
回到正题,change buffer是用来干嘛的?
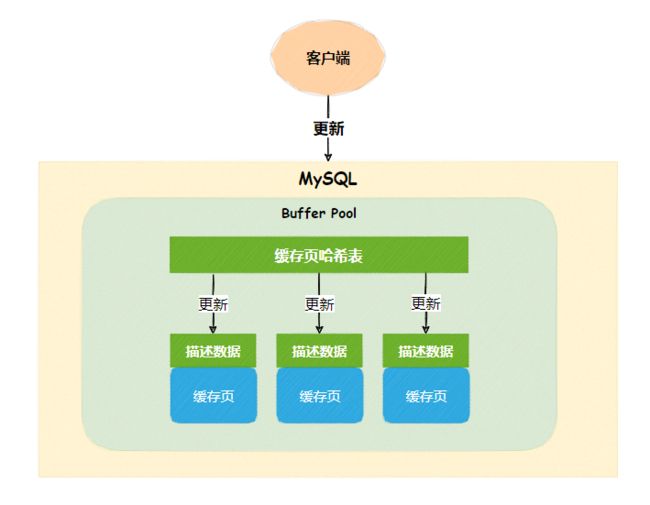
当索引字段内容发生更新时(update、insert、delete),要更新对应的索引页,如果索引页在Buffer Pool里命中的话,就直接更新缓存页。
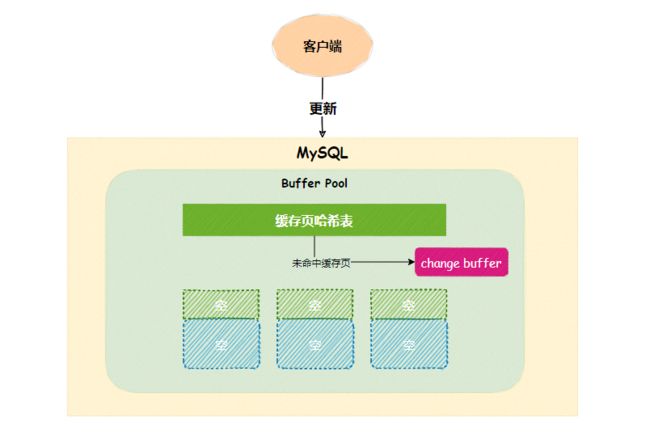
否则,InnoDB会将这些更新操作缓存在change buffer中,这样就无需从硬盘读入索引页。
下次查询索引页时,会将索引页读入Buffer Pool,然后将change buffer中的操作应用到对应的缓存页,得到最新结果,这个过程称为merge,通过这种方式就能保证数据逻辑的正确性。
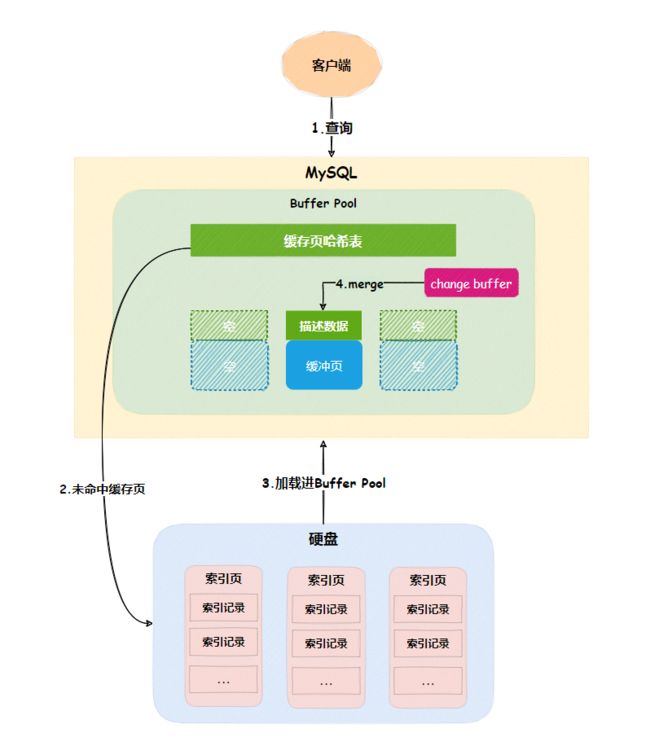
不难看出,change buffer通过减少硬盘随机IO读与提高内存利用率,让数据库的并发能力更强。
如果不了解Buffer Pool、redo log、索引页是什么,可以看看阿星之前写的几篇文章
-
聊聊redo log是什么?
-
不会吧,不会吧,还有人不知道 binlog ?
-
redo log与binlog间的破事
-
InnoDB原理篇:Buffer Pool为了让MySQL变快都做了什么
-
InnoDB原理篇:聊聊数据页变成索引这件事
持久化
看到这里小伙伴有疑问了,change buffer在内存中,如果万一MySql实例挂了或宕机了,这次的更新操作不全丢了吗?
其实不用担心,InnoDB对这块有相应的持久化方案,会有后台线程定期把change buffer持久化到硬盘的系统表空间(ibdata1)。
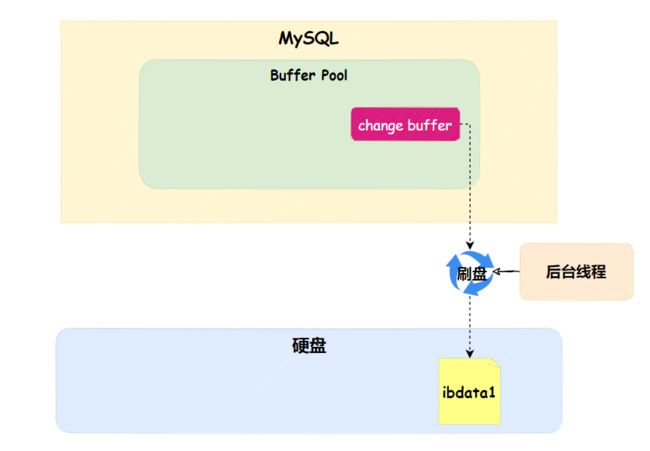
并且每次change buffer记录的内容,会写入到redo log buff中,由后台线程定期将redo log buff持久化到硬盘的redolog日志。
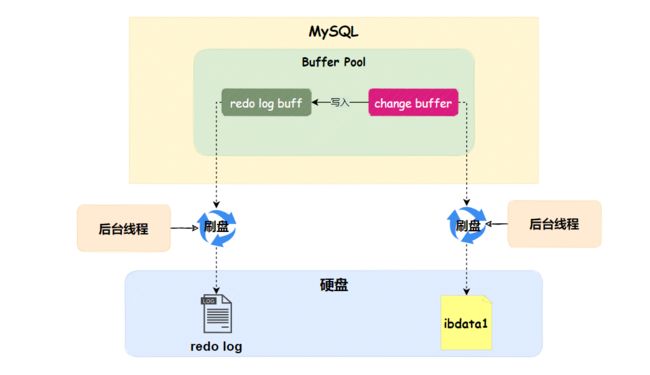
最后MySql重启,可以通过ibdata1或redolog恢复change buffer,恢复的过程,分为下面几种情况
-
change buffer的数据刷盘到ibdata,直接根据ibdata恢复 -
change buffer的数据未刷盘,redolog里记录了change buffer的内容-
change buffer写入redo log,redo log虽做了刷盘但未commit,binlog未刷盘,这部分数据丢失 -
change buffer写入redolog,redolog虽做了刷盘但未commit,binlog已刷盘,先从binlog恢复redolog,再从redolog恢复change buffe -
change buffer写入redolog,redolog和binlog都已刷盘,直接从redolog里恢复。
-
如果不清楚redolog与binlog的可以看看下面这几篇文章
-
3-聊聊redo log是什么?
-
4-不会吧,不会吧,还有人不知道 binlog ?
-
5-redo log与binlog间的破事
如何使用Change Buffer
看到这里,相信大家对change buffer有了基本的认识。
现在可以展开讲讲change buffer的使用限制。
是的,你没听错,change buffer不能随随便便用。
一般我们可以把常用索引分类为下面几种
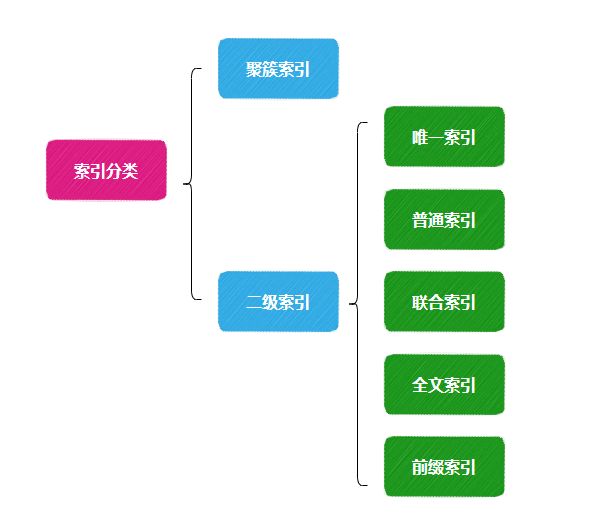
其中聚簇索引和唯一索引是无法使用change buffer,因为它们具备唯一性。
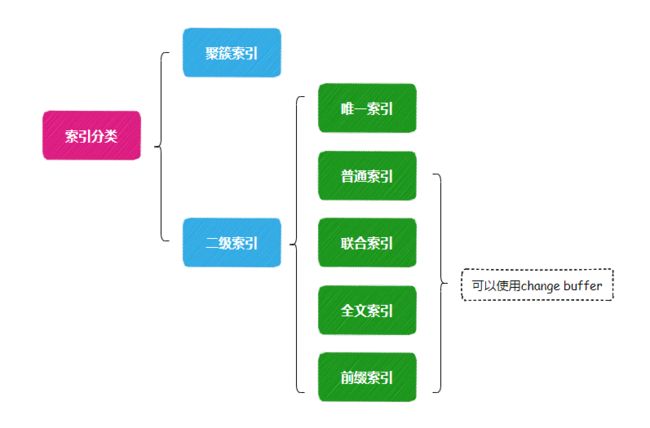
当更新唯一索引字段的内容时,需要把相应的索引页加载进Buffer Pool,验证唯一性约束,此时都已经读入到Buffer Pool了,那直接更新会更快,没必要使用change buffer。
也就是说,只有非唯一索引才能使用change buffer
业务场景
那现在有一个问题,使用change buffer一定可以起到加速作用吗?
相信大家都清楚merge的时候是将change buffer记录的操作应用到索引页。
所以索引页merge之前,change buffer记录的越多收益就越大。
因此对于写多读少的业务场景,索引页在写完以后马上被访问到的概率很小,此时change buffer的收益最高。
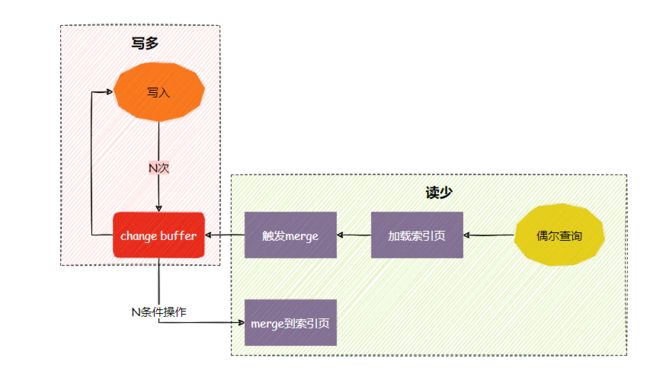
相反,读多写少的业务场景,更新完马上做查询,则会触发change buff立即merge, 不但硬盘随机IO次没有减少,还增加change buffer的维护成本。
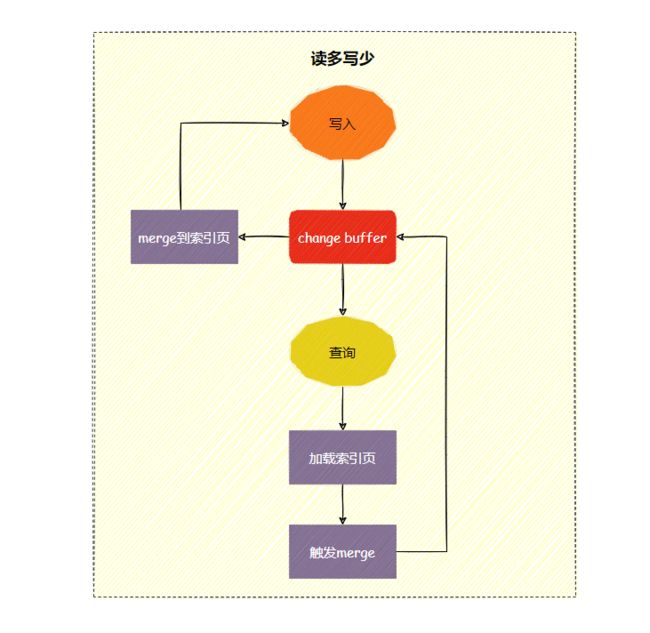
因此change buff适合写多读少的业务场景
选择索引
由于唯一索引用不上change buffer的优化机制,在业务可以接受的情况下,从性能角度出发建议考虑非唯一索引
如果所有的更新后面,都马上伴随着对这个记录的查询,应该关闭change buffer,innodb_change_buffering设置为none表示关闭change buffer。
而在其他情况下change buffer都能提升更新性能。
我们可以通过innodb_change_buffer_max_size来动态设置change buffer占用的内存大小,假设参数设置为50的时候,表示change buffer的大小最多只能占用buffer pool的 50%。
最后留个思考题,如果知道redo log一定清楚WAL机制,change buffer与WAL分别提升性能的侧重点是什么?