爬取哔哩哔哩数据
1、前言
哔哩哔哩是当代年轻人最喜欢的app之一,最近呢又看到了哔哩哔哩上了热收哈哈哈哈。今天呢就来爬取一下B站的一些数据
2、分析
首先我们肯定是要获取他的链接找到弹幕存储的位置
示例链接:
https://www.bilibili.com/video/BV1TX4y1P7BK
我们查看网页的源代码:
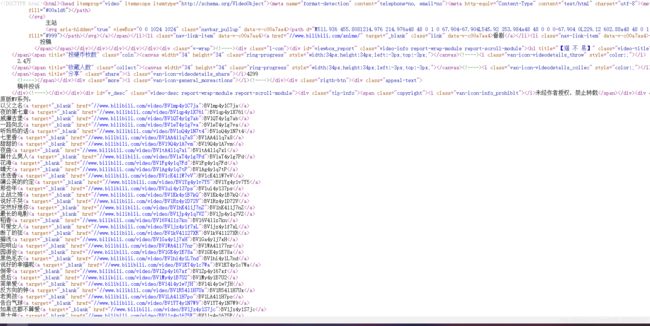
查阅资料可以知道在弹幕是存储在https://comment.bilibili.com/331677295.xml这个文件里面
我们查看一下
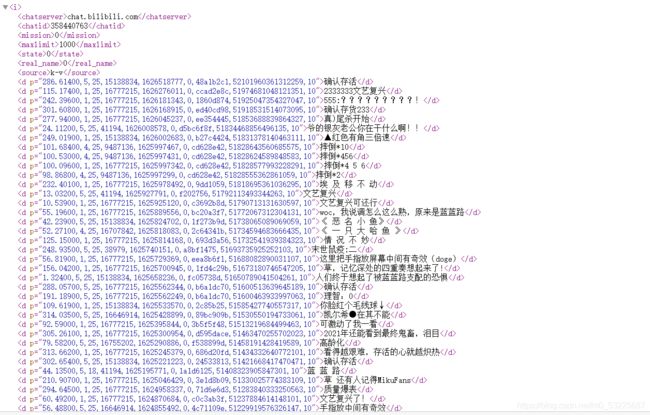
可以看到这个视频的弹幕都在这了只需要把他提取出来就欧克了
代码
首先我们需要知道我们要爬取视频的链接,所以我们先获取他的链接怎么获取链接呢?
import requests
from bs4 import BeautifulSoup
url = 'https://www.bilibili.com/v/popular/rank/all' # 爬取B站排行榜(总榜)上视频链接
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
# 定义列表来存储数据
Author = [] # 作者
URL = [] # 链接
Name = [] # 标题
# 利用bs4,找到视频链接以及视频名字和up主
get_Author = soup.find_all('span', class_='data-box up-name', )
get_url = soup.find_all('a', class_="title")
# 将数据存入列表中
for data in get_Author:
author = data.text.replace('\n', '').replace(' ', '')
Author.append(author)
for item in get_url:
URL.append(item['href'].replace('//', 'https://')) # 找到链接并转换成链接形式
Name.append(item.text)
# 将数据写入文件中保存下来
header = ['作品名', '作者', '作品链接']
headers = ','.join(header)
date = (list(z) for z in zip(Name, Author, URL)) # 把数据成组,方便写入文件。
with open("作品数据.csv", 'w+', encoding='utf-8') as f:
f.write(headers+'\n')
for i in date:
i = ','.join(i) # 将列表转为字符串
f.writelines(i+'\n')
print('{:*^30}'.format('保存成功!'))
这就是我们获取目标视频链接代码
run一下

保存成功在看一下数据。
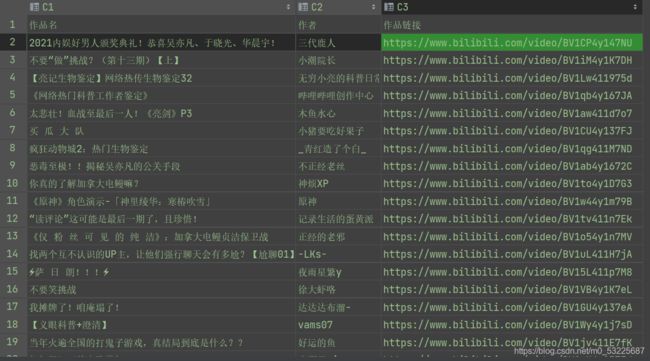 完美
完美
接下来就开始写爬取弹幕数据的代码
import re
import requests
import pandas as pd
import time
# 从作品数据中把URL读取出来,爬取相对应的视频弹幕。
data = pd.read_csv('作品数据.csv', encoding='utf-8')
get_url = data['作品链接']
get_name = data['作品名']
get_author = data['作者']
# 开始爬取弹幕,写一个函数来爬取对应作品排名的弹幕
def get_danmu(i, j): # 从第i名开始到第j名结束
i = i-1 # 列表数据是从0开始的所以先减一
while i < j:
url = str(get_url[i])
res = requests.get(url) # 请求网页
cid = re.findall(r'"cid":(.*?),', res.text)[-1] # 找到cid从源代码中res.text 发现最后一个是我们需要的数据我们取最后一个
url = f'https://comment.bilibili.com/{cid}.xml' # 利用格式化字符串来组成我们需要的文件。
res = requests.get(url)
with open('弹幕源文件/{}.xml'.format(get_name[i]), 'wb') as f: # 将数据写入文件中
f.write(res.content)
with open('弹幕源文件/{}.xml'.format(get_name[i]), encoding='utf-8') as f:
Shuju = f.read()
comments = re.findall('(.*?) ', Shuju) # 只保存弹幕数据其他的就不保存了
Danmu = [item for item in comments]
headers = 'text'
Danmu.insert(0, headers) # 添加表头
with open('弹幕数据/{}的弹幕;up主:{}.csv'.format(get_name[i], get_author[i]), 'w', encoding='utf_8_sig') as f:
f.writelines([line+'\n' for line in Danmu]) # 写入数据
i += 1 # 开始爬取下一页
print('{:*^30}'.format('第{}名作品弹幕爬取成功'.format(i))) # 有利于观察我们爬在哪了。
time.sleep(1.5) # 睡眠1.5秒防止爬取过快,封ip
get_danmu(int(input("从第几名开始:")), int(input('到第几名结束:'))) # 开始跑函数
代码写完毕了我们run一下

爬取成功
查看数据

 看起来不错
看起来不错
如果感兴趣下一篇文章来分析我们爬取的弹幕数据,看看有什么值得我们取挖掘的。