Python 线程池 (thread pool) 创建及使用 + 实例代码
前言
首先线程和线程池不管在哪个语言里面,理论都是通用的。对于开发来说,解决高并发问题离不开对多个线程处理。我们先从线程到线程池,从每个线程的运行到多个线程并行,再到线程池管理。由浅入深的理解如何在实际开发中,使用线程池来提高处理线程的效率。
一、线程
1.线程介绍
线程(英语:thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。在 Unix System V 及 Sun 中也被称为轻量进程(lightweight processes),但轻量进程更多指内核线程(kernel thread),而把用户线程(user thread)称为线程。
线程是独立调度和分派的基本单位。线程可以为操作系统内核调度的内核线程,如 Win32 线程;由用户进程自行调度的用户线程,如 Linux 平台的 POSIX Thread;或者由内核与用户进程,如 Windows 10 的线程,进行混合调度。
同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等等。但同一进程中的多个线程有各自的调用栈(call stack),自己的寄存器环境(register context),自己的线程本地存储(thread-local storage)。
一个进程可以有很多线程,每条线程并行执行不同的任务。
2.线程特性
1)轻型实体
线程中的实体基本上不拥有系统资源,只是有一点必不可少的、能保证独立运行的资源。
线程的实体包括程序、数据和 TCB。线程是动态概念,它的动态特性由线程控制块 TCB(Thread Control Block)描述。TCB 包括以下信息:
(1)线程状态。
(2)当线程不运行时,被保存的现场资源。
(3)一组执行堆栈。
(4)存放每个线程的局部变量主存区。
(5)访问同一个进程中的主存和其它资源。
用于指示被执行指令序列的、保留局部变量,少数状态参数和返回地址等的一组寄存器和堆栈。
2)独立调度和分派的基本单位
在多线程 OS 中,线程是能独立运行的基本单位,因而也是独立调度和分派的基本单位。由于线程很“轻”,故线程的切换非常迅速且开销小(在同一进程中的)。
3)可并发执行
在一个进程中的多个线程之间,可以并发执行,甚至允许在一个进程中所有线程都能并发执行;同样,不同进程中的线程也能并发执行,充分利用和发挥了处理机与外围设备并行工作的能力。
4)共享进程资源
在同一进程中的各个线程,都可以共享该进程所拥有的资源,这首先表现在:所有线程都具有相同的地址空间(进程的地址空间),这意味着,线程可以访问该地址空间的每一个虚地址;此外,还可以访问进程所拥有的已打开文件、定时器等。由于同一个进程内的线程共享内存和文件,所以线程之间互相通信不必调用内核。
二、线程池
线程池(英语:thread pool):一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、网络 sockets 等的数量。 例如,线程数一般取 cpu 数量+2 比较合适,线程数过多会导致额外的线程切换开销。
任务调度以执行线程的常见方法是使用同步队列,称作任务队列。池中的线程等待队列中的任务,并把执行完的任务放入完成队列中。
线程池模式一般分为两种:HS/HA 半同步/半异步模式、L/F 领导者与跟随者模式。
HS/HA 半同步/半异步模式:
半同步/半异步模式又称为生产者消费者模式,是比较常见的实现方式,比较简单。分为同步层、队列层、异步层三层。同步层的主线程处理工作任务并存入工作队列,工作线程从工作队列取出任务进行处理,如果工作队列为空,则取不到任务的工作线程进入挂起状态。由于线程间有数据通信,因此不适于大数据量交换的场合。
L/F 领导者与跟随者模式
领导者跟随者模式,在线程池中的线程可处在 3 种状态之一:领导者 leader、追随者 follower 或工作者 processor。任何时刻线程池只有一个领导者线程。事件到达时,领导者线程负责消息分离,并从处于追随者线程中选出一个来当继任领导者,然后将自身设置为工作者状态去处置该事件。处理完毕后工作者线程将自身的状态置为追随者。这一模式实现复杂,但避免了线程间交换任务数据,提高了 CPU cache 相似性。在 ACE(Adaptive Communication Environment)中,提供了领导者跟随者模式实现。
线程池的伸缩性对性能有较大的影响。
-
创建太多线程,将会浪费一定的资源,有些线程未被充分使用。
-
销毁太多线程,将导致之后浪费时间再次创建它们。
-
创建线程太慢,将会导致长时间的等待,性能变差。
-
销毁线程太慢,导致其它线程资源饥饿。
在面向对象编程中,创建和销毁对象是很费时间的,因为创建一个对象要获取内存资源或者其它更多资源。在 Java 中更是如此,虚拟机将试图跟踪每一个对象,以便能够在对象销毁后进行垃圾回收。所以提高服务程序效率的一个手段就是尽可能减少创建和销毁对象的次数,特别是一些很耗资源的对象创建和销毁。如何利用已有对象来服务就是一个需要解决的关键问题,其实这就是一些""池化资源""技术产生的原因。比如大家所熟悉的数据库连接池正是遵循这一思想而产生的,本文将介绍的线程池技术同样符合这一思想。
三、线程池的设计思路
首先我们根据上述已经了解了线程和线程池创建目的以及作用。让我们自己思考一下,如果是自己的业务上要用到大量的请求或者是查询处理,而我们只能的机器并不能一下就接受这么多的 task 涌入计算,这将消耗我们计算机大量资源。这时我们就该创建线程池来对线程进行管理,我们可以给线程预留一定的空间,让请求逐个进入线程处理,当请求超过我们给的线程数量时,等一个线程跑完了再跑下一个,这样就不会造成资源的浪费和达到资源重复利用。
那么我们建立线程池的思路就有一下几点:
-
控制线程,给予每个线程任务保证线程正常运行。
-
限制线程数量,保证系统有足够的运行空间。
-
资源复用,保证每个线程运行完成任务后能再度利用。
-
控制运行时间,线程运行超过一定时间后停止任务转接下个任务,防止线程堵塞。
有了这些思路,我们就可以充分利用 Python 自带的库来构建线程池了。
四、Python 线程池构建
1.构建思路
第一步,我们需要在线程池里面创建出很多个线程。第二步,当得到一个请求时候,就使用一个线程来运行·它。第三步,若多个任务则分配多个线程来运行。当其中一个线程运行完它的任务之后,将再次进行下一个任务使用。
2.实现库功能函数
首先 python 标准库里面是有 threading 库的,但是该库并没有线程池这个模块。要快速构建线程池,可以利用 concurrent.futures,该库提供了 ThreadPoolExecutor 和 ProcessPoolExecutor 两个类,实现了对 threading 和 multiprocessing 的进一步抽象。这里我们只讨论 ThreadPoolExecutor:
from concurrent.futures import ThreadPoolExecutor
复制代码
这里我们可以看 JAVA 关于线程池的设计:
构造方法:public ThreadPoolExecutor(int corePoolSize, //核心线程数量int maximumPoolSize,// 最大线程数long keepAliveTime, // 最大空闲时间TimeUnit unit, // 时间单位BlockingQueueworkQueue, // 任务队列 ThreadFactory threadFactory, // 线程工厂RejectedExecutionHandler handler // 饱和处理机制){ ... }
复制代码
参数和 Python 创建线程池是一样的,python 创建线程池:
#encoding:utf-8from concurrent.futures import ThreadPoolExecutorimport threading#创建一个包含2条线程的线程池pool = ThreadPoolExecutor(max_workers = 2) #定义两个线程
复制代码
这样就建立了一条简单的线程池,其中最大线程数为 2 .
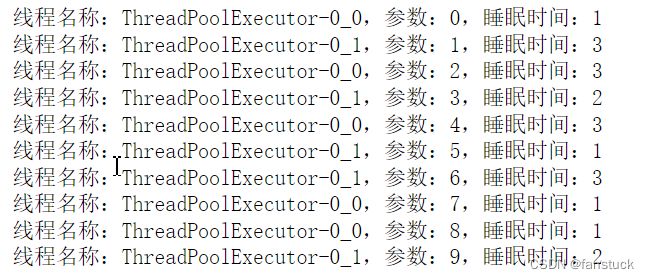
def task(i):sleep_seconds = random.randint(1, 3) #随机睡眠时间print('线程名称:%s,参数:%s,睡眠时间:%s' % (threading.current_thread().name, i, sleep_seconds))time.sleep(sleep_seconds) #定义睡眠时间for i in range(10):#创建十个任务future1 = pool.submit(task, i)
复制代码
ThreadPoolExecutor()
构造线程池实例,传入 max_workers 可以设置线程池中最多能同时运行的线程数目
submit()
提交线程需要执行的任务(函数名和参数)到线程池中,立刻返回一个future对象。
result()
取 task 的执行结果

cancel()
取消该 Future 代表的线程任务。如果该任务正在执行,不可取消,则该方法返回 False;否则,程序会取消该任务,并返回 True。

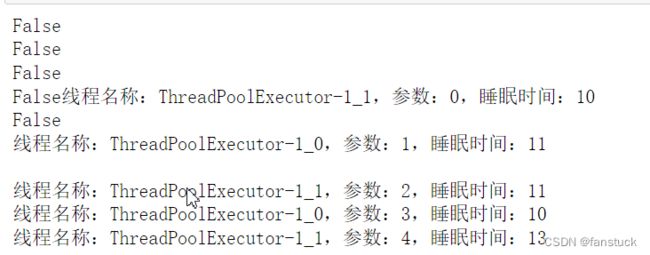
调高点睡眠时间:

cancelled()
返回 Future 代表的线程任务是否被成功取消。
for i in range(5):#创建十个线程future1 = pool.submit(task, i)print(future1.cancelled())
复制代码
running()
for i in range(5):#创建十个线程future1 = pool.submit(task, i)print(future1.running())
复制代码

as_completed()
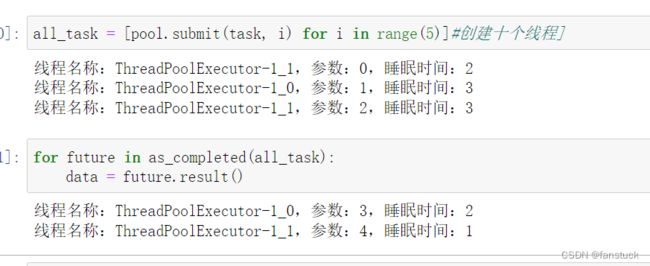
as_completed()方法是一个生成器,在没有任务完成的时候,会阻塞,在有某个任务完成的时候,会 yield 这个任务,就能执行 for 循环下面的语句,然后继续阻塞住,循环到所有的任务结束。从结果也可以看出,先完成的任务会先通知主线程。
map()
除了 submit,ThreadPoolExecutor 还提供了 map 函数来添加线程,与常规的 map 类似,区别在于线程池的 map() 函数会为 iterables 的每个元素启动一个线程,以并发方式来执行 func 函数. 同时,使用 map 函数,还会自动获取返回值。
#向线程池提交5个任务x = np.arange(5)for i in pool.map(task,x):print('successful')
复制代码

小伙伴们有兴趣想了解内容和更多相关学习资料的请点赞收藏+评论转发+关注我,后面会有很多干货。
我有一些面试题、架构、设计类资料可以说是程序员面试必备!所有资料都整理到网盘了,需要的话欢迎下载!私信我回复【07】即可免费获取

原文出处:xie.infoq.cn/article/6320496b3523d06e13f1c3c1b