什么是数据归一化和标准化
为什么需要进行数据预处理
我们对模型进行训练时,数据集的特征差距过大,会对模型产生不利的影响,就比如我们在预测一个人普通人身高时,如果数据集中包含正常人的身高数据、侏儒症身高和NBA球员的身高数据,那么我们在构建一个预测普通人身高的模型时,侏儒症身高和NBA球身高数据就会对我们的模型产生不利的影响,从而无法准确预测一个普通人的身高。
因此我们将训练集数据传入模型之前,需要对数据集进行预处理。常规的数据预处理有两种方法:归一化和标准化。
归一化处理原理和代码
- 归一化公式
归一化是把所有数据映射到(0,1)之间。公式如下:
![]()
流程如下:
- 计算所有样本每个特征的最大值和最小值
- 将每个样本特征的值减去该特征的最小值
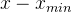
- 计算每个特征的极差
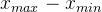
- 将2中结果除以3中的结果,最终得到归一化后的结果
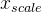
- 归一化适用情况
归一化适用于有明显分界的特征数据,比如分数得分0-100
- 归一化缺点
受异常值影响很大
- 代码
from sklearn import datasets
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 归一化处理后数据集划分
X1_train,X1_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=1)
# 使用MinMaxScaler进行归一化处理
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train1 = scaler.transform(X_train)
X_test1 = scaler.transform(X_test)
# knn分类
knn_clf= KNeighborsClassifier(n_neighbors=3)
knn_clf1.fit(X_train1,y_train)
# 模型评估
knn_clf1.score(X_test1,y_test)标准化处理原理和代码
- 标准化公式
标准化是将所有数据往正态分布调整,也叫Z分数。公式如下:
![]()
流程如下:
- 计算每个特征的均值和标准差
- 将所有样本的特征减去均值
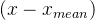
- 将2的结果除以标准差,得到标准化后的结果
- 标准化适用情况
异常值对标准化影响不大,一般用于没有明显分界的数据分布
- 代码
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 归一化处理后数据集划分
X1_train,X1_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=1)
# 使用MinMaxScaler进行归一化处理
scaler = StandardScaler()
scaler.fit(X1)
X_train2 = scaler.transform(X_train)
X_test2 = scaler.transform(X_test)
# knn分类
knn_clf= KNeighborsClassifier(n_neighbors=3)
knn_clf1.fit(X_train2,y_train)
# 模型评估
knn_clf1.score(X_test2,y_test)![]()
以上数据没有体现出两种数据预处理对于模型的结果的影响
归一化和标准化的api
- 模块
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler- 方法
Scalar 类中有三个方法 fit,transform,fit_transform:
fit():计算每个特征关键信息(均值,标准差,极值等)并保存;
transform():会使用 fit 方法保存的关键信息(均值,标准差,极值等)进行归一化 / 标准化转换;
fit_transform():相当于 fit 和 transform 一起调用。
- 测试集和训练集是否一起预处理
一般来说,我们用训练集的关键信息进行预处理,因为我们模型在实际使用过程中要预测的真实数据经常没有办法计算均值和方差。所以一般先进行数据划分,再使用训练集得出关键信息,然后对训练集和测试集分别进行预处理。