《python程序设计实践》课程设计报告(胡润百富榜数据爬取及分析)
1 需求分析
随着科学技术的不断发展,信息流通日益方便,信息数据不断膨胀,充斥在各行各业。由于数据非常庞大,所以即使在搜索引擎存在的情况下,搜索结果的准确率也不高,这使得在网上查找关键有效信息也变为一项极具挑战性的复杂任务。胡润百富是追踪记录中国企业家群体变化的权威机构,是由出生于欧洲卢森堡的英国注册会计师胡润先生于1999年创立的。百富榜对于记录中国经济进程的作用被广泛肯定。通过爬取胡润百富榜并筛选有效信息,可以快速分析富豪排名变化、公司总部地分布、性别占比分布、组织结构分布等,有利于观察中国经济状况,提高资源利用率。具体在应用方面则是通过程序能方便查询百润富豪榜中的具体单个或多个数据内容。基于此将数据分析系统的功能分为数据的采集,采集数据的分析、处理及存储,数据结果的可视化展示。上述功能是逐级递进的关系,首先需要对百润富豪榜中的富豪数据进行采集及预处理,预处理完成后项目以csv文件的形式存入本地文件中,实现数据的分类处理,制作相应数据图表,最终进行项目分析结果可视化展示。以下进行各部分功能需求的详细描述:
1.1数据采集需求分析
需要对胡润百富榜中的项目数据进行采集,寻找项目网页的URL规律,编写定向网络爬虫代码对整个榜单数据库中的富豪信息进行信息爬取,每个爬取到的网页内容需要先进行预处理,筛选出各类项目的描述数据,将筛选到的数据以csv文件的形式存储在本地中。
1.2采集数据的分析、处理及存储需求分析
需要将预处理后的富豪信息存入csv文件中,以富豪信息csv文件中对富豪信息共有的关键字描述结合用户数据分类需求作为分类标准,对富豪信息进行数据分析,绘制相应的柱状图、直方图、饼状图、词云图,并将绘制图形存入本地文件夹中。
1.3数据结果的可视化展示需求分析
需要根据上述的分析后的数据绘制相应可视化的图形(柱状图、直方图、饼状图、词云图),方便向用户展示数据,满足用户对富豪信息数据的宏观认识需求及从各类信息中查询单个或多个信息需求。
2 概要设计
2.1程序目录结构设计
程序项目结构由两个主程序(guan_spider.py、guan_analysis.py)以及一个存储数据的2021胡润百富榜.csv文件,再加上公司总部分布TOP30、年龄分布、行业TOP20柱形图和性别占比分布、组织结构分布饼图以及一张词云图构成。具体如图2.1所示

图2.1 程序目录结构
2.2 程序总体流程设计
首先导入需要用到的库requests用来向页面发送请求,pandas用来从存入数据和读取csv文件,matplotlib是用来进行画图的,wordcloud用来进行词云图的绘制,sleep是用来设置等待间隔的,目的是为了防止反爬。offset是一个偏移量,每翻一页offset的值增加200,因为每一页的容量是200。然后发送请求、查看响应码,用JSON格式来接收数据,然后把定义的空列表依次append上抓取到的数据。然后进行一个for循环的追加,把爬取到的数据写入到csv文件里,mode等于a+就是追加的意思。如果爬取到页面是第一页的话,header就是true,不是第一页header就是false。这个header这样写就可以防止它的重复写入csv文件,导致出现重复的数据。设置两个配置项,这两个配置项是为了解决matplotlib显示中文出现乱码方块的问题。然后根据数据生成图表及词云图后对数据进行分析和可视化操作。
3 运行环境(软、硬件环境)
1.硬件环境:PC机-内存 16GB。
2.软件环境:操作系统-windows11。
4 开发工具和编程语言
开发环境:PyCharm Professional Edition 2021.3.3 x64。
编程语言:Python3.10。
5 详细设计
本系统实现了数据的采集、数据的处理、数据分析、数据可视化功能。能通过csv文件访问胡润百富榜中富豪姓名、年龄、排名、公司名称、公司总部地、所在行业、组织结构、财富值变化、年份等信息。具体展示如下:
5.1 数据提取
数据提取模块是本系统的第一大功能模块,对系统的后续模块开发而言项目数据的提取是开发前提。数据提取模块运用的关键技术是Python爬虫技术,通过Python语言编写爬虫程序先对静态网页进行爬取,在静态网页爬取成功之后进行动态网页的爬取,得到网页解析所需的项目源码。在源码爬取成功的基础上,进行源码的网页解析,对比源码及原网页,找出项目相关信息在源代码中的对应部分,根据其编写规律制作自动爬取程序,爬取到的项目数据预处理完成后以csv文件的形式存储在本地文件夹中,以便下一模块的使用。爬取开始时首先需要获取特定的URL网址。爬虫通过HTTP协议来模拟浏览器向目标网页发送请求。网页在通过一系列验证措施之后,对请求进行响应并将网页内容以网页源码的形式反馈给Python程序。获取的网页源码暂存在Python界面中或直接下载到本地文件中,在获取源码的基础上,开始对网页内容进行解析,解析过程通过Python中的一些第三方库对网页内容解析,解析得到的目标所需的网页内容存入本地文件,得到的下一个进行爬取的网页URL进行筛选。筛选后若存在新的URL则重复以上爬虫步骤,实现爬虫程序的自动运行,若无新的URL则结束整个爬虫程序。Python爬虫流程如下图5.1所示:
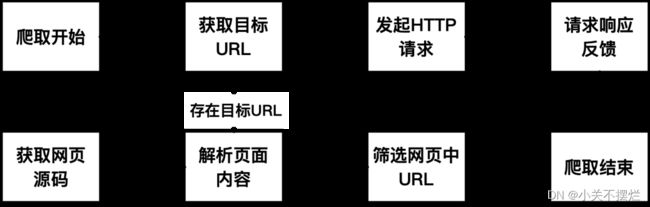
图5.1 Python爬虫流程图
5.2数据采集
在数据提取模块中需完成网页数据采集工作,即项目网页源代码下载。本系统数据采集的目标是胡润百富榜中富豪信息数据,且网页URL带有一定的规律性,可以方便的进行URL队列的更新,更换爬取网页,自动循环爬取所有目标静态网页。本系统编写的网络爬虫程序是通过模拟Chrome浏览器访问网页来进行爬取。
对于胡润百富榜的网页来说,网页数据的采集应从第一个初始网页开始,寻找队列中其他网页的URL命名规律,通过验证其规律后再推广到所有待爬取的网页,达到自动更新URL队列,循环爬取所有具有规律性静态网页的目的。对于百富榜网网页来说,URL网址的命名带有易于发现的规律性,可以简单发现在URL中不同区域的各个数字变化导致整个网页URL改变,故可直接通过Python中的requests模块来对网页发送请求,在代码中加入循环结构,改变URL中的数字内容来进行循环爬取。从第一个网页可以看出,当前的网址并无验证措施,但为了解决IP限制的问题,在除初始URL之外每次发送请求之前加了一段延时代码,每次增加1~2秒的延时,有效的防止了由于短时间大量访问造成的IP限制。在网页进行响应后,得到了可进行解析的网页页面源码。页面源码暂时性的存储在Python界面,需及时对源码进行解析才能对下一个URL网页进行源码爬取,在获取了第一个页面源码并对源码进行解析之后,需注意网页请求的关闭,从而不会占用系统资源,循环爬取代码后即可爬取所有的网页。网页爬取流程如图5.2所示,其重要代码如下所示:
for page in range(1,16):
sleeptime = random.uniform(1,2)
print('开始等待{}秒'.format(sleeptime))
sleep(sleeptime)
print('开始爬取第{}页'.format(page))
offset = (page - 1)*200
url = 'https://www.hurun.net/zh-CN/Rank/HsRankDetailsList?num=YUBAO34E&search=&offset={}&limit=200'.format(offset)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'accept':'pplication/json, text/javascript, */*; q=0.01',
'accept-language':'zh-CN,zh;q=0.9',
'accept-encoding':'gzip, deflate, br',
'content-type':'application/json',
'referer':'https://www.hurun.net/zh-CN/Rank/HsRankDetails?pagetype=rich&num=YUBAO34E'
}
图5.2 网页爬取流程图
5.3数据采集结果
数据采集通过模拟Chrome浏览器访问网页来进行网页爬取,通过不同的URL队列获取方式确认爬取目标,实现网页及动态网页项目数据采集,网页URL队列自动更新完成,网页源码实现自动爬取,网页爬取结果暂存在Python界面中,可在Python界面对比网页源码及网页内容,进行网页源码解析。
5.4数据预处理
用JSON格式来接收数据,在网页上打开预览看一下这个数据从 0 到19一共是20条数据。页面上的第一页20名富豪,第一条就是,钟睒睒养生堂,就是排名第一的富豪的数据。那他的个人的一些信息年龄、出生地是放在character这个节点下面的。那他的公司的一些信息是放在他的外层,例如行业等等。所以根据这样的一个JSON结构,就可以进行一个代码的编写解析这样的一个JSON数据。逻辑其实就是,把定义的空列表依次append上我们抓取到的数据,然后进行一个for循环的追加,写入到csv文件里。那这里有一个小逻辑,就是如果爬取到页面是第一页的话,这个header就是true我不是第一页header 就是false这个header就是指的上面这排紫色的抬头名称。那如果写上这个逻辑,就可以防止它的重复写入csv文件出现重复的数据。应用pandas模块将列表数据保存到csv文件,将制作的文件保存到本地中,这样存储数据后在分析数据时可以再通过本地数据的提取找到数据。mode等a+就是追加的意思。最后保存csv文件这样的一份数据就爬取下来了。到此网页的数据预处理基本完成。网页的数据解析流程如图5.3所示,其重要代码如下所示:
r = requests.get(url,headers=headers)
print(r.status_code)
json_data = r.json()
Fullname_Cn_list = []
Fullname_En_list = []
Age_list = []
BirthPlace_Cn_list = []
BirthPlace_En_list = []
Gender_list = []
Photo_list = []
ComName_Cn_list = []
ComName_En_list = []
ComHeadquarters_Cn_list = []
ComHeadquarters_En_list = []
Industry_Cn_list = []
Industry_En_list = []
Ranking_list = []
Ranking_Change_list = []
Relations_list = []
Wealth_list = []
Wealth_Change_list = []
Wealth_USD_list = []
Year_list = []
print('开始解析json数据')
item_list = json_data['rows']
for item in item_list:
print(item['hs_Character'][0]['hs_Character_Fullname_Cn'])
Fullname_Cn_list.append(item['hs_Character'][0]['hs_Character_Fullname_Cn'])
Fullname_En_list.append(item['hs_Character'][0]['hs_Character_Fullname_En'])
Age_list.append(item['hs_Character'][0]['hs_Character_Age'])
BirthPlace_Cn_list.append(item['hs_Character'][0]['hs_Character_BirthPlace_Cn'])
BirthPlace_En_list.append(item['hs_Character'][0]['hs_Character_BirthPlace_En'])
Gender_list.append(item['hs_Character'][0]['hs_Character_Gender'])
Photo_list.append(item['hs_Character'][0]['hs_Character_Photo'])
ComName_Cn_list.append(item['hs_Rank_Rich_ComName_Cn'])
ComName_En_list.append(item['hs_Rank_Rich_ComName_En'])
ComHeadquarters_Cn_list.append(item['hs_Rank_Rich_ComHeadquarters_Cn'])
ComHeadquarters_En_list.append(item['hs_Rank_Rich_ComHeadquarters_En'])
Industry_Cn_list.append(item['hs_Rank_Rich_Industry_Cn'])
Industry_En_list.append(item['hs_Rank_Rich_Industry_En'])
Ranking_list.append(item['hs_Rank_Rich_Ranking'])
Ranking_Change_list.append(item['hs_Rank_Rich_Ranking_Change'])
Relations_list.append(item['hs_Rank_Rich_Relations'])
Wealth_list.append(item['hs_Rank_Rich_Wealth'])
Wealth_Change_list.append(item['hs_Rank_Rich_Wealth_Change'])
Wealth_USD_list.append(item['hs_Rank_Rich_Wealth_USD'])
Year_list.append(item['hs_Rank_Rich_Year'])
图5.3 网页爬虫解析流程图
5.5数据预处理结果
经过数据预处理后富豪信息表格制作完成,数据基本上包括了所有网页上的相关信息,具体而言在内容方面包括姓名、年龄、排名、公司名称、公司总部地等内容,具体部分数据如下图5.4所示:

图5.4 部分数据信息展示
6 调试分析
问题1:在cmd命令行用pip install安装好了第三方库,在pycharm中import这个库的时候,依然显示没安装。
解决:原因是因为电脑上存在多个python运行环境(比如,cmd里是py3.9,pycharm里是py3.10),可以在目标python安装目录的Scripts下面,用pip安装。
问题2:用pandas库的to_csv函数保存csv文件时,保存进去的内容打开之后显示乱码。
解决:to_csv时,加一个参数:encoding='utf_8_sig',用utf_8_sig的编码格式保存文件。
问题3:read_csv失败,pandas在read_csv时,报错:OSError: Initializing from file failed。
解决:原因是文件路径中包含了中文,由于read_csv函数的默认引擎engine为C,不支持对中文的识别,导致报该错误。在使用notebook打开文件时常见这个问题。更改engine='python'即可执行成功。更改engine='python'即可执行成功。df=pd.read_csv('2021胡润百富榜.csv',engine='python')。
7 测试结果
7.1查看最后3名富豪信息,使用df.tail(3),具体如图7.1所示。

图7.1 查看后三名信息
7.2对富豪信息进行描述性统计,使用df.describe(),具体如图7.2所示。
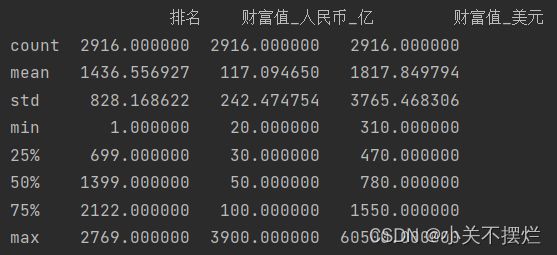
图7.2 描述性统计
7.3查看富豪财富值(人民币),并且生成财富分布直方图,具体如图7.3和图7.4所示。得出结论:大部分的富豪的财富集中在20亿~400亿之间,个别顶级富豪的财富在3000亿以上。
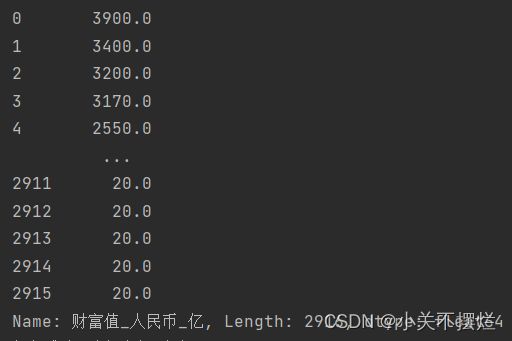
图7.3 财富值(人民币)
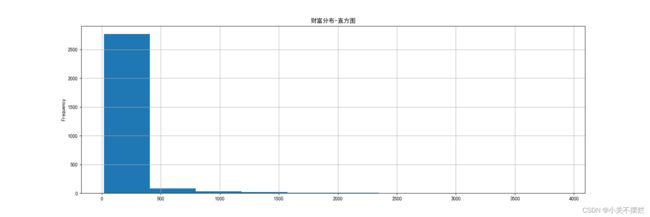
7.4 财富分布直方图
7.4剔除年龄为未知的信息后,以已知的年龄信息生成年龄分布柱形图,如图7.5所示。得出结论:大部分富豪的年龄在50-60岁,其次是60-70和40-50岁。极少数富豪在20-30岁。
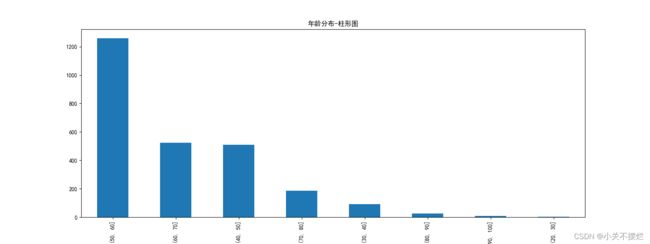
图7.5 年龄分布柱形图
7.5查看富豪公司总部分布地,并且生成公司总部分布TOP30柱形图,具体如图7.6和图7.7所示。得出结论:公司分布城市大多集中在北上广深等一线城市,另外杭州、香港、苏州也位列前茅。
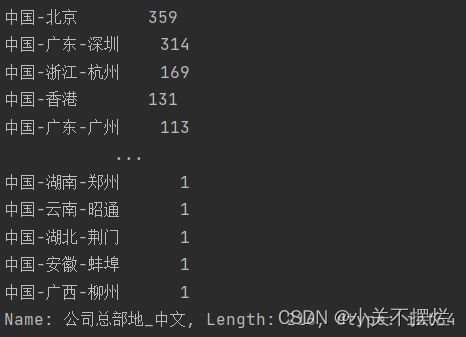
图7.6 总部分布地
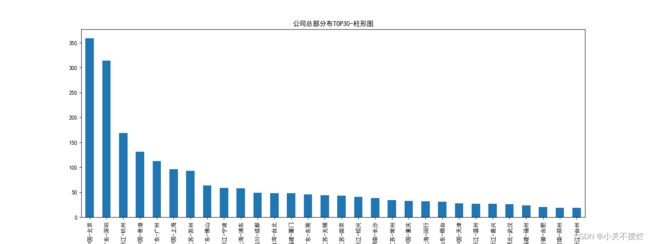
7.7 公司总部分布TOP30柱形图
7.6查看富豪性别统计数据,并且生成性别占比分布饼图,具体如图7.8和图7.9所示。得出结论:男性富豪占据绝大多数,个别女性在列。
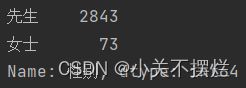
图7.8 性别统计
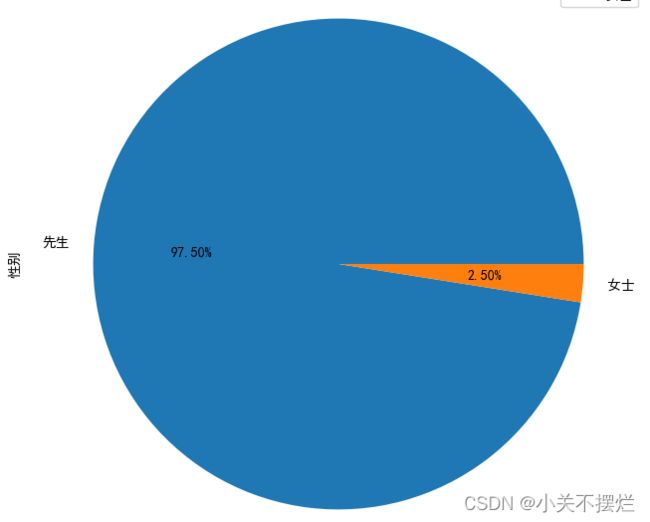
图7.9 性别占比分布饼图
7.7查看全部女性富豪,使用df[df.性别 == '女士']['全名_中文'].values,具体如图7.10所示
 图7.10 全部女性富豪
图7.10 全部女性富豪
7.8查看富豪行业分布统计数据,并且生成行业分布TOP20柱形图,具体如图7.11和图7.12所示。得出结论:百富榜中占比最多的行业分别是:房地产、医药、投资、化工等。
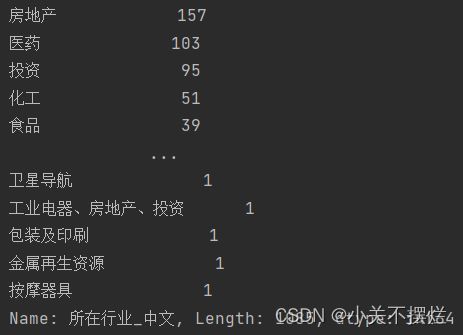
7.11 行业分布
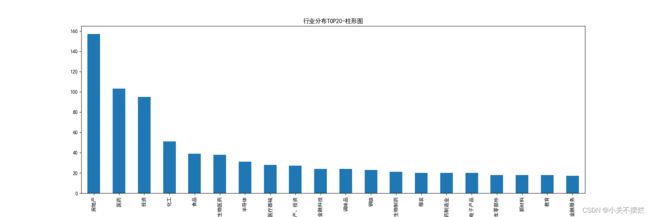 7.12 行业分布TOP20柱形图
7.12 行业分布TOP20柱形图
7.9查看富豪组织结构分布统计数据,并且生成组织结构分布-饼图,具体如图7.13和图7.14所示。得出结论:半数以上是未知,原因是企业未对外开放,或榜单没有统计到。家族和夫妇占据前两类。
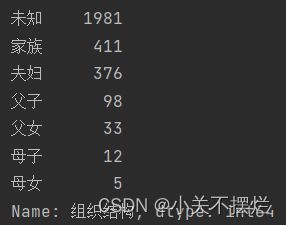
7.13 组织结构分布
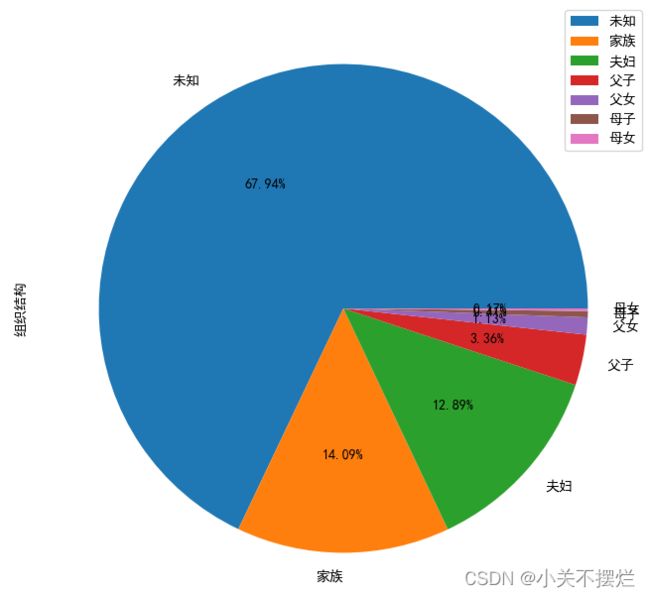
7.14 组织结构分布饼图
7.10生成公司名称词云图,并且使用df['公司名称_中文'].value_counts().head(5)分组统计最多的前5名公司名称,具体如图7.15和7.16所示。得出结论:阿里系公司占据榜首,其次是海天味业等。
图7.15 词云图
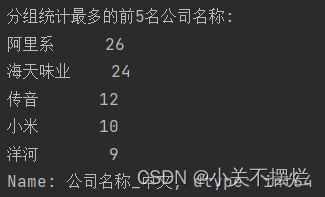
图7.16 前五名公司名称
8 心得体会
从开始这次Python课程设计到完成这次课程设计一共经历了两周时间。在这两周时间里,一边写程序一边学习,晚上基本都学到半夜,但是当程序功能一点一点距离自己的预期时,就会觉得所有的付出都值了,学到了很多东西,我从对网络爬虫技术一无所知,到能成功的编写出简单的网络爬虫程序,并对网络爬虫中的一些基本技术有了一定的理解。这次课程设计我完成的是一个基于python的爬虫程序,能爬取胡润百富榜的富豪信息,并存到本地csv文件里,数据爬下来结构清晰。在编写程序过程中,虽然之前学过python基础,但是对于爬虫没有接触,遇到了很多问题,比如怎么爬、爬取后怎么解析、怎么存储数据等。通过百度、CSDN、GitHub、哔哩哔哩,一边学习一边编写,经过两周时间终于完成了爬取胡润百富榜富豪数据并存储功能。这些问题的解决都让我受益匪浅。本次爬虫选取《胡润百富榜》的一个原因是因为这个网站数据返回是直接到HTML页面中,容易解析和获取数据。目前,系统基本功能已经完成,并能在实际中使用,不过对于该系统还存在一些可待改进的地方,一是系统通用性增强。目前系统只能针对指定的网站进行多页数爬取,数据提取模块也是针对该网站内容做的处理,系统整体通用性不强,之后可以考虑分析多个网站架构,针对不同网站内容的共性和特性设计通用性更强的数据提取,使系统应用范围更广泛。
参考文献
[1]嵩天 礼欣 黄天羽. Python语言程序设计基础(第2版). 北京:高等教育出版社,2017.
[2](美)梁勇著,李娜译 Python语言程序设计. 北京:机械工业出版社出版时间:2015.
[3]孙玉胜 曹洁. Python语言程序设计(第2版)(微课版) 北京:清华大学出版社出版 2021.