算法学习记录~2023.5.22~动规Day2~62.不同路径 & 63. 不同路径 II & 343. 整数拆分 & 96.不同的二叉搜索树
算法学习记录~2023.X.XX~章节DayX~题目号.题目标题 & 题目号.题目标题
- 62.不同路径
-
- 题目链接
- 思路1:当作二叉树进行深度搜索
- 代码
- 思路2:动态规划
- 代码
- 总结
- 63. 不同路径 II
-
- 题目链接
- 思路
- 代码
- 总结
- 343. 整数拆分
-
- 题目链接
- 思路
- 代码
- 总结
- 96.不同的二叉搜索树
-
- 题目链接
- 思路:动态规划
- 代码
- 总结
62.不同路径
题目链接
力扣题目链接
思路1:当作二叉树进行深度搜索
每次只能向下或者向右移动一步,那么其实机器人走过的路径可以抽象为一棵二叉树,而叶子节点就是终点。

不过会超时。
来分析一下时间复杂度,这个深搜的算法,其实就是要遍历整个二叉树。
这棵树的深度其实就是m+n-1(深度按从1开始计算)。
那二叉树的节点个数就是 2^(m + n - 1) - 1。可以理解深搜的算法就是遍历了整个满二叉树(其实没有遍历整个满二叉树,只是近似而已)
所以上面深搜代码的时间复杂度为O(2^(m + n - 1) - 1),可以看出,这是指数级别的时间复杂度,是非常大的。
代码
class Solution {
private:
int dfs(int i, int j, int m, int n) {
if (i > m || j > n) return 0; // 越界了
if (i == m && j == n) return 1; // 找到一种方法,相当于找到了叶子节点
return dfs(i + 1, j, m, n) + dfs(i, j + 1, m, n);
}
public:
int uniquePaths(int m, int n) {
return dfs(1, 1, m, n);
}
};
思路2:动态规划
机器人从(0,0)出发,到(m - 1,n - 1)终点。
动规五步曲:
- 确定 dp 数组(dp table)以及下标的含义
dp[i][j]:表示从从(0,0)出发到(i,j)有 dp[i][j] 条不同路径
- 确定递推公式
想要求dp[i][j],只能有两个方向来推导出来,即dp[i - 1][j] 和 dp[i][j - 1]。
此时在回顾一下 dp[i - 1][j] 表示啥,是从(0, 0)的位置到(i - 1, j)有几条路径,dp[i][j - 1]同理。
那么很自然,dp[i][j] = dp[i - 1][j] + dp[i][j - 1],因为dp[i][j]只有这两个方向过来
- dp 数组如何初始化
这次初始化的不能只是左上角几个点了,而是两条边。
首先dp[i][0]一定都是1,因为从(0, 0)的位置到(i, 0)的路径只有一条,那么dp[0][j]也同理
所以初始化代码
for (int i = 0; i < m; i++)
dp[i][0] = 1;
for (int j = 0; j < n; j++)
dp[0][j] = 1;
- 确定遍历顺序
由于推导公式为 dp[i][j] = dp[i - 1][j] + dp[i][j - 1],dp[i][j] 都是从上方和左方推导来的,所以从左到右一层层遍历即可。
这样可以保证推导到 dp[i][j] 时,dp[i - 1][j] 和 dp[i][j - 1] 都一定有数值
- 举例推导 dp 数组
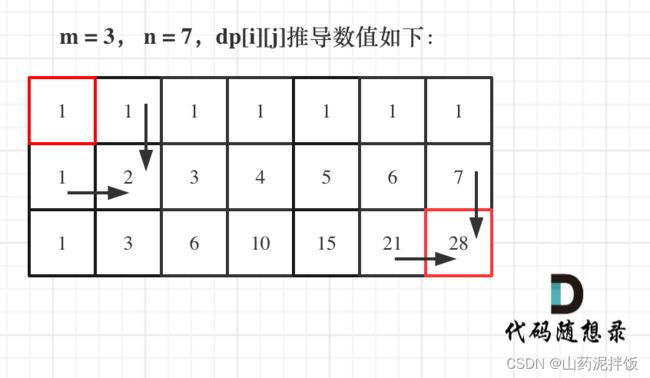
代码
class Solution {
public:
int uniquePaths(int m, int n) {
vector<vector<int>> dp(m, vector<int>(n, 0));
for (int i = 0; i < m; i++)
dp[i][0] = 1;
for (int j = 0; j < n; j++)
dp[0][j] = 1;
for (int i = 1; i < m; i++){
for (int j = 1; j < n; j++){
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m - 1][n - 1];
}
};
总结
63. 不同路径 II
题目链接
力扣题目链接
思路
大体思路和 62.不同路径 一致,需要注意的有以下。
- 在起点或终点有障碍物,则无论如何都是 0 条路径,需要特殊处理
- 初始化时,两条边需要判断没有障碍物该 dp 初始值才赋值为 1 ,否则保持默认 dp 值 0
- 具体递归过程中,需要判断当前位置是否是障碍物,如果是则直接保持默认 dp 值 0 跳过继续后续处理
代码
class Solution {
public:
int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {
int m = obstacleGrid.size();
int n = obstacleGrid[0].size(); //注意这里取 n 的方法
if (obstacleGrid[m - 1][n - 1] == 1 || obstacleGrid[0][0] == 1) //如果在起点或终点出现了障碍,直接返回0
return 0;
vector<vector<int>> dp(m, vector<int>(n, 0));
//初始化
for (int i = 0; i < m && obstacleGrid[i][0] == 0; i++)
dp[i][0] = 1;
for (int j = 0; j < n && obstacleGrid[0][j] == 0; j++)
dp[0][j] = 1;
//求路径
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
if (obstacleGrid[i][j] == 0) //不是障碍物时才可以算,是障碍物则直接保持dp默认值0
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m - 1][n - 1];
}
};
总结
343. 整数拆分
题目链接
力扣题目链接
思路
会很头疼应该拆成几个数,自己没想出来,下面总结下carl哥的讲解
动规五步曲:
- 确定 dp 数组(dp table)以及下标的含义
dp[i]:通过拆分 i 能获取的最大乘积为 dp[i]
- 确定递推公式
可以想 dp[i]最大乘积是怎么得到的,其实可以从 1 遍历到 j ,然后有两种渠道得到dp[i].
- j 和 i - j 直接两数相乘得到 i * (i - j)
- j * dp[i - j],相当于拆分 i - j,相当于拆分成两个及两个以上
第二种之所以不拆分j,是因为拆分 j 的情况在遍历 j 的过程中就计算过了。
所以递推公式为 dp[i] = max({dp[i], (i - j) * j, dp[i - j] * j});
因为在递推公式推导的过程中,随着 j 的遍历,每次计算 dp[i] 要取最大的,所以还要比较一下这个
- dp 数组如何初始化
根据 dp[i] 的定义,拆分2得到的最大乘积是1,所以 dp[2] = 1。
拆分1和0没有什么实际意义。
- 确定遍历顺序
dp[i] 是依靠 dp[i - j]的状态,所以遍历i一定是从前向后遍历,先有dp[i - j]再有dp[i]
所以遍历顺序为
for (int i = 3; i <= n ; i++) {
for (int j = 1; j <= i / 2; j++) {
dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));
}
}
枚举j的时候,是从1开始的。从0开始的话,那么让拆分一个数拆个0,求最大乘积就没有意义了。
i是从3开始,这样dp[i - j]就是dp[2]正好可以通过我们初始化的数值求出来。
因为拆分一个数n 使之乘积最大,那么一定是拆分成m个近似相同的子数相乘才是最大的。所以使用 j <= i / 2,再往后就没必要继续遍历了,一定不是最大值
- 举例推导 dp 数组
代码
class Solution {
public:
int integerBreak(int n) {
vector<int> dp(n + 1);
dp[2] = 1;
for (int i = 3; i <= n; i++){
for (int j = 1; j <= i / 2; j ++){
dp[i] = max(dp[i], max(j * (i - j), dp[i - j] * j));
}
}
return dp[n];
}
};
总结
本题的第二步递推公式的确定是个人感觉最难想到的,一开始自己完全没想到过这种细分方式。
96.不同的二叉搜索树
题目链接
力扣题目链接
思路:动态规划
参考思路链接
由于 1,2…n 这个数列是递增的,所以我们从任意一个位置“提起”这课树,都满足二叉搜索树的这个条件:左边儿子数小于爸爸数,右边儿子数大于爸爸数 。
其实从这个数列构建搜索树就是一个不断细分的过程。
比如要用 [1,2,3,4,5,6] 构建
首先,提起 “2” 作为树根,[1]为左子树,[3,4,5,6] 为右子树
现在就变成了一个更小的问题:如何用 [3,4,5,6] 构建搜索树?
比如,我们可以提起 “5” 作为树根,[3,4] 是左子树,[6] 是右子树
现在就变成了一个更更小的问题:如何用 [3,4] 构建搜索树?
那么这里就可以提起 “3” 作为树根,[4] 是右子树 或 “4” 作为树根,[3] 是左子树
可见 n=6 时的问题是可以不断拆分成更小的问题的
设 dp[i] 为从 1 到 i 的递增数列可以有多少种不同的二叉搜索树
可以得知几种简单情况, dp[0] = 1, dp[1] = 1, dp[2] = 2,其中 dp[0] 理解为空时只有唯一情况,而且是 1 而不是 0 也避免了后面相乘的时候变为 0
根据上述例子容易得知dp[3] = dp[0] * dp[2] + dp[1] * dp[1] + dp[2] * dp[0]
同理, dp[4] = dp[0] * dp[3] + dp[1] * dp[2] + dp[2] * dp[1] + dp[3] * dp[0]
对于每一个 i ,其式子都是有规律的,每一项两个 dp[] 的数字加起来都等于 i - 1
既然我们已知 dp[0] = 1, dp[1] = 1, 那么就可以先算出 dp[2], 再算出dp[3], 然后 dp[4] 也可以算了,最后得到的 dp[n] 就是我们需要的解了
代码
class Solution {
public:
int numTrees(int n) {
vector<int> dp(n + 1);
dp[0] = 1;
dp[1] = 1;
for (int i = 2; i <= n; i++){
for (int j = 0; j < i; j++){ //注意终止条件,需要放实数进行模拟确认
dp[i] += dp[j] * dp[(i - 1)- j]; //注意是 i - 1,也需要模拟确认
}
}
return dp[n];
}
};
总结
本题的递归方式又是自己一开始没想到。
同时递归里的 for 循环终止条件以及 dp 递推公式的值一开始也没想清楚没有写对,对于这种情况还是需要多放实际的数进行模拟确认