初识分布式锁(二):ZooKeeper分布式锁原理浅析及实战案例
初识分布式锁(二):ZooKeeper分布式锁原理浅析及实战案例
写作不易,点赞收藏关注以便下次再看,感谢爸爸们的支持~
上回咱们说到,用Mysql数据库实现了分布式锁。实现起来相对简单。
但是缺陷也相对比较明显,一方面是SQL锁没有过期机制,如果不保持高可用的情况下,线程没有释放掉锁就会出现死锁。
另一方面是因为SQL本身性能并不高,因此采用SQL加锁的方式会极大拖累整个系统的性能。
基于以上各点,本期咱们沿着Zookeeper展开,介绍如何使用Zookeeper实现相应的分布式锁。

Zookeeper简介
在开始咱的文章前,先来介绍下Zookeeper是个什么东西。咱们先来看下百度百科对于Zookeeper的定义是什么。
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper包含一个简单的原语集,提供Java和C的接口。
ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口,代码在$zookeeper_home\src\recipes。其中分布锁和队列有Java和C两个版本,选举只有Java版本。

换成比较通俗易懂的话来说,Zookeeper其实本质上就像一个文件管理系统。其用类似文件路径的方式管理、监听多个节点(Znode),同时判断当前每个节点上机器的状态(是否宕机、是否断开连接等),从而达到分布式协同的操作。
如下是ZK管理功能的一个简要说明。

四种节点
提到ZK,就不得不提一下ZK的四种基本节点,他们分别是:
- 持久化节点(PERSISTENT):该节点持久存在,不会因为客户端断开连接而删除。
- 持久化顺序节点(PERSISTENT_SEQUENTIAL):该节点会按照一定顺序持久存在,亦不会因为客户端断开连接而删除。
- 临时节点(EPHEMERAL):客户端断开连接后,该节点会被删除。
- 临时顺序节点(EPHEMERAL_SEQUENTIAL):客户端断开连接后该节点会被删除;会依照一定顺序进行排列。
这四种节点组成了最基本的ZK的功能。
事件监听
除了四种节点以外,不得不提一下ZK本身实现的Watcher(事件监听器),其是 ZooKeeper 中的一个很重要的特性。
ZooKeeper 允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是 ZooKeeper 实现分布式协调服务的重要特性。
同时,该机制也是分布式锁实现的重要依赖特性之一。
原理浅析
加锁原理:
ZK实现分布式锁主要依赖于上述的两个机制:
1、临时顺序节点。
2、事件监听。
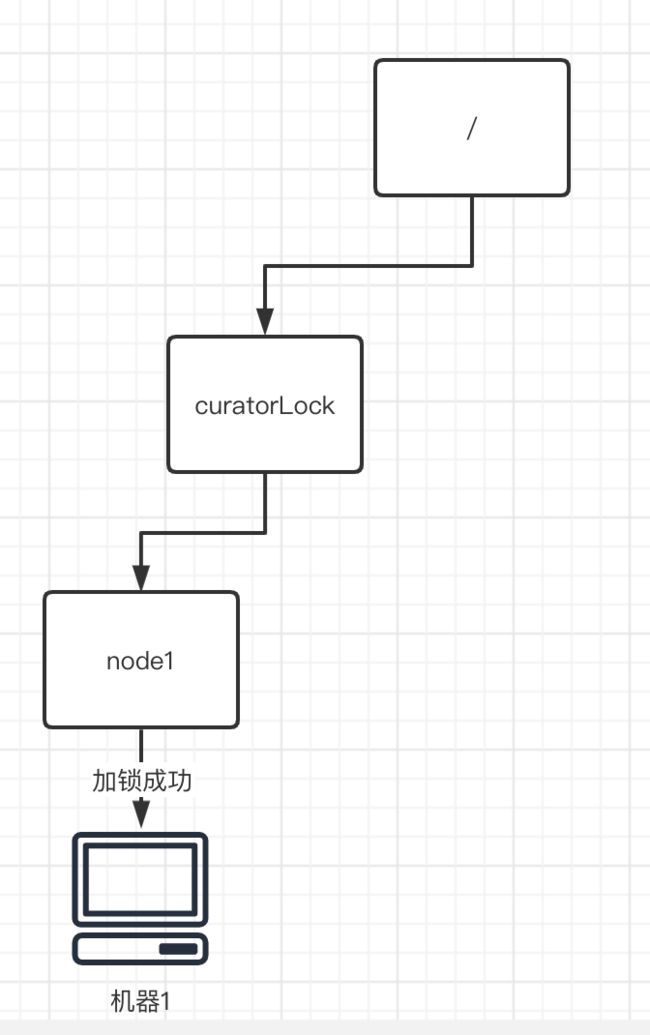
首先,每个程序需要加锁的时候,会需要一个相应的加锁路径(这里我们假设为“/curatorLock”),在ZK中根据这个加锁路径去生成一个新的临时节点node1。
假设当前新生成的临时节点a,为第一个临时节点。节点node1做为第一个申请锁的程序,自然是有权利进行上锁的,那么自然就是加锁成功了。
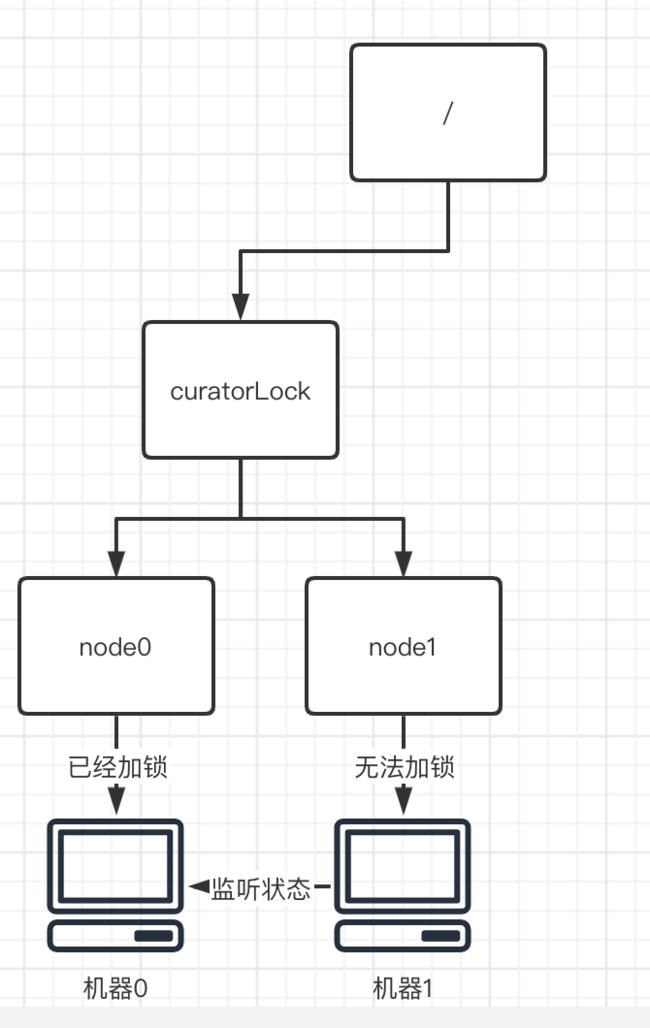
但是如果当前节点node1前面已经有了别的节点加了锁。那么这个时候显然我们是不能获取锁的,因此只能采用事件监听的机制,对前一个节点进行监听,直到前一个节点释放了锁。
三个乃至更多个节点的情况则相似。整个加锁的逻辑并不复杂。
解锁原理:
解锁的主要操作跟加锁相反,首先需要将当前监听自己的监听器都删除,从而告诉别的机器,“我用完锁啦~”。以便其余机器重新获取,或者重新设置监听对象和监听状态。
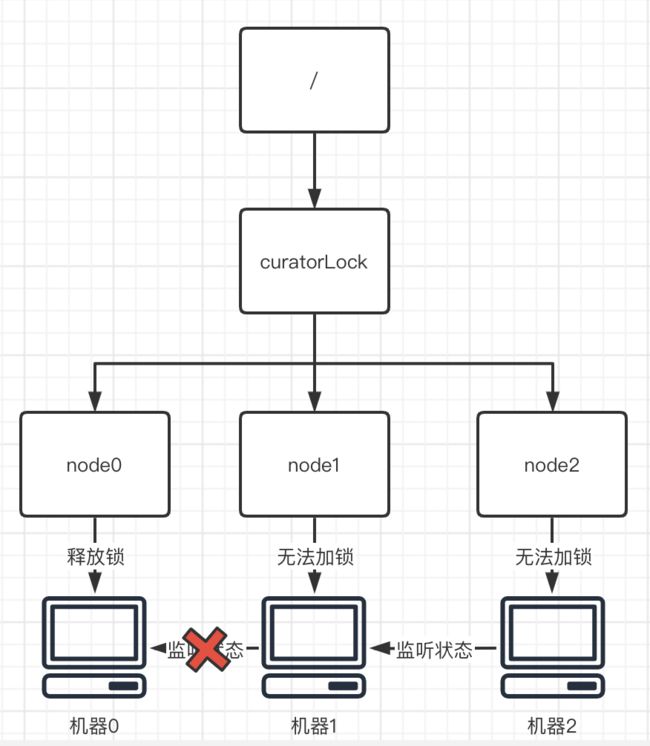
紧接着,获取着锁的节点(node0)会将自己进行删除,从而使得别的节点可以成为首节点,并进行加锁的操作。

由此一来,整个解锁的过程就实现了。

Zookeeper分布式锁实战
代码实现
这里我们借助CuratorFramework框架以及框架自带的InterProcessMutex互斥锁实现相应的逻辑。
@Component
@Slf4j
public class ZkClientUtil {
//zk连接ip
private final String zkServers = "你的zk服务器Ip";
private CuratorFramework curatorFramework;
// zk自增存储node
private String lockPath = "/curatorLock";
InterProcessMutex lock;
@PostConstruct
public void initZKClient(){
//如果等待时间 小于最大自旋时间则进行自旋
LOGGER.info(">>>>Zk连接中....");
ExponentialBackoffRetry retryPolicy = new ExponentialBackoffRetry(1000, 3);
curatorFramework = CuratorFrameworkFactory.builder()
.connectString(zkServers) //zk 服务地址
.sessionTimeoutMs(5000) // 会话超时时间
.connectionTimeoutMs(5000) // 连接超时时间
.retryPolicy(retryPolicy)
.build();
curatorFramework.start();
lock = new InterProcessMutex(curatorFramework, lockPath);
LOGGER.info(">>>>Zk连接成功!");
}
/**
* 获取对应的节点锁
*/
@SneakyThrows
public void getLock(){
//设置超时时间
boolean acquire = lock.acquire(50, TimeUnit.SECONDS);
if (acquire){
LOGGER.info("ZK加锁成功:"+Thread.currentThread().getId());
}else {
LOGGER.info("ZK加锁失败:"+Thread.currentThread().getId());
}
}
/**
* 对应节点进行解锁
*/
@SneakyThrows
public void unlock(){
lock.release();
LOGGER.info("ZK解锁成功"+Thread.currentThread().getId());
}
}
然后只需要对咱们原先的上一期代码做一点小小的改动~
@SneakyThrows
public synchronized Boolean deductProduct(ProductPO productPO){
CompletableFuture<Exception> subThread = CompletableFuture.supplyAsync(()->{
try{
zkClientUtil.getLock(); // 替换关键的加锁代码
....
}finally {
zkClientUtil.unlock(); // 替换关键的解锁代码
}
});
Exception exception = subThread.get();
if (exception !=null){
throw exception;
}
return true;
}
然后自豪的运行代码,就得到运行的结果如下:


可以看到结果确实是符合预期~

源码浅析
然而作为全宇宙最靓的崽,光学会用怎么能满足我呢,大家肯定也都好奇curatorFramework底层原理是咋实现的吧~
首先我们看看加锁部分,关键代码主要是acquire部分:
public boolean acquire(long time, TimeUnit unit) throws Exception {
return this.internalLock(time, unit);
}
acquire部分代码紧接着深入到internalLock方法中查看具体的逻辑。
private boolean internalLock(long time, TimeUnit unit) throws Exception {
Thread currentThread = Thread.currentThread();
// 从记录表中尝试获取线程的锁数据
InterProcessMutex.LockData lockData = (InterProcessMutex.LockData)this.threadData.get(currentThread);
if (lockData != null) {
// 数据不为空,实现重入,计数+1且返回加锁成功
lockData.lockCount.incrementAndGet();
return true;
} else {
// 数据为空,进行加锁操作 (关键代码,深入查看)
String lockPath = this.internals.attemptLock(time, unit, this.getLockNodeBytes());
if (lockPath != null) {
//将锁的记录保存到ThreadData中方便存储
InterProcessMutex.LockData newLockData = new InterProcessMutex.LockData(currentThread, lockPath);
this.threadData.put(currentThread, newLockData);
return true;
} else {
return false;
}
}
}
再追入尝试加锁的模块代码中,其中最关键的代码是createTheLock方法和internalLockLoop方法。
String attemptLock(long time, TimeUnit unit, byte[] lockNodeBytes) throws Exception{
final long startMillis = System.currentTimeMillis(); // 获取当前的系统时间
final Long millisToWait = (unit != null) ? unit.toMillis(time) : null; // 单位转换相同
final byte[] localLockNodeBytes = (revocable.get() != null) ? new byte[0] : lockNodeBytes;
int retryCount = 0;
String ourPath = null;
boolean hasTheLock = false;
boolean isDone = false;
while ( !isDone ){
isDone = true;
try{
/*关键方法>>>>> 根据path创建临时顺序节点并获取到节点相应路径*/
ourPath = driver.createsTheLock(client, path, localLockNodeBytes);
/*关键方法>>>>> 这里根据对应的锁的子节点,去判断对应要监视的对象*/
hasTheLock = internalLockLoop(startMillis, millisToWait, ourPath);
}catch ( KeeperException.NoNodeException e ){
if ( client.getZookeeperClient().getRetryPolicy().allowRetry(retryCount++, System.currentTimeMillis() - startMillis, RetryLoop.getDefaultRetrySleeper()) ){
//如果重试策略允许重试,则进行重试。
isDone = false;
}else{
throw e;
}
}
}
if ( hasTheLock ){
//如果持有锁了,则返回加锁加点的路径
return ourPath;
}
return null;
}
createTheLock方法,会创建一个临时顺序节点,以供后续的加锁使用。
@Override
public String createsTheLock(CuratorFramework client, String path, byte[] lockNodeBytes) throws Exception{
String ourPath;
if ( lockNodeBytes != null ) {
ourPath = client
.create()
.creatingParentContainersIfNeeded()
.withProtection()
.withMode(CreateMode.EPHEMERAL_SEQUENTIAL)
.forPath(path, lockNodeBytes);
}else{
ourPath = client
.create()
.creatingParentContainersIfNeeded()
.withProtection()
.withMode(CreateMode.EPHEMERAL_SEQUENTIAL)
.forPath(path);
}
return ourPath;
}
internalLockLoop方法,会首先根据当前锁的路径获取对应子节点(即已经上锁的节点),紧接着会根据一个关键变量maxLeases(默认为1,大概率可以通过修改maxLeases来控制一把锁是否可以多人同时获取),来判断当前的节点能否获取分布式锁。
如果这个时候,子节点数组的长度超过了maxLeases,那么我当前节点没法获取到锁,也就需要对数组长度length-maxLeases的节点进行监听,以期待获取相应的锁。同时,该组件还对超时的情况做了特殊的处理,以避免死锁或不断等待的情况出现。
private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception{
boolean haveTheLock = false;
boolean doDelete = false;
try{
if ( revocable.get() != null ){
client.getData().usingWatcher(revocableWatcher).forPath(ourPath);
}
while ( (client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock ){
List<String> children = getSortedChildren();
String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash
PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);
if ( predicateResults.getsTheLock() ){
haveTheLock = true;
} else{
String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();
synchronized(this){
try{
client.getData().usingWatcher(watcher).forPath(previousSequencePath);
if ( millisToWait != null ){
millisToWait -= (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
if ( millisToWait <= 0 ){
doDelete = true; // 监听超时了,节点会自动释放,避免死锁
break;
}
wait(millisToWait);
}
else{
wait();
}
}
catch ( KeeperException.NoNodeException e ){
// it has been deleted (i.e. lock released). Try to acquire again
}
}
}
}
}catch ( Exception e ){
ThreadUtils.checkInterrupted(e);
doDelete = true;
throw e;
}finally{
if ( doDelete ){ //超时or报错了,会将节点删除
deleteOurPath(ourPath);
}
}
return haveTheLock;
}
由此一来,整个加锁的逻辑就比较清晰了。
解锁:
解锁部分的代码基本类似。源代码如下:
public void release() throws Exception{
Thread currentThread = Thread.currentThread();
LockData lockData = threadData.get(currentThread);
if ( lockData == null ){
throw new IllegalMonitorStateException("You do not own the lock: " + basePath);
}
int newLockCount = lockData.lockCount.decrementAndGet();
if ( newLockCount > 0 ){
return;
}
if ( newLockCount < 0 ){
throw new IllegalMonitorStateException("Lock count has gone negative for lock: " + basePath);
}
try{
internals.releaseLock(lockData.lockPath);
}finally{
threadData.remove(currentThread);
}
}
首先是会根据当前线程从记录表中去获取其对应的锁信息,如果锁信息不存在,抛出异常。
如果锁信息存在,首先判断其是否重入了,如果是重入锁,则计数-1。
否则的话,执行释放锁的操作,这里就是先删除节点下对应的所有观察者,然后将临时节点删除点,完成锁的释放。
final void releaseLock(String lockPath) throws Exception
{
client.removeWatchers(); // 移除观察者
revocable.set(null);
deleteOurPath(lockPath); // 删除对应路径的锁
}
由此,整个加锁解锁的流程就全部解析完啦~
优劣性分析
优点:
- ZK现成的框架支持相对完善,使用起来较为方便,而且支持了超时删除锁的机制,避免了可能出现的死锁。
- curatorFramework本质是一种按照创建顺序排队的实现。这种方案效率高,避免了“惊群”效应,当锁释放时只有一个客户端会被唤醒。
- ZK天生设计就是分布式协调,强一致性。锁的模型健壮、简单易用、适合做分布式锁。
- ZK实现分布式锁时,如果节点获取不到锁,只需添加监听器即可,不用一直轮询,性能消耗较小。
缺点:
- ZK为了保持高一致性,会导致在集群leader挂掉的情况下,重新选举的算法相对耗时较久,因此可能导致在较长的一段时间内,加锁、解锁的逻辑是不可用的。
- 如果有较多的客户端频繁的申请加锁、释放锁,对于zk集群压力较大。
参考文献
分布式锁之Zk(zookeeper)实现
你还在使用复杂的 zkclient 开发 zookeeper 么?是时候用 Curator 了 !
肝一下ZooKeeper实现分布式锁的方案,附带实例!
七张图彻底讲清楚ZooKeeper分布式锁的实现原理【石杉的架构笔记】