IO多路复用和Reactor模型
目录
- 1.同步阻塞式IO - BIO
- 2.同步非阻塞式IO - NIO
-
- 2.1 Selector 选择器
-
- 2.1.1 SelectionKey
- 2.1.2 Selector注册事件类型
- 2.2 Channels 通道
- 2.3 Buffer 缓冲区
-
- 2.3.1 Capacity
- 2.3.2 Position
- 2.3.3 Limit
- 2.3.4 Buffer缓冲区的分配
- 3.Reactor模型
-
- 3.1 单Reactor单线程模型
-
- 3.1.1 单Reactor单线程模型的优点
- 3.1.2 单Reactor单线程模型的缺点
- 3.2 单Reactor多线程模型
- 3.3 多Reactor多线程模型(主从Reactor模型)
1.同步阻塞式IO - BIO
BIO就是Blocking IO的简称,Java中BIO是由ServerSocket负责绑定IO地址启动监听端口等待客户端连接。客户端的Socket类发起连接。
BIO的阻塞主要体现在:
- 服务端程序启动后,会一直等待客户端的连接,在此期间线程是阻塞的,不能干其他的事。
- 在连接建立后,在读取到socket数据之前,线程仍然是阻塞状态。
2.同步非阻塞式IO - NIO
NIO是JDK1.4版本引入的,NIO弥补了BIO的种种不足,BIO是面向字节流,而NIO则是面向缓冲区。
BIO在调用read、write等方法时,线程会阻塞,直到有数据到达。NIO的非阻塞模式下,线程从某个通道读取数据,如果没有可用的数据时候就不会阻塞,可以去做其它事情。一个独立的线程管理多个输入和输出通道,这样可以将阻塞等待时间拿来在其它通道上执行IO操作。
NIO有三大核心组件:
2.1 Selector 选择器
Selector选择器又称为事件订阅器、轮询代理器,Java的NIO的Selector选择器允许一个单独的线程来监视多个通道,然后使用一个单独的线程拿来操作这个选择器。
客户端向Selector注册它所关注的某个通道Channel以及关注的哪些事件(例如连接事件、读取事件等),当然Selector中会维护一个Channel列表。
2.1.1 SelectionKey
这个key代表channe通道在Selector上注册的唯一标识。
2.1.2 Selector注册事件类型
- `OP_READ 读事件`:当读缓冲区有数据可读时触发的事件。
- `OP_WRITE 写事件`:当写缓冲区有空间空间时触发的事件。
- `OP_CONNECT 连接事件`:#connect( ) 请求连接成功后触发的事件,给客户端使用。
- `OP_ACCEPT 连接请求事件`:#accetp( ) 当接收到一个客户端连接请求时触发的事件,给服务端使用。
2.2 Channels 通道
channel通道,是对应用程序和操作系统交互数据通道的抽象。应用程序可以通过通道读取数据也可以通过通道向操作系统写入数据。
2.3 Buffer 缓冲区
JDK的NIO是面向缓冲区的,这个Buffer就是缓冲区,用于和通道进行交互。
数据从Channel读入缓冲区,也可以从缓冲区写入通道。Buffer的本质其实就是字节数组,JDK提供了一系列的方法来操作访问这个Buffer对象。
2.3.1 Capacity
代表Buffer缓冲区的容量。
2.3.2 Position
代表当前写入数据的相对偏移量。
2.3.3 Limit
写模式下,limit代表最多能往Buffer里面写多少数据,此时limit == capacity。
读模式下,limit代表最多能读多少数据。
2.3.4 Buffer缓冲区的分配
- `HeapByteBuffer`:在JVM的堆空间中分配,在发送阶段会先从堆空间拷贝到直接内存,然后再通过操作系统的内核态切换和拷贝到网卡缓冲区。
- `DirectByteBuffer`:直接分配在直接内存,性能上相对于堆内存更快,但是在大容量或者频繁的申请直接内存可能导致性能下降。
3.Reactor模型
Reactor模型是对事件处理流程的一种模式抽象,是对IO多路复用模式的一种封装,Reactor又叫反应器,在这里特指的是对各种事件的反应处理。Reactor模型有2个重要的组件:
- `Reactor`:专门用于监听和响应各种IO事件,例如连接事件、读事件、写事件等,当检测到有一个新的事件发生时,就会交给相应的Handler去处理。
- `Handler`:专门用来处理特定的事件的执行者。
3.1 单Reactor单线程模型

1. 服务端的Reactor线程对象,不断循环监听各种IO事件,还会注册一个accepter的特殊Handler到Reactor中,这个accepter专门负责处理连接的事件。
1. 客户端发起请求,服务端的Reactor监听到accept事件,然后将这个accept事件分派给accepter组件,accepter组件通过#accept( )方法和客户端建立对应的channel。然后将这个连接所关注的read事件注册到Reactor中,这样Reactor就会监听read事件的发生。
1. 当服务端Reactor监听到read事件,将这个read事件发送给对应的读请求Handler进行数据的读取。
3.1.1 单Reactor单线程模型的优点
最基础的Reactor模型,实现简单,不用考虑并发问题。JDK的NIO的Selector选择器就是最简单的单Reactor单线程模型。
3.1.2 单Reactor单线程模型的缺点
Reactor和Handler的所有操作都是在同一个线程中完成的,无法充分利用多核优势,性能不佳。
Redis6.0之前就是典型的单Reactor单线程模型,虽然6.0以后引入了多线程,但是它的多线程只是用来处理耗时的网络IO操作上,实际执行命令的Handler仍然是单线程。
3.2 单Reactor多线程模型
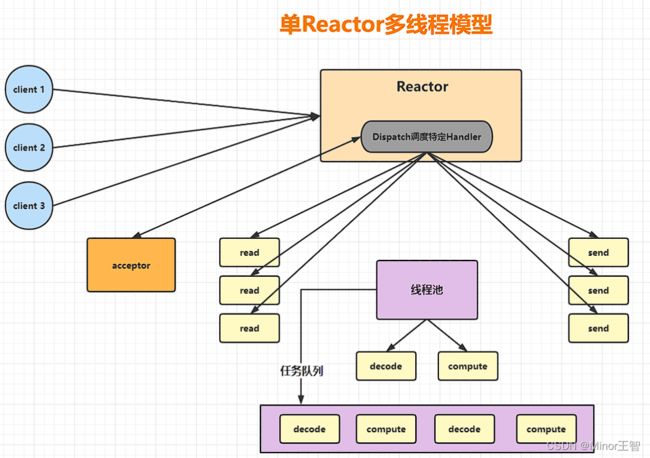
大体上单Reactor多线程模型和基本的单Reactor单线程模式差不多,只不过单Reactor多线程模型多引入了一个线程池,这个线程池负责将一些非IO操作的事件进行处理,例如计算、编解码任务等。
虽然这种模式下引入了线程池,效率得到了一定的提升,但是毕竟是采用单Reactor架构,所有的事件都是交给单个Reactor负责,在面对瞬间的高并发连接场景,单Reactor多线程模型仍然性能不佳。
3.3 多Reactor多线程模型(主从Reactor模型)
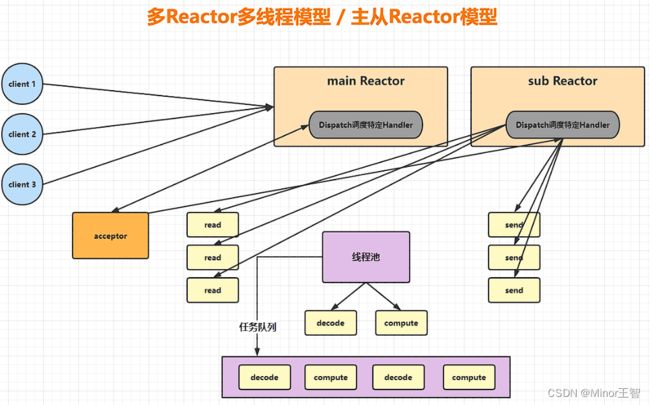
为了优化单Reactor模型的性能瓶颈,将原来单独的Reactor的功能进行分解为连接处理器和通信处理器,由多个不同的Reactor共同完成网络通信任务。
- 主Reactor拥有自己的Selector,通过select监控连接事件,事件发生后交给acceptor组件处理,然后acceptor组件将连接分配给某一个从Reactor。
- 从Reactor也有自己的Selector,从Reactor监听并执行读、写等事件。
- 线程池的任务没有变化,负责处理非IO的事件任务,例如编解码序列化、计算等。
- 主从Reactor模型中,主Reactor和从Reactor都可以存在多个,每个Reactor都有自己的Selector,都是独立的线程工作,这样充分利用了多核CPU的优势。
但是多Reactor多线程架构仍然不能根治IO操作对其他Client的效能影响,毕竟有可能某个从Reactor可能有多个client的连接。所以诞生了异步IO模型的Proactor模型来实现真正的异步IO。
Netty、Memcached、Nginx都是采用的多Reactor多线程的模型。不过Netty支持多种Reactor模型的配置。