Redis分布式锁各版本源码分析
Redis分布式锁各版本的源码实践解读)
文章目录
- 前言
- 一、v1 初出茅庐
- 二、v2 小心死锁
-
- 1. 业务逻辑异常导致死锁
- 2. 服务宕机导致死锁
- 三、v3 彻底搞定死锁
- 四、v4 解铃还需系铃人
- 五、v5 解锁 - 原子性
- 六、v6 可重入性
- 七、v7 锁等待
- 八、v8 锁等待 - 优化
- 测试
- 最后
-
- 锁超时问题
- 锁丢失问题
- RedLock
前言
与分布式锁相对应的是本地锁,像我们熟悉的synchronized和ReentrantLock都是本地锁,本地锁是作用于JVM内部,单个进程内的操作共享资源互斥。而现在主流都是分布式和微服务架构,会部署多个服务(多个JVM),为此分布式锁也就应运而生了。
分布式锁主流实现有3种:基于Redis、Zookeeper或Mysql等数据库。
Redis实现分布式锁使用得非常广泛,也是面试的重要考点之一,很多同学都知道这个知识,也大致知道分布式锁的原理,但是具体到细节的掌握上,往往并不完全正确。所以下面就让我们手写Redis分布式锁,以版本迭代的方式,渐进式的解读遇到的问题和对应的解决方案,帮你彻底理解Reids分布式锁。
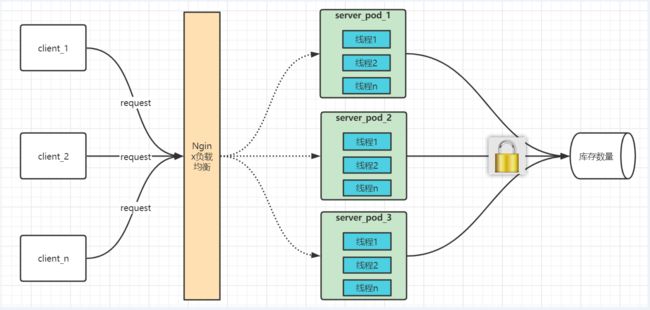
一、v1 初出茅庐
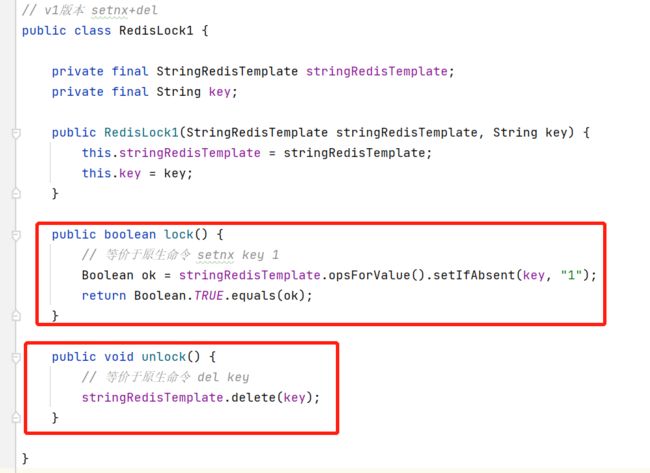
setnx (SET if Not eXists) 命令在指定的 key 不存在时,为 key 设置指定的值。
两个客户端进程可以执行这个命令,达到互斥,就可以实现一个分布式锁。
基本语法:setnx key value 例如两个进程同时加锁,只能成功1个:


释放锁,直接使用 DEL 命令删除这个 key 即可:

基于这个思路,使用RedisTemplate我写下了v1版本的实现代码:
模拟减库存调用如下:

二、v2 小心死锁
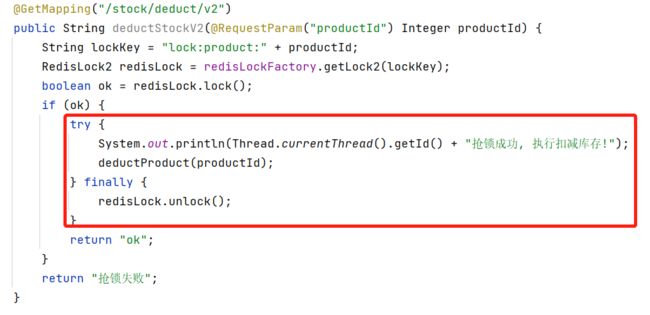
1. 业务逻辑异常导致死锁
解决方案:当lock成功后,对执行的业务逻辑加try finally,保证即使业务逻辑异常,也可以unlock。
2. 服务宕机导致死锁
在执行业务逻辑时,虽然我们加了try finally,但假设获得锁的服务宕机,还没有来的及解锁,那么这个锁将一直被占有,其它客户端也将永远拿不到这个锁了。
解决方案:设置过期时间,服务宕机的话key也会在指定时间内自动过期,不会永远占有锁。
我们修改lock方法,对key加上expire 10s:
public boolean lock() {
// 等价于原生命令 setnx key 1
Boolean ok = stringRedisTemplate.opsForValue().setIfAbsent(key, "1");
boolean res = Boolean.TRUE.equals(ok);
if (res) {
// 等价于原生命令 expire key 10
stringRedisTemplate.expire(key, 10, TimeUnit.SECONDS);
}
return res;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
三、v3 彻底搞定死锁
v2的思路是对的,但是这里还有个小问题,如果setnx成功但expire失败呢? 依然会有死锁的可能,这个问题的根源在于setnx和expire是两条指令而不是原子指令,所以解决原子性问题我们可以采用lua脚本,详见我写的 Redis使用Lua脚本:保证原子性【项目案例分享】
另外,在Redis2.8版本中,作者加入了set指令的扩展参数ex nx,使得setnx和expire指令可以一起执行:
基本语法: set key value ex secords nx 例如:

我们修改lock方法如下:
public boolean lock() {
// 等价于原生命令 set key 1 ex 10 nx
Boolean ok = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
return Boolean.TRUE.equals(ok);
}
- 1
- 2
- 3
- 4
- 5
这样就彻底解决了死锁问题
四、v4 解铃还需系铃人
上面代码里的unlock方法只是单纯的删除key,这样的代码是不安全的,如果占有锁的线程还在执行业务逻辑,这时被未上锁的线程调用了unlock释放了锁,可想而知,那么这时其它线程就又可以抢锁成功了,结果就不正确了,所以我们要确保解锁还需上锁线程。
解决方案:对每个锁对象生成唯一的id,加锁时保存在value中,解锁时需要判断value=id再解锁。
我们修改代码如下:

五、v5 解锁 - 原子性
其实unlock还是会有一点小问题的,因为unlock时GET + DEL 是两条指令,又会遇到我们前面讲的原子性问题了。假设持有锁的进程在del之前锁过期自动释放了,这时马上被其它线程加锁了,那么此时再删除就会把别人刚加的锁删除了。
我们修改成执行lua脚本方式:
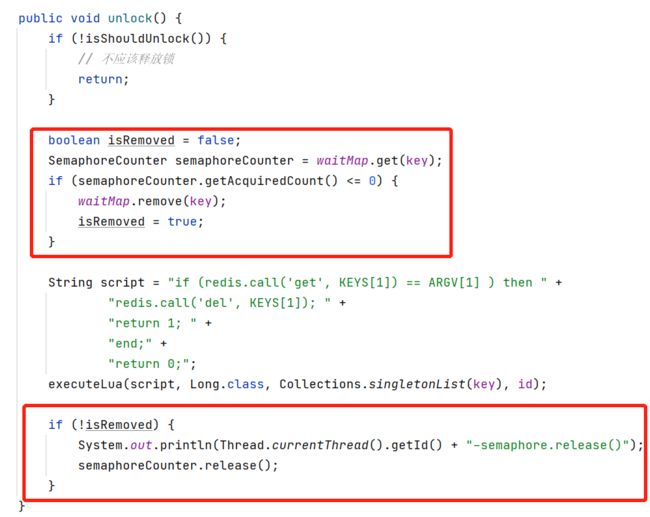
public void unlock() {
String script = "if (redis.call('get', KEYS[1]) == ARGV[1] ) then " +
"redis.call('del', KEYS[1]); " +
"return 1; " +
"end;" +
"return 0;";
executeLua(script, Long.class, Collections.singletonList(key), id);
}
private <T> T executeLua(String script, Class<T> resultType, List<String> keys, Object... args) {
RedisScript<T> redisScript = new DefaultRedisScript<>(script, resultType);
RedisSerializer<String> argsSerializer = new StringRedisSerializer();
RedisSerializer<T> resultSerializer = new Jackson2JsonRedisSerializer<>(resultType);
return (T) stringRedisTemplate.execute(redisScript, argsSerializer, resultSerializer, keys, args);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
至此,解锁的流程就更严谨了
六、v6 可重入性
接下来,我们做一个完善:可重入。
可重入性是指线程在持有锁的情况下再次请求加锁,如果一个锁支持同一个线程的多次加锁,那么这个锁就是可重入的。比如synchronized和ReentrantLock就是可重入锁。
对于可重入性的解决方案:加锁时,增加锁的持有计数; 释放锁时,减少锁的持有计数。
对于锁的持有计数保存在哪?一般会保存在本地,或者Redis服务端。
- 本地使用ThreadLocal或全局静态变量保存锁的持有计数
- Redis端将持有计数保存在value中
对于方案2是开源框架Redisson的RedissonLock的解决方案,但是可重入性是在本地就能解决的,所以为了更好的性能我们采用方案1。
增加一个全局静态变量Map:
// 可重入map:key= this.key+threadId; value=重入次数
private final static ConcurrentHashMap<String, AtomicInteger> refMap = new ConcurrentHashMap<>();
- 1
- 2
加锁:
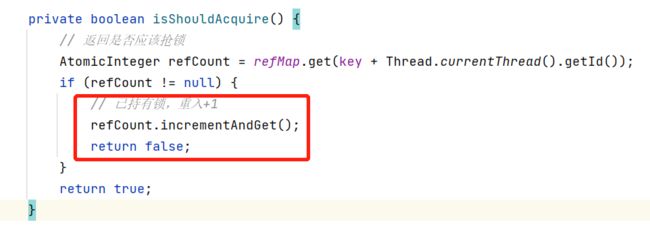
加锁前调用isShouldAcquire判断是否应该抢锁,加锁成功将持有计数放入refMap
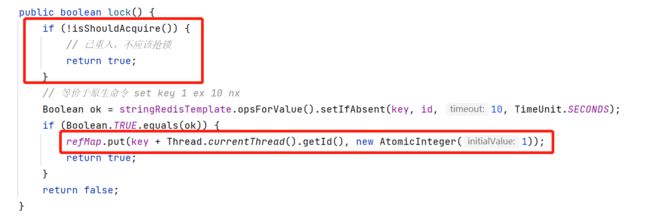
isShouldAcquire方法如下:加锁时如果发现该线程已持有锁,refCount++
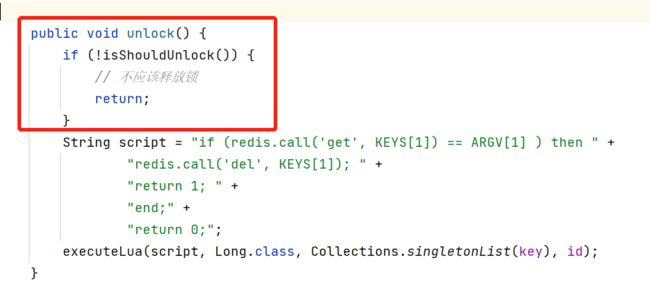
解锁:
解锁前调用isShouldUnlock判断是否应该释放锁
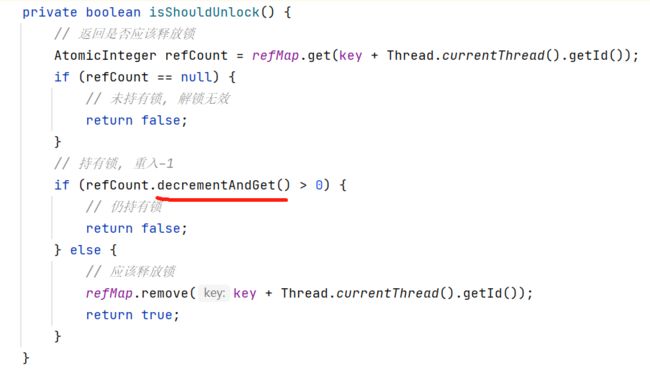
isShouldUnlock方法如下:解锁时如果发现该线程已持有锁,refCount--,减1后如果refCount仍大于0,说明是仍持有锁,不应该释放锁。如果需要释放锁,应从refMap中移除。
至此,我们手写的分布式锁就支持可重入了
七、v7 锁等待
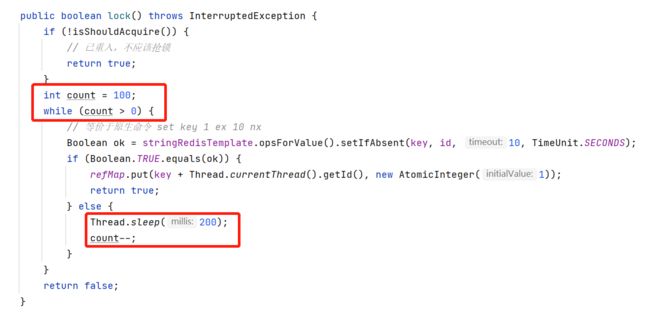
我们抢锁往往不是一锤子买卖,需要不断重试抢锁,直到成功,所以我们来尝试写一个最简单的锁等待,方案就是使用循环 + Thread.sleep不断重试抢锁
八、v8 锁等待 - 优化
上面的锁等待,运行结果没问题,可能性能稍微差了一点,所以我们做一下优化。
优化方案:
- 使用
Redis的订阅发布功能,锁等待的线程订阅channel,持有锁的线程释放锁时发布channel - 使用
Semaphore,当锁释放时,通知本进程的锁等待线程。其它进程的锁等待线程依然使用Thread.sleep。
对于方案2是开源框架Redisson的RedissonLock的解决方案,由于引入了订阅发布channel,提高了复杂了度,另外由于Redis发布订阅功能不能持久化,有可能丢失,所以权衡过后为了更稳定我们采用方案2。
这里更改的点较多,慢慢品味:
先增加一个Semaphore计数器,目的是当没有锁等待时,能将Semaphore释放。
static class SemaphoreCounter { private final Semaphore semaphore = new Semaphore(0); private final AtomicInteger acquireCount = new AtomicInteger(0);public void tryAcquire(long timeout, TimeUnit unit) throws InterruptedException { acquireCount.incrementAndGet(); semaphore.tryAcquire(timeout, unit); acquireCount.decrementAndGet(); } public int getAcquiredCount() { return acquireCount.get(); } public void release() { semaphore.release(); }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
再增加一个全局静态变量Map:记录当前key的SemaphoreCounter
// 锁等待map:key= this.key; value=信号量
private static final ConcurrentHashMap<String, SemaphoreCounter> waitMap = new ConcurrentHashMap<>();
- 1
- 2
加锁:
加锁成功,将SemaphoreCounter放入waitMap
加锁失败,如果map中有key,说明本进程其它线程持有锁,使用Semaphore等待锁释放,否则使用Thread.sleep

解锁:
正式解锁前,判断如果本进程没有锁等待,将key从waitMap移除
解锁后:使用Semaphore通知其它等待线程
至此,我们手写的分布式锁就支持锁等待了,我们手写的功能就大功告成了
测试
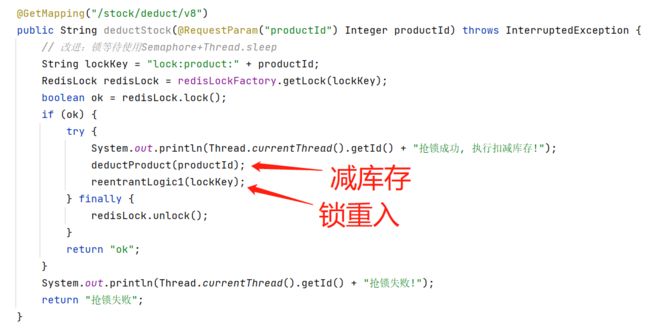
我们的共享资源就以内存中减库存为例 (如果分布式锁有效,就不会超卖)
private void deductProduct(Integer productId){
String count = stringRedisTemplate.opsForValue().get("product:count:" + productId);
// 假设现在库存1000:内存里--,如果没有分布式锁,就是出现超卖的情况
int newCount = count == null ? 999 : (Integer.parseInt(count) - 1);
stringRedisTemplate.opsForValue().set("product:count:" + productId, String.valueOf(newCount));
}
- 1
- 2
- 3
- 4
- 5
- 6
用Springboot开放一个API:
我们设置一下库存productId为1的库存为1000

用Nginx部署两个实例,用Jmeter测一下:
100个线程在1秒钟之内发起减库存:
最终也在1秒之内结束。
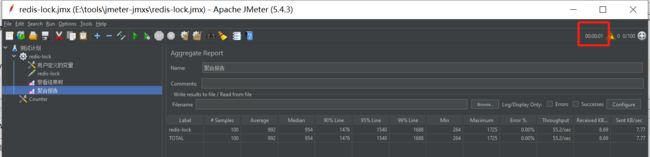
我们看下结果是否正确:
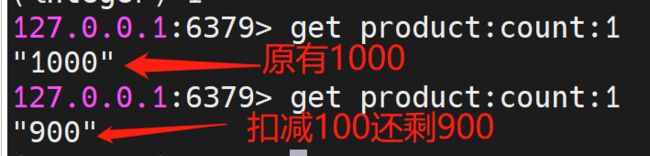
我们再看下两个实例的执行情况(也正是抢到锁100次):
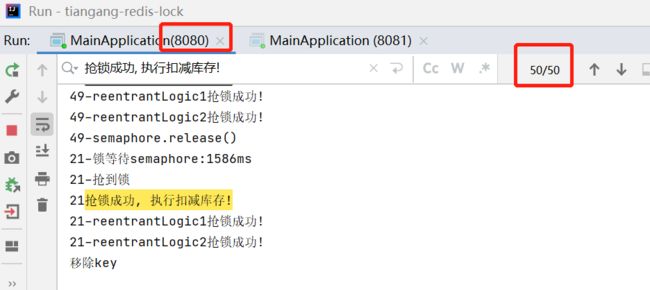
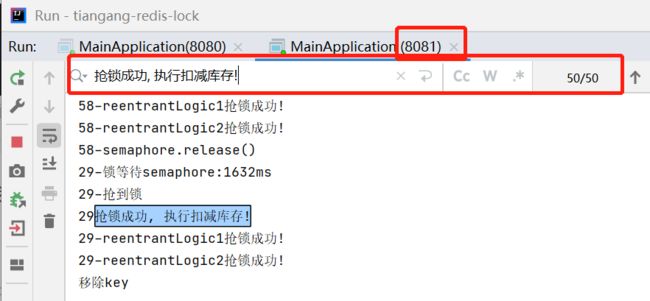
最后
锁超时问题
如果在加锁和释放锁之间的逻辑执行的时间太长,以至于超出了锁的超时限制,就会出现问题。因为这时侯第一个线程持有的锁过期了,逻辑还没有执行完,而同时第二个线程就提前重新持有了这把锁,导致可能2个线程同时持有一把锁,问题就出现了。
我觉得这是一个棘手的问题,也是一个架构上的问题,笔者也确实没有打算解决它,不要看我的代码里只写了10s的超时时间,正式用的话这个超时时间是需要做成参数来配置的,是需要提供一个方法来重载的,提供更高的灵活性,因为总可能有一些特殊场景是需要特殊处理的。
我的建议是Redis分布式锁不要用于较长时间的任务,在使用分布式锁时我们也应该尽可能缩小锁的控制范围,尽量细粒度,尽可能设置长一些的超时时间,根据你的业务评估一个足够长的过期时间,比如你们业务逻辑普遍都执行在10秒以内,那过期时间设置30秒就差不多了,如果你就是担心,那设置成100秒也是OK的。
当然,这里还有一个解决方案:Redisson帮我们实现的看门狗机制,锁自动延期。关于它的原理简单来说是这样的:抢到锁的线程开启一个守护线程,默认30秒超时,定时每10秒检测一下,如果逻辑未执行完就将锁超时间重新修改为30秒。
这个方案实际要考虑的细节很多,说起来容易但想完善还真不容易,所以我们要感谢Redisson
锁丢失问题
锁超时我们可以避免,但是锁丢失才是Redis做分布式锁的致命缺陷,是无法100%解决的。这里需要提前一些 Redis持久化和 Redis主从复制原理的知识。
单节点:
- 线程1通过SET命令加锁成功
- 此时,单节点宕机,SET命令尚未持久化
- 节点恢复后,线程1依然在执行,但这个锁因为尚未持久化已经无法恢复了,所以其它线程也可以获得锁了
主从/哨兵/集群: 都是基于主从,所以都是一样的问题
- 线程1通过SET命令加锁成功
- 此时,Master节点宕机,SET命令尚未主从复制给Slave节点
- Slave节点通过人工或选举做了Master,线程1依然在执行,但这个锁因为尚未同步,所以在新的Master上丢失了!所以其它线程也可以获得锁了
RedLock
怎么解决这个锁丢失问题?
为此,Redis 的作者提出一种解决方案,就是我们经常听到的 Redlock(红锁)。
Redlock 的方案基于 2 个前提:
- 不再需要部署从库和哨兵实例,只部署主库
- 但主库要部署多个,官方推荐至少 5 个实例
也就是说,想用使用 Redlock,你至少要部署 5 个Redis 实例,而且都是主库,它们之间没有任何关系,都是一个个孤立的实例。
然后客户端依次发起加锁,半数以上加锁成功视为加锁成功。
但是,这个方案依然是可能出现锁丢失的,例如现5个Redis实例:A+B+C+D+E:
线程1加锁成功3个节点:A+B+C,拿到锁,刚好这3个中的C节点宕机了,还刚好尚未持久化,会不会有?但此时线程1依然在执行业务逻辑中…
而线程2这时也抢到3个加锁成功节点:D+E+C,这个C是宕机恢复的
所以,无论如何Redis分布式锁是无法100%安全的!但那只是极小概率的,可能一般的业务场景是无法遇到的,所以用Redis做分布式锁的应用仍然非常广泛。
最好的关系是互相成就,大家的「三连」就是我创作的最大动力!
注:如果本篇博客有任何错误和建议,欢迎大佬们留言!