LeetCode193.有效电话号码
项目场景:
小白第一次做这种题,学到了!
问题描述
- 有效电话号码
给定一个包含电话号码列表(一行一个电话号码)的文本文件 file.txt,写一个单行 bash 脚本输出所有有效的电话号码。
你可以假设一个有效的电话号码必须满足以下两种格式: (xxx) xxx-xxxx 或 xxx-xxx-xxxx。(x 表示一个数字)
你也可以假设每行前后没有多余的空格字符。
示例:
假设 file.txt 内容如下:
987-123-4567
123 456 7890
(123) 456-7890
你的脚本应当输出下列有效的电话号码:
987-123-4567
(123) 456-7890
原因分析:
-
思路:
题目的核心是匹配符合规则的字符串,因为规则比较单一,所以使用正则表达式来检索符合要求的字符串即可。 -
规则分析
(xxx) xxx-xxxx 或 xxx-xxx-xxxx。(x 表示一个数字)
从规则中可以看出,只要符合上述形势的数字组合即可。
分析 (xxx) xxx-xxxx
我们把其中的规律列出来,找出固定的字符位置与可变字符的规律。
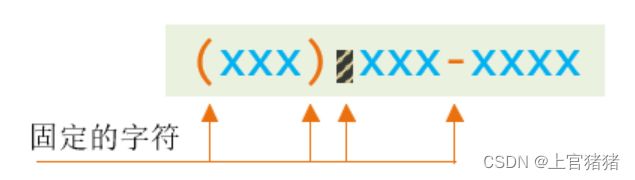
最终需要用正则表达式中的普通字符、特殊字符、限定符、定位符来描述对应的规律(如上图所示)
- 使用正则表达式描述规律
个人感觉,正则表达式的重点有三:特殊字符、限定字符、定位符
熟练掌握这三点,大部分的正则表达都不在话下~
特殊字符:勿忘加上转义符’’
限定字符:限定字符出现的次数,掌握它也就get了精华,麻麻再也不用担心我读不懂漂亮的表达式了。
定位符:稍加理解,就能get到的好技巧
3.1 使用正则表达式描述上面的内容
表达 (xxx) xxx-xxxx
^([0-9][0-9][0-9]) [0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]$
使用限定符来限定数字出现的次数,优化为如下表达
^([0-9]{3}) [0-9]{3}-[0-9]{4}$

表达 xxx-xxx-xxxx
^ [0-9][0-9][0-9]-[0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]$
使用限定符来限定数字出现的次数,优化为如下表达
^ [0-9]{3}-[0-9]{3}-[0-9]{4}$
Note: 使用标准的POSIX表达式中未定义\d表示数字,需要使用“扩展正则”的方式才行。例如sed和grep都支持此表达方式。
同时表示xxx-xxx-xxxx和 (xxx) xxx-xxxx
使用特殊字符()和|。用()来标记一个表达式,使用|来指明两项之间的任意选择。
xxx-xxx-xxxx和 (xxx) xxx-xxxx
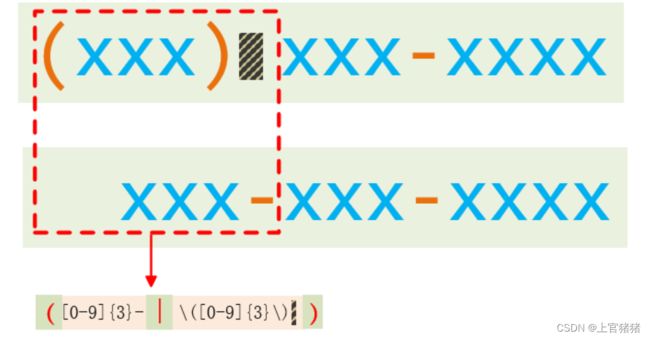
最终表达式如下:
^([0-9]{3}-|([0-9]{3}) )[0-9]{3}-[0-9]{4}$
- grep与awk
grep
grep -P ‘^([0-9]{3}-|([0-9]{3}) )[0-9]{3}-[0-9]{4}$’ file.txt
awk/gawk
awk ‘/^([0-9]{3}-|([0-9]{3}) )[0-9]{3}-[0-9]{4}$/’ file.txt
或者
gawk ‘/^([0-9]{3}-|([0-9]{3}) )[0-9]{3}-[0-9]{4}$/’ file.txt
- 附加快速查看表
为了方便查看,列出对应的特殊字符表以及表达方式
特殊字符 表达
特殊字符 转义表达 特殊含义
() () 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用
$ $ 匹配输入字符串的结尾位置
-
\* 匹配前面的子表达式零次或多次
-
\+ 匹配前面的子表达式一次或多次
. . 匹配除换行符 \n 之外的任何单字符
[ ] [] 标记一个中括号表达式的开始。要匹配 [,请使用 [。
? ? 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符
\ \ 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符
^ ^ 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合
{} {} 标记限定符表达式的开始
| | 指明两项之间的一个选择
限定符表达
Note 表含义中的出现次数:限定符前面字符的出现次数。
限定符 表达含义
* 出现次数>=0
+ 出现次数>=1
? 出现次数 0 or 1, 等价{0,1}
{n} 出现次数=n
{n,} 出现次数>=n
{n, m} n=< 出现次数<= m
定位符
定位符 表达含义
^ 字符串开始的位置
$ 字符串结束的位置
\b 限定单词(字)的字符,常用来确定一个单词,可以结合两个‘\b’使用
\B 限定非单词(字)边界的字符,用的很少
解决方案:
朝闻道,夕可眠矣
grep
grep -P '^([0-9]{3}-|\([0-9]{3}\) )[0-9]{3}-[0-9]{4}$' file.txt
awk
awk '/^([0-9]{3}-|\([0-9]{3}\) )[0-9]{3}-[0-9]{4}$/' file.txt
gawk
gawk '/^([0-9]{3}-|\([0-9]{3}\) )[0-9]{3}-[0-9]{4}$/' file.txt