python-文章相似度计算
python-文章相似度计算
编写一个程序,设计实现以下函数并实现整体功能(文章相似度计算):
1.0 word_input_file(file):输入文本文件路径(如input.txt),返回该文档的合理表示(用于以下任务)
1.1 word_tf_df(sentences,word):输入文章列表、词,输出该词的词频、文档频率
1.2 word_cosine_similarity(sentences,sentence1,sentence2):输入文章列表、文章1、文章2,输出文章1和文章2的相似度(即相似的程度,使用余弦相似度【可搜索相关概念】)’’’
读取文章列表
def get_article_list(path):
"""
从文件中读取文章列表:
path: 文件路径
return: (返回列表list[]/元组tuple())
"""
file = open(path, encoding='utf8')
res = []
# 定义一个空列表
for line in file:
list1 = line.split(' ')
res.append(list1[1])
# 每一行新闻加入列表当作一个字符串
return tuple(res)
# 列表转换成元组,加上'tuple’
articles = get_article_list('../day2/input.txt')
获取文章的词
# 返回词袋,所有文章的词(不重复的)->tuple
def get_bag(article_list):
"""
返回文章列表词袋
:article_list:文章列表
:return:词袋
"""
# 定义一个空集合,集合可以去重
res = set()
for article in article_list:
word_list = article.split(' ')
for word in word_list:
res.add(word)
return tuple(res)
bag = get_bag(articles)
获取文章的词频
# 获取一篇文章的TF,使用词袋中的词的对应->tuple
def get_article_tf(article, bag):
"""
返回一篇文章的TF
:param article:一篇文章
:return:TF
"""
word_list = article.split(' ')
word_count_dic = {}
for word in word_list:
if word_count_dic.get(word) is None:
word_count_dic[word] = 1
else:
word_count_dic[word] += 1
res = []
for word in bag:
if word_count_dic.get(word) is None:
res.append(0)
else:
res.append(word_count_dic.get(word))
return tuple(res)
tf1 = get_article_tf(articles[0], bag)
tf2 = get_article_tf(articles[1], bag)
计算两篇文章的相似度
余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度。给定两个属性向量,A和B,其余弦相似性θ由点积和向量长度给出,如下所示:
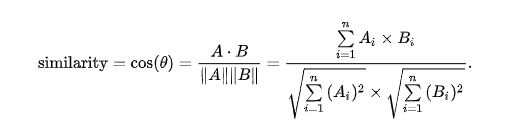
# 计算两篇文章的相似度,基于各自的TF
# (1,0,1),(0,1,0)
def cal_cos_similarity(tf1, tf2):
"""
计算两篇文章的相似度(0-1),根据TF
:param tf1:文章1的TF tuple
:param tf2:2 TF tuple
:return: 0-1,越大越相似
"""
if len(tf1) != len(tf2):
return 0
a = 0
for i in range(len(tf1)):
a += tf1[i] * tf2[i]
b1 = 0
b2 = 0
for i in range(len(tf1)):
b1 += tf1[i] * tf1[i]
b2 += tf2[i] * tf2[i]
b1 = b1 ** 0.5
b2 = b2 ** 0.5
similarity = a / (b1 * b2)
return similarity
求与第一篇文章相似度最大的文章
max_sim = 0
max_sim_i = 0
for i in range(len(articles)):
if i == 0:
continue
tfi = get_article_tf(articles[i], bag)
sim = cal_cos_similarity(tf1, tfi)
print(cal_cos_similarity(tf1, tfi))
if max_sim < sim:
max_sim = sim
max_sim_i = i
print('max sim=', max_sim, 'i=', max_sim_i)
求两篇相似度最大的文章
# all
max_s = 0
max_i = 0
max_j = 0
for i in range(len(articles)):
tfi = get_article_tf(articles[i], bag)
for j in range(len(articles)):
if i == j:
continue
tfj = get_article_tf(articles[j], bag)
sim = cal_cos_similarity(tfi, tfj)
if max_s < sim:
max_s = sim
max_i = i
max_j = j
print(max_s, max_i, max_j)