DeepSpeed + Kubernetes 如何轻松落地大规模分布式训练
作者:刘霖
背景现状
随着 ChatGPT 的广泛应用,各种大规模语言模型层出不穷,其中包括 EleutherAI 推出的 200 亿参数的 GPT-NeoX-20B 和 BigScience 发布的 1760 亿参数的 Bloom 模型。
由于模型越来越大,单张 GPU 已无法加载整个模型,分布式模型训练成为了一种必然的趋势。在 GPT-NeoX 和 Bloom 的背后,DeepSpeed 框架是实现分布式模型训练的关键。
DeepSpeed 是一个开源的深度学习训练优化库,提供了多种优化策略,如混合精度训练、数据并行、模型并行、流水线并行等,这些策略可用于加速大规模模型的训练。此外,DeepSpeed 还提供了高性能的分布式训练框架,支持多种主流的深度学习框架,并且可以在不同的硬件和云平台上进行训练。借助 DeepSpeed,算法工程师可以更加快速地训练大规模深度学习模型,从而提高模型的准确性和效率。
当前,越来越多企业在云上基于容器和 Kubernetes 进行大规模的分布式深度学习训练,充分利用弹性、扩展性、自动化、高可用等优势,大幅提高分布式训练的效率和可靠性,同时降低管理成本和复杂性。
然而,随着模型规模扩大以及企业对生产效率的不断追求,将 DeepSpeed 分布式训练任务在 Kubernetes 中搭建和运行仍然存在着很多挑战和难点。例如,GPU资源利用率低,分布式训练扩展性差,以及难以方便地获取实时日志和监控等。
方案介绍
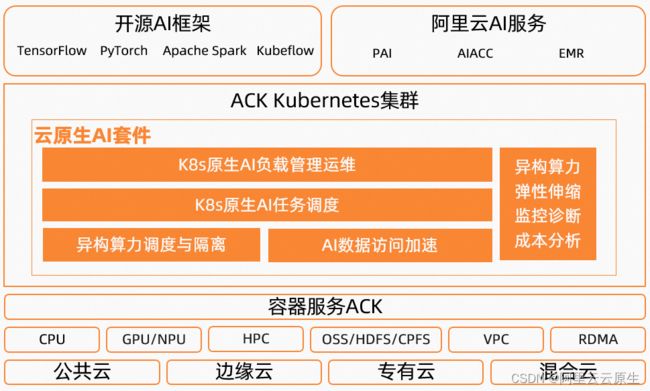
目前,阿里云容器服务 ACK 云原生 AI 套件已经支持 DeepSpeed 分布式训练,为您提供高效便捷的解决方案。
您只需准备好训练代码和数据,就可以利用命令行工具 Arena 快速在 ACK 集群中部署基于 DeepSpeed 的分布式训练任务。此外,可以通过 TensorBoard 可视化工具方便地查看训练作业的状态和结果,从而使 DeepSpeed 分布式训练变得更加容易和高效。
关于 ACK 云原生 AI 套件的更多信息,请通过往期文章进行了解:摆脱 AI 生产“小作坊”:如何基于 Kubernetes 构建云原生 AI 平台
核心优势
基于阿里云容器服务 ACK 云原生 AI 套件搭建和运行 DeepSpeed 分布式训练任务具备以下优势:
- 大规模异构资源管理
使用容器服务 ACK,您可以轻松管理大规模异构资源,快速搭建基于 CPU、GPU、FPGA 等不同类型计算资源的标准 Kubernetes 集群,实现对各类异构资源进行统一、灵活的管理、调度和运维。云原生 AI 套件还支持多种 GPU 调度策略(共享+隔离、优先级、拓扑感知等)和丰富的 GPU 监控告警等能力,帮您进一步优化资源利用率。
- 灵活弹性与成本优化
使用 ACK 弹性节点池和 HPA/VPA,您可以灵活按需自动伸缩 GPU 节点数和 Pod 数,并基于 GPU 指标实现 AHPA 弹性预测。云原生 AI 套件支持 ECS、ECI 等弹性资源混合的高级调度,包括 affinity/anti-affinity、pod topology spreading、deploymentset 感知等调度。此外,通过支持资源不足到时终止、checkpoint 自动保存、容错、Failover 等能力,解决基于抢占式实例进行分布式训练的可用性问题,减少训练成本的同时,近乎不影响训练作业成功率。ACK 还提供了成本监控和分析等能力,能够面向任务去管理和优化分布式训练的成本。
- 高效的任务管理调度
云原生 AI 套件提供命令行工具 Arena,对深度学习核心生产环节(包括数据管理、模型开发、模型训练、模型评估、推理服务部署等)任务进行简单抽象和高效管理。通过 Arena,您可以快速提交分布式训练任务,并提升训练任务从提交到运行的性能,以及进行任务的生命周期管理。此外,云原生AI套件还提供针对分布式场景优化的调度策略,例如按 GPU 卡的 Binpack 算法分配策略,提升 GPU 卡利用率,还支持自定义的任务优先级管理和租户弹性资源配额控制,在确保用户资源分配的基础上,通过资源共享的方式来提升集群的整体资源利用率。
快速使用
下面将介绍如何基于阿里云容器服务 ACK 云原生 AI 套件快速搭建和运行 DeepSpeed 分布式训练:
前提条件
- 已创建包含 GPU 的 Kubernetes 集群。具体操作,请参见创建包含 GPU 的 Kubernetes 集群 [ 1] 。
- 已安装云原生 AI 套件(ack-arena 版本不低于 0.9.6)。具体操作,请参见部署云原生 AI 套件 [ 2] 。
- 已安装 Arena 客户端(版本不低于 0.9.6)。具体操作,请参见安装 Arena [ 3] 。
- 已给集群配置了 Arena 使用的 PVC,具体操作,请参见配置 NAS 共享存储 [ 4] (或者配置 CPFS 共享存储 [ 5] )。
使用说明
本示例使用 DeepSpeed 训练一个掩码语言模型(Masked Language Model)。为方便运行,已将示例代码 [ 6] 和数据集下载至示例镜像中;若您无需使用示例镜像,也支持从 Git URL下载源代码,并将数据集存放在共享存储系统(基于 NAS 的 PV 和 PVC)中。本示例假设您已经获得了一个名称为 training-data 的 PVC 实例(一个共享存储),用来存放训练结果。
如需自定义训练镜像,请参考如下方式:
- 方式一:
参考该 Dockerfile [ 7] ,在基础镜像中安装 OpenSSH
- 方式二:
使用 ACK 提供的 DeepSpeed 基础镜像:
registry.cn-beijing.aliyuncs.com/acs/deepspeed:v072_base
示例介绍
本示例中创建了一个 Transformer Bert 模型,根据句子前后的上下文来填充句子。比如在下列句子中:
In the beautiful season of ____ the ____ shed their leaves.
根据提供的’In the beautiful season of’ 和 ‘shed their leaves’,可以预测到空白处应该填入 ‘Autumn’ 和 ‘trees’。
本示例通过整合 DeepSpeed 的能力来提高训练的速度和效率,在下列几个方面进行了优化:
- 混合精度训练:DeepSpeed 支持使用 fp16 数据类型进行混合精度训练。通过在 ds_config 中设置以下配置,即可启用混合精度训练。
"fp16": {
"enabled": True
}
- ZeRO 数据并行:Zero Redundancy Optimizer(零冗余优化器)可以支持每个 GPU 都只存储模型参数、梯度和优化器状态的一部分,从而降低 GPU 显存占用,支持更大的模型。当前支持 3 个阶段,阶段 1 对优化器状态进行分片。阶段2还会对梯度进行分片。阶段 3 进一步对模型权重进行分片。通过在 ds_config 中设置以下配置,即可启动阶段 1。
"zero_optimization": {
"stage": 1
}
- ZeRO-Offload:通过同时利用 GPU 和 CPU 的计算和存储资源,比如将优化器状态和梯度保存在内存上,从而使单 GPU 可以支持的模型更大。比如在一张 P40 GPU 上,无法训练一个 20 亿参数的模型,但是使用 ZeRO-Offload 可以做到。通过在 ds_config 中设置以下配置,即可启用 ZeRO-Offload。
"zero_optimization": {
"offload_optimizer": {
"device": "cpu"
}
}
本示例中 DeepSpeed 的完整配置文件 ds_config 参考如下。
ds_config = {
"train_micro_batch_size_per_gpu": batch_size,
"optimizer": {
"type": "Adam",
"params": {
"lr": 1e-4
}
},
"fp16": {
"enabled": True
},
"zero_optimization": {
"stage": 1,
"offload_optimizer": {
"device": "cpu"
}
}
}
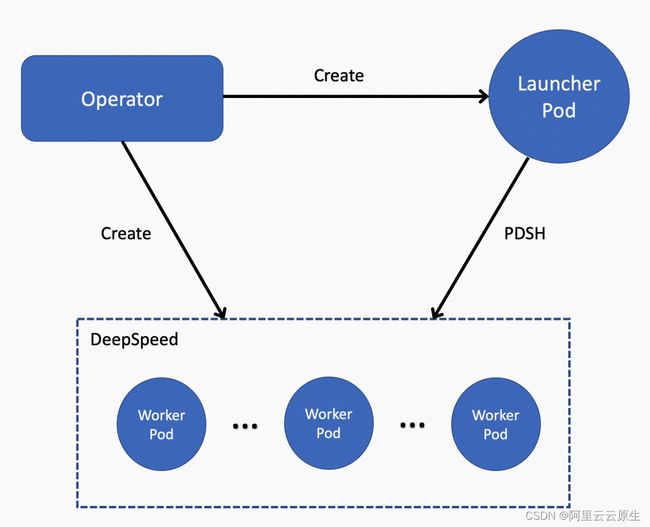
DeepSpeed 是基于 AllReduce 的分布式训练框架,在 hostfile 中保存了所有的 worker 信息,luancher 读取 hostfile 文件获取 worker 信息,通过 PDSH 的方式在每个 worker 上启动训练任务。
ACK 云原生 AI 套件中的 Operator 组件会自动生成上述配置。准备好模型训练代码和数据后,即可通过 Arena 提交 DeepSpeed 分布式训练任务。如下图所示,Operator 会创建一个 Launcher Pod 和多个 Worker Pod 并在 Worker Pod 上启动训练任务。
操作步骤
- 提交 DeepSpeed 作业
通过以下代码示例提交包含 1 个 Launcher 节点,3 个 Worker 节点的 DeepSpeed 训练任务。该任务将使用 3 台机器,每台机器上的一张 GPU 卡进行训练。
arena submit etjob \
--name=deepspeed-helloworld \
--gpus=1 \
--workers=3 \
--image=registry.cn-beijing.aliyuncs.com/acs/deepspeed:hello-deepspeed \
--data=training-data:/data \
--tensorboard \
--logdir=/data/deepspeed_data \
"deepspeed /workspace/DeepSpeedExamples/HelloDeepSpeed/train_bert_ds.py --checkpoint_dir /data/deepspeed_data"
预期输出如下:
trainingjob.kai.alibabacloud.com/deepspeed-helloworld created
INFO[0007] The Job deepspeed-helloworld has been submitted successfully
INFO[0007] You can run `arena get deepspeed-helloworld --type etjob` to check the job status
- 执行以下命令获取作业详情
arena get deepspeed-helloworld
预期输出如下:
Name: deepspeed-helloworld
Status: RUNNING
Namespace: default
Priority: N/A
Trainer: ETJOB
Duration: 6m
Instances:
NAME STATUS AGE IS_CHIEF GPU(Requested) NODE
---- ------ --- -------- -------------- ----
deepspeed-helloworld-launcher Running 6m true 0 cn-beijing.192.1xx.x.x
deepspeed-helloworld-worker-0 Running 6m false 1 cn-beijing.192.1xx.x.x
deepspeed-helloworld-worker-1 Running 6m false 1 cn-beijing.192.1xx.x.x
deepspeed-helloworld-worker-2 Running 6m false 1 cn-beijing.192.1xx.x.x
Your tensorboard will be available on:
http://192.1xx.x.xx:31870
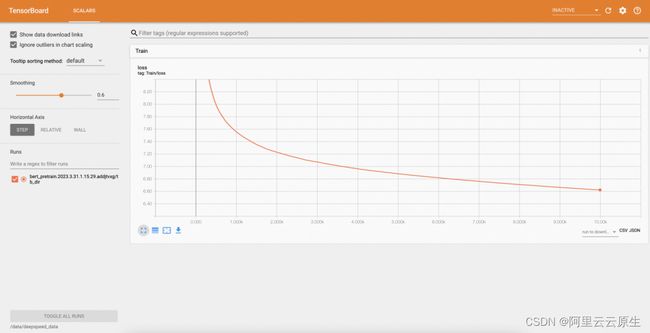
- 通过浏览器查看 TensorBoard
执行以下命令,将集群中的 TensorBoard 映射到本地 9090 端口。
kubectl port-forward svc/deepspeed-helloworld-tensorboard 9090:6006
在浏览器中访问 localhost:9090,即可查看 TensorBoard。
执行以下命令可获取作业日志信息:
arena logs deepspeed-helloworld
更多操作命令及参数解释可参考云原生 AI 套件文档 [ 8] 。
相关链接:
[1] 创建包含 GPU 的 Kubernetes 集群
https://help.aliyun.com/document_detail/171074.html?spm=a2c4g.171073.0.0.4c78f95a00Mb5P
[2] 部署云原生 AI 套件
https://help.aliyun.com/document_detail/201997.htm#section-2al-4w3-dpd
[3] 安装 Arena
https://help.aliyun.com/document_detail/212117.htm#task-1917487
[4] 配置 NAS 共享存储
https://help.aliyun.com/document_detail/212177.htm#task-1917776
[5] 配置 CPFS 共享存储
https://help.aliyun.com/document_detail/212178.htm#task-1917776
[6] 示例代码
https://github.com/microsoft/DeepSpeedExamples/tree/master/training/HelloDeepSpeed
[7] Dockerfile
https://github.com/kubeflow/arena/blob/master/samples/deepspeed/Dockerfile
[8] 云原生 AI 套件文档
https://help.aliyun.com/document_detail/2249322.html?spm=a2c4g.201994.0.0.23257371FAcYuc
如果您希望深入了解更多关于 ACK 云原生 AI 套件的信息,或者需要与我们就 LLM/AIGC 等相关需求进行交流,欢迎加入我们的钉钉群:33214567。