[图像复原](MPRNet)Multi-Stage Progressive Image Restoration
转载自:https://zhuanlan.zhihu.com/p/357876311
Multi-Stage Progressive Image Restoration 2021 cvpr
目前最强的去噪方法,没有之一。可以去看看它刷榜的战绩。
提出了一个多阶段结构,渐进式的学习复原函数。因此全面分解了回复过程,让每一步变得可操作。
模型先用编码解码结构学习情境特征,之后与一个保留局部信息的高分辨率分支融合。每一个阶段,介绍对每个像素的自适应设计,这个设计利用原像素位监督的注意力来调整局部的注意力。这样多阶段结构的一个关键因素是不同阶段的信息交换。为此,当信息不是按照顺序从前阶段交换到后阶段时,提出了个两面方法。但也设置了特征处理块间的侧连接,用来避免任何信息的缺失。这样产生紧密内部连接的多阶段结构叫MPRNet,有很好的性能提升
首先,现有的多阶段技术,要么使用编码解码器(编码阶段有效传播情境信息,但是在保留空间细节这里做的不好),要么使用single-scale pipeline[61](空间精度做的很好,但是语义信息不太行) 我们证明了在多阶段图像修复工作上,同时使用两种结构才能更有效(本文核心想法)
一.multi-stage progressive image restoration architecture,MPRNet,主要有一下几个部分:
1.前几个阶段使用了编码解码器来学习多尺度语境信息,最后阶段以图元原尺寸运行,保留细节
2.一个有监督的注意力模块(SAM),在每两个阶段连接处,实现阶段性学习。在ground truth引导下,这个模块利用先前阶段的预测来计算注意力图,然后用注意力图反过来作用到先前阶段的特征图,然后再传入下一个阶段。
3.一个交叉不同阶段特征的融合机制(CSFF,cross-stage feature fusion),用来帮助从前到后传播多尺度语境特征。此外,这个方法简化了不同阶段间的信息流,更好的优化了网络。
二.MPRNet结构
Multi-Stage Progressive Image Restoration_第1张图片](http://img.e-com-net.com/image/info8/bd585a37781440f2849896b18e085c89.jpg)
1.前两层都是基于编码解码器的子网络,可以学习较广泛的情境信息(感受野较大)。因图像复原是一个位置敏感任务(从头到尾都要求像素间的相关性),最后一阶段在原始分辨率上使用一个子网络(没有任何下采样),因此在最终输出是保留着不错的精细结构。
2.替换掉简单的多阶段结构。我们使用有监督的注意力模块,在每两个阶段间。在ground truth的监督下,模型重新缩放先前阶段特征图,然后再传入下一个阶段。
3.引入CSFF机制,
4.每一个阶段都有一条直接通往input的通道.与[68,85]类似,采取多补丁等级制度在输入图片和切分图片为互不相交的patch:阶段一4个,阶段二2个,然后第三层原始图片
5.在任何给定阶段S,取代直接预测X_s,模型预测残差R_s,初试退化图I,有:
![]()
Multi-Stage Progressive Image Restoration_第2张图片](http://img.e-com-net.com/image/info8/01ddc03ddbcb44d894812f1204db6112.jpg)
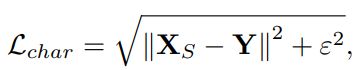
正则项取去10e-3

三.各个部分构成:
1.编码解码器子网络(encoder-decoder sub):
Multi-Stage Progressive Image Restoration_第3张图片](http://img.e-com-net.com/image/info8/55ee516ef3cf4a48aa622fa4eb5c39d5.jpg)
标准U-net基础上改造得到的。首先将所有的卷积模块换成CAB注意力模块,然后将上下采样换成双线性插值加卷积(去除转置卷积的块状效应,破坏结构)
2.原始分辨率子网络(ORSNet):
Multi-Stage Progressive Image Restoration_第4张图片](http://img.e-com-net.com/image/info8/b3e2ff34ac584dedaff528a6aae714d0.jpg)
为了保持输入的精细细节,引入original-resolution subnetwork(ORSNet)在最后阶段。ORSNet没有使用下采样,并且生成高分辨率的空间特征。它又多个ORBs块构成,每一个ORB都有多个通道注意力块.GAP表示全局平均池化,
3.交叉融合各极端特征(CSFF):
Multi-Stage Progressive Image Restoration_第5张图片](http://img.e-com-net.com/image/info8/79df4770da4a49108f484a22c1dfc941.jpg)
CSFF模块,设置在两个编码解码器之间,
Multi-Stage Progressive Image Restoration_第6张图片](http://img.e-com-net.com/image/info8/ca6986d770f842c6bc663ff34e228264.jpg)
编码解码器和ORSNet间
注意这里的融合过程,以编码解码器为例:每一个编码器或者解码器都有三个尺度的特征,对应尺度的特征与下一阶段的编码器的特征相加(代码中写的很详细)
CSFF的优点:首先它让网络不易收到信息缺失的影响。其次,一个阶段的多尺度特征帮助下一个阶段的特征补充。最后,它通过简化信息流网络优化进程更稳固。
4.有监督的注意力模块(SAM):
最近的图片复原多阶段网络[68,85],直接再每一阶段直接预测,然后在丢进下一个阶段。本模型在两个阶段间加了监督注意力模块(显著提升网络性能)如图
Multi-Stage Progressive Image Restoration_第7张图片](http://img.e-com-net.com/image/info8/42c3f919f62b423ab0d38d813faede66.jpg)
首先F_in是当前阶段输入SAM的输入,先进行就一个1*1卷积得到残差R_s,然后和退化图加和,得到复原的图片X_s(这个阶段预测的结果)。对应ground turth,我们有明确的监督信息。下一个阶段,每个像素注意力masks又预测出的X_s生成(做1*1卷积,再丢入sigmoid激活)。这个masks用来重新校准F_in(需要将F_in丢入1*1卷积).最后,注意力增强特征F_out得到,输入下一阶段。
优点有两点:首先,它在每一阶段提供了ground truth的监督。其次,在局部监督预测帮助下,生成注意力图来抑制当前阶段信息量较小的特征(通过自注意力机制计算每个特征的注意力权重?),并且只把有用的信息传递到下一阶段。
四.实验部分:
评价指标使用:PRNR 转为 RMSE .SSIM转为DSSIM
实验细节:编码解码器子网络每一个尺度使用2个CABs,为了下采样,使用步长为2的2*2最大值池化。在最后阶段,使用包含3ORBs的ORSNet,每一个ORB使用了8个CABs。网络在256*256补丁训练,batch16,迭代次数4e5.
收据增强方面,水平竖直反转随机。使用Adam优化器,学习率2e-4,使用cos退火策略渐减少到1e-6.
代码中CAB,ORB都使用了残差链接
复现的时候有很多细节需要注意,作者已经将代码开源,详细的网络架构建议查看代码。
本文给人的最大启发就是多阶段学习和SAM系统,值得学习。详细内容,欢迎讨论
一下附推荐学习的论文或方法,逐一学习,复现:
关于去雨水的模型:
Derain Net[21],
SEMI[75],
DIDMDN[86],
UMRL[80],
RESCAN[45],
PreNet[61],
MSPFN[36]。
去模糊论文:
Unnatural l0 sparse representation for natural image deblurring
Dynamic scene deblurring.
Non-uniform deblurring for shaken images.
From motion blur to motion flow: a deep learning solution for removing heterogeneous motion blur
Blind motion deblurring using conditional adversarial networks
Deep multi-scale convolutional neural network for dynamic scene deblurring
Dynamic scene deblurring using spatially variant recurrent neural networks
DeblurGAN-v2: Deblurring (orders-of-magnitude) faster and better
Scale-recurrent network for deep image deblurring
Human-aware motion deblurring.
Dynamic scene deblurring with parameter selective sharing and nested skip connections.
Multi-temporal recurrent neural networks for progressive non-uniform single image deblurring with incremental temporal training.
Deep stacked hierarchical multi-patch network for image deblurring
Spatially-attentive patch-hierarchical network for adaptive motion deblurring
去噪论文:
Deblurring low-light images with light streaks.
Deep multi-scale convolutional neural network for dynamic scene deblurring
DeblurgGAN: Blind motion deblurring using conditional adversarial networks.
Blind image deblurring using dark channel prior.
Unnatural l0 sparse representation for natural image deblurring.
DeblurGAN-v2: Deblurring (orders-of-magnitude) faster and better
Dynamic scene deblurring using spatially variant recurrent neural networks
Scale-recurrent network for deep image deblurring.
Deep stacked hierarchical multi-patch network for image deblurring.