(2023.07.05-2023.07.15)论文阅读简单记录和汇总
(2023.07.05-2023.07.15)论文阅读简单记录和汇总
2023/07/05:端午回家还没玩几天就被老板召唤回学校了,采购的事情真是太麻烦了,一堆的差错。昨天跟师弟把他的第一篇论文投出去了,祝好运!
2023/07/10:可惜,师弟的文章五天不到就被拒稿了,不过这也很正常。拒拒更健康,有拒才有得。
目录
- (arxiv 2023)COLOR LEARNING FOR IMAGE COMPRESSION
- (AAAI 2023)A Learnable Radial Basis Positional Embedding for Coordinate-MLPs
- (arxiv 2023)SPDER: Semiperiodic Damping-Enabled Object Representation
- (arxiv 2023)PROCESSING ENERGY MODELING FOR NEURAL NETWORK BASED IMAGE COMPRESSION
- (arxiv 2023)Text + Sketch: Image Compression at Ultra Low Rates
- (arxiv 2023)PREDICTIVE CODING FOR ANIMATION-BASED VIDEO COMPRESSION
1. (arxiv 2023)COLOR LEARNING FOR IMAGE COMPRESSION 图像压缩的颜色学习
1.1 摘要与贡献
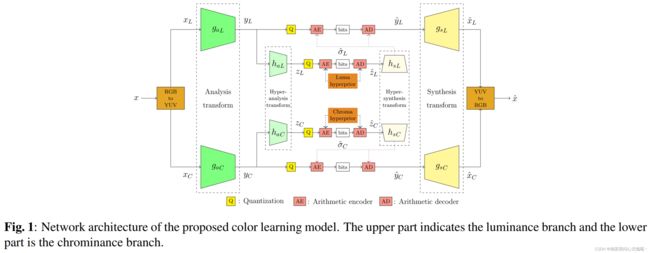
近年来,基于深度学习的图像压缩获得了 的大力发展。为了使该方法适用于图像压缩并随后扩展到 视频压缩,我们提出了一种新的深度学习模型 架构,其中图像压缩任务分为两个子任务,从亮度通道学习结构信息和从色度通道学习颜色。模型有两个独立的分支来处理亮度 和色度组件。在损失函数中采用色差度量CIEDE2000对 模型进行色彩保真度优化。我们将演示 方法的优点,并将其性能与其他编解码器进行比较。此外,还对潜在通道脉冲响应进行了可视化分析。
我们在这项工作中的贡献如下。我们提出了一个利用YUV颜色 间的深度神经网络模型 ,以利用亮度通道来获取结构信息,利用色度通道来获取颜色信息。为了优化模型的色彩保真度,我们在基于RDO的损失函数中使用显式色差度量- CIEDE2000 [13]。此外,为了研究分离结构和颜色信息的效果,通过扩展文献[14]中描述的方法,分析了所提模型对于 亮度和色度分量的通道脉冲响应。
1.2 结论
在这项工作中,我们开发了一个用于图像压缩任务的深度神经网络,其思想是分别捕获结构和颜色信息。我们使用RDO优化模型,并使用额外的度量- CIEDE2000来测量色差。与其他编解码器的比较证明了该模型的结构保真度和色彩保真度。通道脉冲响应实验验证了我们的 模型分别捕获结构和颜色信息。这可以用于执行跨组件预测和应用在残差编码,也可以扩展到学习视频压缩。所提出的方法可以很容易地采用最先进的方法来提高色彩保真度。
感觉结构很一般结果也很一般,就是采用了一个双支路的方式和额外的色度度量约束实现了一个端到端的图像压缩模型,消融实验验证了所提出方法确实能够捕获色度和结构信息,还算是比较完整吧。
2. (AAAI 2023)A Learnable Radial Basis Positional Embedding for Coordinate-MLPs 坐标 MLP 的可学习径向基位置嵌入
2.1 摘要与贡献
我们提出了一种新的方法,通过学习特定实例的位置嵌入来增强坐标mlp(也称为神经场)的性能。位置嵌入参数的端到端优化以及网络权值导致泛化性能较差。相反,我们开发了一个通用框架来学习基于经典图拉普拉斯正则化的位置嵌入,它可以隐式地平衡 记忆和泛化之间的权衡。然后,该框架 用于提出一种新的位置嵌入方案,其中每个坐标(即实例)学习超参数以提供最佳性能。我们表明,与已建立的随机傅立叶特征 (RFF)相比,提出的 嵌入实现了更好的性能和更高的稳定性。此外,我们证明了所提出的嵌入 方案产生稳定的梯度,从而能够将作为中间层无缝集成到深层架构中。
我们展示了我们的方法在许多信号重建任务中的有效性,与领先的硬编码方法中流行的随机傅立叶频率(RFF)相比。我们方法的一个独特之处在于 在我们的方法中不使用傅立叶位置嵌入。当试图执行局部平滑时,这样的嵌入实际上是有问题的。受(Zheng, Ramasinghe, and Lucey 2021)的启发,我们选择了具有空间局部性(如径向基函数)的嵌入。据我们所知,这是第一次使用:(i)非傅立叶, 和(ii)可学习的超参数来获得坐标mlp的最先进性能。我们还表明我们的嵌入器允许通过位置嵌入层进行更稳定的反向传播,从而可以轻松地将位置嵌入层集成为深度架构中的中间模块。同样值得注意的是,我们的工作揭示了一个相当有争议的话题——深度网络可以从非端到端学习中受益,其中每一层可以通过不同的优化目标独立优化。
2.2 结论
我们开发了一个框架,可用于优化位置嵌入。我们在各种任务中验证了我们的嵌入器在流行的RFF嵌入器上的有效性,并且 表明我们的嵌入器在不同的 训练条件下产生了更好的保真度和稳定性。最后,我们证明了与RFF相比, 超高斯嵌入器在反向传播期间可以产生平滑的梯度 ,这允许在深度网络中使用嵌入层作为中间模块。
看起来略有意思,可以推广到其他任务中,可惜在git上没有看到代码实现
3. (arxiv 2023)SPDER: Semiperiodic Damping-Enabled Object Representation 半周期阻尼对象表示
3.1 摘要与贡献
我们提出了一种神经网络架构,旨在自然地学习位置嵌入,并克服传统隐式神经表示网络面临的低频频谱偏差。我们提出的架构 SPDER是一个简单的MLP,它使用由正弦乘以次线性函数(称为阻尼函数)组成的激活函数。正弦使网络能够自动学习输入 坐标的位置嵌入,而阻尼通过防止向下投影到有限范围内的值来传递实际的坐标值。我们的结果表明,相比于图像表示的最先进技术, SPDERs将训练速度提高了10倍,并且损失收敛小了1,500 - 50,000倍。优越的表示能力使 SPDER在多个下游任务上也表现出色,如图像超分辨率 和视频帧插值。我们提供了关于为什么SPDER与其他INR方法相比显着改善拟合的直觉,同时不需要超参数调优或预处理。
我们将本文的贡献总结如下:
- 我们提出了一个简单而优雅的架构,可以很好地捕获不同类型 信号的频率,在图像和音频表示方面都达到了最先进的水平。具体来说,它比最先进的图像inr要好几个数量级。与其他非分层方法(如自身)相比,它将训练速度提高了10倍, 收敛到平均损失降低1.5万倍。
- 我们演示了我们的新激活函数如何帮助神经网络克服频谱偏差 ,并通过让每个神经元平衡编码信号的位置和值信息,在没有任何超参数调整或硬编码归纳偏差 的情况下学习位置嵌入。
- 我们强调其通过下游应用的通用性,如图像超分辨率,边缘检测,视频帧插值等。
3.2 结论和未来工作
在这项工作中,我们提出了一个简单直观的MLP架构,可以用来表示 图像,其损失比当前最先进的方法低几个数量级,而不需要 先验或增强,并且在许多情况下,实现全局最优。我们证明了它在表示音频、视频、图像梯度等方面的泛化性。我们还相信,我们的架构自动平衡输入的位置和值信息,可以为学习的位置嵌入提供新的见解。同样,研究SPDER如何克服频谱偏差可能有助于我们学习如何提高神经网络的性能。通过我们的插值实验,我们还表明SPDER保留了它没有看到的点的频谱,并且在某种意义上具有低频谱“方差”。
最合理的下一步包括将分层方法与SPDER相结合,其中网络非常准确地学习每个小块,然后有效地将它们聚合为近乎完美的表示。最终,随着神经硬件变得越来越普遍和先进, 使用神经网络来压缩和表示媒体将变得越来越有吸引力。 INR有效捕获频率结构的能力将导致大量应用程序 ,其中信息存储在网络的权重中,而不是字节码中。
4. (arxiv 2023)PROCESSING ENERGY MODELING FOR NEURAL NETWORK BASED IMAGE COMPRESSION 基于神经网络的图像压缩的处理能量建模
4.1 摘要与贡献
如今,基于神经网络的图像压缩算法的压缩性能优于最先进的压缩方法,如JPEG或基于HEVC的图像压缩。不幸的是,大多数基于神经网络的压缩方法都是在GPU上执行的,并且在执行过程中消耗大量的能量。因此,本文对基于最先进的神经网络压缩方法在GPU上的能量消耗 进行了深入分析,并表明可以使用图像大小来估计压缩网络的能量消耗,平均估计误差小于7%。最后,使用相关分析,我们发现每像素的操作次数是能量消耗的主要驱动力,并推断到第二个下采样步骤的网络层消耗的能量最多。
本文的贡献如下:
- 深入分析图像压缩网络的功耗;
- 高度精确的能量建模方法
- 设计节能网络的建议
4.2 结论
在本文中,我们研究了最先进的基于神经网络的图像压缩网络 在GPU上的能耗。我们表明,能量消耗线性取决于像素的数量,并且直到第二个下采样步骤的网络层对总体能量消耗贡献最大。
在未来的工作中,我们计划进一步分析网络, 分别分析编码和解码过程, 并额外考虑熵编码和解码。最后,我们将测试其他gpu和优化硬件与现有图像压缩方法进行公平比较。
5. (arxiv 2023)Text + Sketch: Image Compression at Ultra Low Rates 文字+草图:超低速率的图像压缩
5.1 摘要与贡献
文本到图像生成模型的最新进展提供了从短文本描述生成高质量图像的能力。这些基础模型在数十亿规模的 数据集上进行预训练后,可以有效地完成各种下游任务,而无需进一步训练。一个自然的问题是这样的模型如何适用于图像压缩。我们研究几种技术,其中预训练模型可以直接用于实现针对新型低速率体制的压缩方案。我们展示了如何将文本描述与 边信息结合使用,以生成 高保真重建,同时保留语义和原始空间结构。我们证明,在非常低的比特率下,我们的方法可以在感知和语义保真度方面显著改进学习压缩器, 尽管没有端到端训练。
我们展示了如何以草图的形式传输有限的侧信息来保存较低层次的结构。我们的全部贡献如下:
- 我们设计了一个神经压缩器,它使用文本到图像模型以零射击的方式实现压缩方案,以低于0.003比特每像素(bpp)的速率保持人类语义,这比以前研究的方法低一个数量级。
- 我们展示了如何使用压缩空间条件映射形式的侧信息来提供图像中的高级结构信息以及传输的文本标题,从而产生改善结构保存的重建。
- 我们表明,尽管没有端到端训练,但我们的方案在语义和感知质量方面优于最先进的生成压缩器。
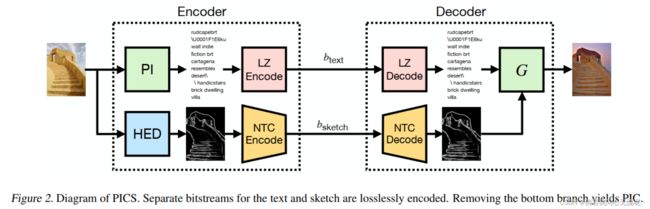
5.2 结论
在本文中,我们使用预训练的文本到图像模型构建了一个压缩器,该压缩器传输简短的文本提示 和压缩的图像草图。唯一需要的培训是在HED(Holistically-nested Edge Detection)草图上学习轻量级学习压缩机。实验结果表明,该算法在的语义质量和感知质量方面具有优异的性能。当前和未来的 工作包括评估人类对重建图像满意度 的人类研究。
最开始探索压缩问题的时候也思考过使用生成模型做压缩,但是后面想到输入输出空间之间存在的非对应映射问题,认为用生成模型是不切实际的,也不是压缩,更像是虚空造物。\
6.(arxiv 2023)PREDICTIVE CODING FOR ANIMATION-BASED VIDEO COMPRESSION 基于动画的视频压缩的预测编码
6.1 摘要与贡献
我们为会议类型的应用解决了有效压缩视频的问题。我们以最近的基于图像动画的方法为基础,通过使用一组紧凑的稀疏关键点来表示面部运动,可以在非常低的比特率下获得良好的重建质量。然而, 这些方法以逐帧的方式对视频进行编码,即每一帧都是从一个参考帧重构的,这 限制了带宽较大时的重构质量。相反,我们提出了一种预测编码方案,该方案使用图像动画作为预测器,并对相对于实际目标帧的残差进行编码。残差可以以预测的方式依次编码,从而有效地消除时间依赖性。我们的实验表明,在谈话视频数据集 上,与HEVC 视频标准相比,比特率降低了70%以上,与VVC相比,比特率降低了30%以上。
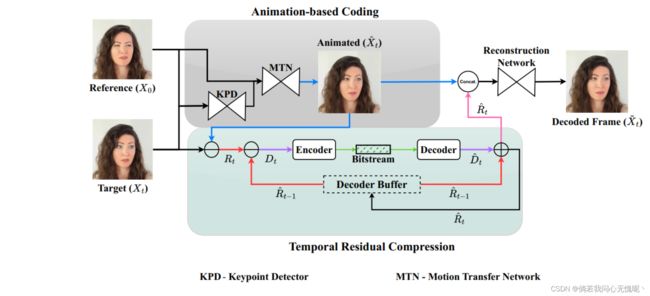
6.2 结论
基于动画的压缩提供了以非常低的比特率传输视频的可能性。然而,它通常仅限于在固定的质量水平上重建输出,当更高的带宽可用时不能有效地扩展,并且不能有效地压缩信号中的时间冗余。在本文中,我们提出了一种将图像动画(重新解释为帧预测器) 与经典预测编码原理集成的编码方案,其中我们利用 空间和时间依赖关系来实现编码增益。尽管我们的RDAC编解码器采用了非常简单的时间预测方法 ,但在谈话视频数据集上,我们的RDAC编解码器比以前的方法和标准编解码器的性能要好得多。