Kafka 深度剖析
1、应用场景
1.1 kafka场景
Kafka最初是由LinkedIn公司采用Scala语言开发,基于ZooKeeper,现在已经捐献给了Apache基金会。目前Kafka已经定位为一个分布式流式处理平台,它以 高吞吐、可持久化、可水平扩展、支持流处理等多种特性而被广泛应用。
Apache Kafka能够支撑海量数据的数据传递。在离线和实时的消息处理业务系统中,Kafka都有广泛的应用。
(1)日志收集:收集各种服务的log,通过kafka以统一接口服务的方式开放 给各种consumer,例如Hadoop、Hbase、Solr等;
(2)消息系统:解耦和生产者和消费者、缓存消息等;
(3)用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时 的监控分析,或者装载到Hadoop、数据仓库中做离线分析和挖掘;
(4)运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
(5)流式处理:比如spark streaming和storm;
1.2 kafka特性
kafka以高吞吐量著称,主要有以下特性:
(1)高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒;
(2)可扩展性:kafka集群支持热扩展;
(3)持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
(4)容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败);
(5)高并发:支持数千个客户端同时读写;
1.3 消息对比
- 如果普通的业务消息解耦,消息传输,rabbitMq是首选,它足够简单,管理方便,性能够用。
- 如果在上述,日志、消息收集、访问记录等高吞吐,实时性场景下,推荐kafka,它基于分布式,扩容便捷
- 如果很重的业务,要做到极高的可靠性,考虑rocketMq,但是它太重。需要有足够的了解
1.4 大厂应用
- 京东通过kafka搭建数据平台,用于用户购买、浏览等行为的分析。成功抗住6.18的流量洪峰
- 阿里借鉴kafka的理念,推出自己的rocketmq。在设计上参考了kafka的架构体系
2、基础组件
2.1 角色
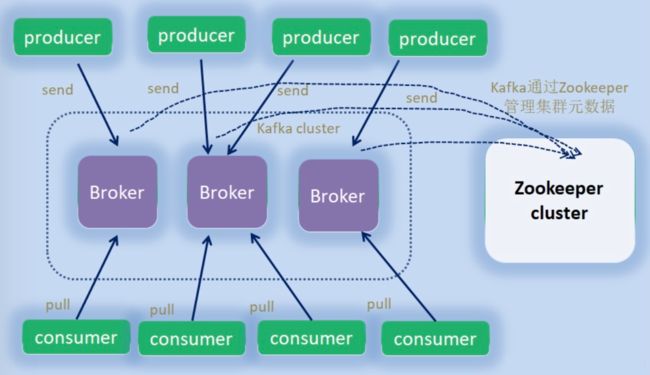
- broker:节点,就是你看到的机器
- provider:生产者,发消息的
- consumer:消费者,读消息的, 消息采用的是拉模型
- zookeeper:信息中心,记录kafka的各种信息的地方
- controller:其中的一个broker, 主要管理broker的元数据,作为leader身份来负责管理整个集群。如果挂掉,借助zk重新选主
消费模型分类
推模型(很少使用了):优点: 延迟低
缺点: 大量消息的时候不好控制, 消费端统一崩溃, 使用起来需要学要注意qos限流控制拉模型:
优点: 流量可控, 时刻批量消费
缺点: 有消息延迟, 不过可以有用长轮询模式解决(阻塞, 超时再请求)
2.2 逻辑组件
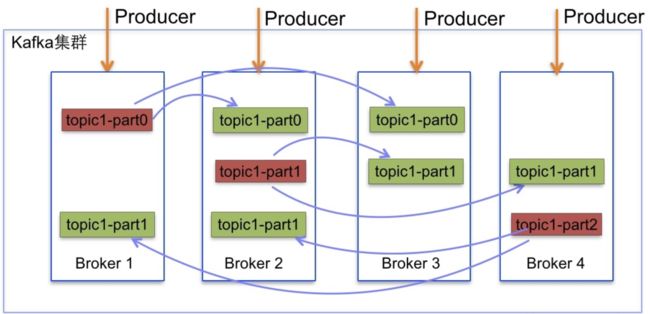
- topic:主题,一个消息的通道,收发总得知道消息往哪投, 只有leader才可以收发消息
- partition:分区,每个主题可以有多个分区分担数据的传递,多条路并行,吞吐量大
注: 一个分区只能被一个消费者消费, 一个消费者可以消费多个分区, 所以一般相同组消费者的数量小于等于分区的数量 - Replicas:副本,每个分区可以设置多个副本,副本之间数据一致。相当于备份,有备胎更可靠
- leader & follower:主从,上面的这些副本里有1个身份为leader,其他的为follower。leader处理partition的所有读写请求
2.3 副本集合
- AR(assigned replica):所有副本的统称,AR=ISR+OSR
- ISR(In-sync Replica):同步中的副本,可以参与leader选主。一旦落后太多(数量滞后和时间滞后两个维度)会被踢到OSR。
- OSR(Out-Sync Relipcas):踢出同步的副本,一直追赶leader,追上后会进入ISR
2.4 消息标记

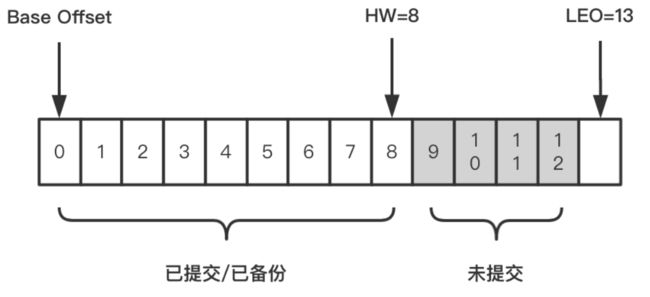

- OFFSET:偏移量,消息消费到哪一条了?每个消费者都有自己的偏移量
- HW:(high watermark):副本的高水印值,客户端最多能消费到的位置,HW值为8,代表offset为[0,8]的9条消息都可以被消费到,它们是对消费者可见的,而[9,12]这4条消息由于未提交,对消费者是不可见的。
- LEO:(log end offset):日志末端位移,代表日志文件中下一条待写入消息的offset,这个offset上实际是没有消息的。不管是leader副本还是follower副本,都有这个值。
三者关系
比如在副本数等于3的情况下,消息发送到Leader A之后会更新LEO的值,Follower B和Follower C也会实时拉取Leader A中的消息来更新自己,HW就表示A、B、C三者同时达到的日志位移,也就是A、B、C三者中LEO最小的那个值。由于B、C拉取A消息之间延时问题,所以HW一般会小于LEO,即LEO>=HW
3、架构探索
3.1 发展历程
http://kafka.apache.org/downloads
3.1.1 版本命名
Kafka在1.0.0版本前的命名规则是4位,比如0.8.2.1,0.8是大版本号,2是小版本号,1表示打过1个补丁
现在的版本号命名规则是3位,格式是“大版本号”+“小版本号”+“修订补丁数”,比如2.5.0,前面的2代表的是大版本号,中间的5代表的是小版本号,0表示没有打过补丁
看到的下载包,前面是scala编译器的版本,后面才是真正的kafka版本。
3.1.2 演进历史
0.7版本 只提供了最基础的消息队列功能。
0.8版本 引入了副本机制,至此Kafka成为了一个真正意义上完备的分布式高可靠消息队列解决方案。
0.9版本 增加权限和认证,使用Java重写了新的consumer API,Kafka Connect功能;不建议使用consumer API;
0.10版本 引入Kafka Streams功能,正式升级成分布式流处理平台;建议版本0.10.2.2;建议使用新版consumer API
0.11版本 producer API幂等,事务API,消息格式重构;建议版本0.11.0.3;谨慎对待消息格式变化
1.0和2.0版本 Kafka Streams改进;建议版本2.0;
3.2 集群搭建
1)原生启动
2)推荐docker-compose 一键启动
参考安装地址: docker-compose安装
3.3 组件探秘
命令行工具是管理kafka集群最直接的工具。官方自带,不需要额外安装。
3.2.1 主题创建

#进入容器
docker exec -it kafka-1 sh
#进入bin目录
cd /opt/kafka/bin
#创建
kafka-topics.sh --zookeeper zookeeper:2181 --create --topic test --partitions 2 --replication-factor 1
3.2.2 查看主题
kafka-topics.sh --zookeeper zookeeper:2181 --list
3.2.3 主题详情
kafka-topics.sh --zookeeper zookeeper:2181 --describe --topic test
#分析输出:
Topic:test PartitionCount:2 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 2 Replicas: 2 Isr: 2
Topic: test Partition: 1 Leader: 1 Replicas: 1 Isr: 1
3.2.4 消息收发
#使用docker连接任意集群中的一个容器
docker exec -it kafka-1 sh
#进入kafka的容器内目录
cd /opt/kafka/bin
#客户端监听
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test
#另起一个终端,验证发送
./kafka-console-producer.sh --broker-list localhost:9092 --topic test
3.2.5 分组消费
#启动两个consumer时,如果不指定group信息,消息被广播
#指定相同的group,让多个消费者分工消费
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --group aaa
#结果:在发送方,连续发送 1-4 ,4条消息,同一group下的两台consumer交替消费,并发执行
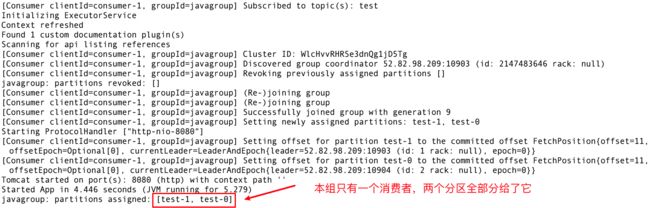
注意!!!
这是在消费者和分区数相等(都是2)的情况下。 如果同一group下的 ( 消费者数量 > 分区数量 ) 那么就会有消费者闲置。
验证方式:
可以再多启动几个消费者试一试,会发现,超出2个的时候,有的始终不会消费到消息。 停掉可以消费到的,那么闲置的会被激活,进入工作状态
3.2.6 指定分区
#指定分区通过参数 --partition,注意!需要去掉上面的group
#指定分区的意义在于,保障消息传输的顺序性(画图:kafka顺序性原理)
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --partition 0
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --partition 1
#结果:发送1-4条消息,交替出现。说明消息被均分到各个分区中投递
#默认的发送是没有指定key的
#要指定分区发送,就需要定义key。那么相同的key被路由到同一个分区
./kafka-console-producer.sh --broker-list kafka-1:9092 --topic test --property parse.key=true
#携带key再发送,注意key和value之间用tab分割
>1 1111
>1 2222
>2 3333
>2 4444
#查看consumer的接收情况
#结果:相同的key被同一个consumer消费掉
3.2.7 偏移量
#偏移量决定了消息从哪开始消费,支持:开头,还是末尾
#earliest: 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
#latest: 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
#none: topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
#注意点!!!有提交偏移量的话,仍然以提交的为主,即便使用earliest,比提交点更早的也不会被提取
#--offset [earliest|latest(默认)] , 或者 --from-beginning
#新起一个终端,指定offset位置
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --partition 0 --offset earliest
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --partition 0 --from-beginning
#结果:之前发送的消息,从头又消费了一遍!
3.4 zk探秘
前面说过,zk存储了kafka集群的相关信息
kafka的信息记录在zk中,进入zk容器,查看相关节点和信息
docker exec -it kafka-zookeeper-1 sh
>./bin/zkCli.sh
>ls /
#结果:得到以下配置信息

3.4.1 broker信息
[zk: localhost:2181(CONNECTED) 0] ls /brokers
[ids, topics, seqid]
[zk: localhost:2181(CONNECTED) 1] ls /brokers/ids
[1, 2]
#机器broker信息
[zk: localhost:2181(CONNECTED) 4] get /brokers/ids/1
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://192.168.10.30:10903"],"jmx_port":-1,"host":"192.168.10.30","timestamp":"1609825245500","port":10903,"version":4}
cZxid = 0x27
ctime = Tue Jan 05 05:40:45 GMT 2021
mZxid = 0x27
mtime = Tue Jan 05 05:40:45 GMT 2021
pZxid = 0x27
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x105a2db626b0000
dataLength = 196
numChildren = 0
3.4.2 主题与分区
#分区节点路径
[zk: localhost:2181(CONNECTED) 5] ls /brokers/topics
[test, __consumer_offsets]
[zk: localhost:2181(CONNECTED) 6] ls /brokers/topics/test
[partitions]
[zk: localhost:2181(CONNECTED) 7] ls /brokers/topics/test/partitions
[0, 1]
[zk: localhost:2181(CONNECTED) 8] ls /brokers/topics/test/partitions/0
[state]
#分区信息,leader所在的机器id,isr列表等
[zk: localhost:2181(CONNECTED) 18] get /brokers/topics/test/partitions/0/state
{"controller_epoch":1,"leader":1,"version":1,"leader_epoch":0,"isr":[1]}
cZxid = 0xb0
ctime = Tue Jan 05 05:56:06 GMT 2021
mZxid = 0xb0
mtime = Tue Jan 05 05:56:06 GMT 2021
pZxid = 0xb0
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 72
numChildren = 0
3.4.3 消费者与偏移量
[zk: localhost:2181(CONNECTED) 15] ls /consumers
[]
kafka 消费者记录 group 的消费 偏移量 有两种方式 :
1)kafka 自维护 (新)
2)zookpeer 维护 (旧) ,已经逐渐被废弃
查看方式:
上面的消费用的是控制台工具,这个工具使用–bootstrap-server,不经过zk,也就不会记录到/consumers下。
其消费者的offset会更新到一个kafka自带的topic【__consumer_offsets】下面
#先起一个消费端,指定group
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --group aaa
#使用控制台工具查看消费者及偏移量情况
./kafka-consumer-groups.sh --bootstrap-server kafka-1:9092 --list
KMOffsetCache-44acff134cad
aaa
#查看偏移量详情
./kafka-consumer-groups.sh --bootstrap-server kafka-1:9092 --describe --group aaa
当前与LEO保持一致,说明消息都完整的被消费过

停掉consumer后,往provider中再发几条记录,offset开始滞后:

重新启动consumer,消费到最新的消息,同时再返回看偏移量,消息得到同步:

3.4.4 controller
#当前集群中的主控节点是谁
[zk: localhost:2181(CONNECTED) 17] get /controller
{"version":1,"brokerid":1,"timestamp":"1609825245694"}
cZxid = 0x2a
ctime = Tue Jan 05 05:40:45 GMT 2021
mZxid = 0x2a
mtime = Tue Jan 05 05:40:45 GMT 2021
pZxid = 0x2a
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x105a2db626b0000
dataLength = 54
numChildren = 0
3.5 km
3.5.1 启动
kafka-manager是目前最受欢迎的kafka集群管理工具,最早由雅虎开源。提供可视化kafka集群操作
官网:https://github.com/yahoo/kafka-manager/releases
注意它的版本,docker社区的镜像版本滞后于kafka,需要自己来打镜像。
#Dockerfile
FROM daocloud.io/library/java:openjdk-8u40-jdk
ADD kafka-manager-2.0.0.2/ /opt/km2002/
CMD ["/opt/km2002/bin/kafka-manager","-Dconfig.file=/opt/km2002/conf/application.conf"]
#打包,注意将kafka-manager-2.0.0.2放到同一目录
docker build -t km:2002 .
# 还可以直接拉取
docker pull liggdocker/km:2002
# 修改镜像标签为km:2002
docker tag imageId km:2002
#启动:在上面的yml里,services节点下加一段
km:
image: liggdocker/km:2002
ports:
- 10906:9000
depends_on:
- zookeeper
#参考:km.yml
#执行: docker-compose -f km.yml up -d
完整的km.yml内容
version: '3'
services:
zookeeper:
image: zookeeper:3.4.13
kafka-1:
container_name: kafka-1
image: wurstmeister/kafka:2.12-2.2.2
ports:
- 10903:9092
environment:
KAFKA_BROKER_ID: 1
HOST_IP: 192.168.10.30
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
#docker部署必须设置外部可访问ip和端口,否则注册进zk的地址将不可达造成外部无法连接
KAFKA_ADVERTISED_HOST_NAME: 192.168.10.30
KAFKA_ADVERTISED_PORT: 10903
volumes:
- /etc/localtime:/etc/localtime
depends_on:
- zookeeper
kafka-2:
container_name: kafka-2
image: wurstmeister/kafka:2.12-2.2.2
ports:
- 10904:9092
environment:
KAFKA_BROKER_ID: 2
HOST_IP: 192.168.10.30
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_HOST_NAME: 192.168.10.30
KAFKA_ADVERTISED_PORT: 10904
volumes:
- /etc/localtime:/etc/localtime
depends_on:
- zookeeper
km:
image: liggdocker/km:2002
ports:
- 10906:9000
depends_on:
- zookeeper
3.5.2 使用
使用km可以方便的查看以下信息:
- cluster:创建集群,填写zk地址,选中jmx,consumer信息等选项
- brokers:列表,机器信息
- topic:主题信息,主题内的分区信息。创建新的主题,增加分区
- cosumers: 消费者信息,偏移量等
4、深入应用
4.1 springboot-kafka
1)配置文件
kafka:
bootstrap-servers: 192.168.10.30:10903,192.168.10.30:10904
producer: # producer 生产者
retries: 0 # 重试次数
acks: 1 # 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
batch-size: 16384 # 一次最多发送数据量
buffer-memory: 33554432 # 生产端缓冲区大小
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer: # consumer消费者
group-id: javagroup # 默认的消费组ID
enable-auto-commit: true # 是否自动提交offset
auto-commit-interval: 100 # 提交offset延时(接收到消息后多久提交offset)
auto-offset-reset: latest #earliest,latest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
2)启动信息
4.2 消息发送

4.2.1 发送类型
KafkaTemplate调用send时默认采用异步发送,如果需要同步获取发送结果,调用get方法
如果发送异步并增加消息可靠性, 采用send方法内传入回调callback的形式
最不安全的是发送并忘记, send后不关心是否成功, 慎用, 容易丢失消息
参考: 链接
消费者使用
//默认消费组消费
@Component
public class KafkaConsumer {
private final Logger logger = LoggerFactory.getLogger(KafkaConsumer.class);
//不指定group,默认取yml里配置的
@KafkaListener(topics = {"test"})
public void onMessage1(ConsumerRecord<?, ?> consumerRecord) {
Optional<?> optional = Optional.ofNullable(consumerRecord.value());
if (optional.isPresent()) {
Object msg = optional.get();
logger.info("message:{}", msg);
}
}
}
1)同步发送
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send("test", JSON.toJSONString(message));
//注意,可以设置等待时间,超出后,不再等候结果
SendResult<String, Object> result = future.get(3,TimeUnit.SECONDS);
logger.info("send result:{}",result.getProducerRecord().value());
2)阻断
在服务器上,将kafka暂停服务
docker-compose -f km.yml pause kafka-1 kafka-2
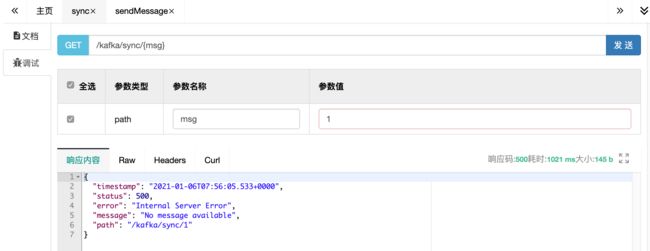
在swagger发送消息
调同步发送:请求被阻断,一直等待,超时后返回错误
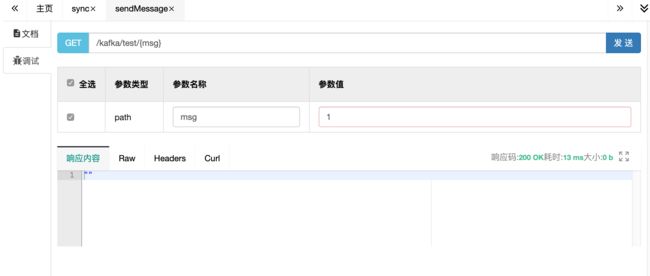
而调异步发送的(默认发送接口),请求立刻返回。
3)注册监听
异步发送的消息确认发送情况
代码参考
@Configuration
public class KafkaListener {
private final static Logger logger = LoggerFactory.getLogger(KafkaListener.class);
@Autowired
KafkaTemplate kafkaTemplate;
//配置监听
@PostConstruct
private void listener(){
kafkaTemplate.setProducerListener(new ProducerListener<String, Object>() {
@Override
public void onSuccess(ProducerRecord<String, Object> producerRecord, RecordMetadata recordMetadata) {
logger.info("ok,message={}",producerRecord.value());
}
@Override
public void onError(ProducerRecord<String, Object> producerRecord, Exception exception) {
logger.error("error!message={}",producerRecord.value());
}
});
}
}
可以给kafkaTemplate设置Listener来监听消息发送情况,实现内部的对应方法
kafkaTemplate.setProducerListener(new ProducerListener<String, Object>() {});
查看控制台,等待一段时间后,异步发送失败的消息会被回调给注册过的listener
com.demo.config.KafkaListener:error!message={"message":"1","sendTime":1609920296374}
启动kafka
docker-compose unpause kafka-1 kafka-2
再次发送消息时,同步异步均可以正常收发,并且监听进入success回调
com.demo.config.KafkaListener$1:ok,message={"message":"1","sendTime":1610089315395}
com.demo.controller.PartitionConsumer:patition=1,message:[{"message":"1","sendTime":1610089315395}]
可以看到,在内部类 KafkaListener$Listener 中,即注册的Listener的消息。
4.2.2 序列化
消费者使用:KafkaConsumer.java
1)序列化详解
- 前面用到的是Kafka自带的字符串序列化器(org.apache.kafka.common.serialization.StringSerializer)
- 除此之外还有:ByteArray、ByteBuffer、Bytes、Double、Integer、Long 等
- 这些序列化器都实现了接口 (org.apache.kafka.common.serialization.Serializer)
- 基本上,可以满足绝大多数场景
- 在json传输是可以使用apache的avro的序列化方式, 体积更小
2)自定义序列化
自己实现,实现对应的接口即可,有以下方法:
public interface Serializer<T> extends Closeable {
default void configure(Map<String, ?> configs, boolean isKey) {
}
//理论上,只实现这个即可正常运行
byte[] serialize(String var1, T var2);
//默认调上面的方法
default byte[] serialize(String topic, Headers headers, T data) {
return this.serialize(topic, data);
}
default void close() {
}
}
案例
public class MySerializer implements Serializer {
@Override
public byte[] serialize(String s, Object o) {
String json = JSON.toJSONString(o);
return json.getBytes();
}
}
在yaml中配置自己的编码器
value-serializer: com.demo.config.MySerializer
重新发送,发现:消息发送端编码回调一切正常。但是消费端消息内容不对!
com.demo.controller.KafkaListener$1:ok,message={"message":"1","sendTime":1609923570477}
com.demo.controller.KafkaConsumer:message:"{\\"message\\":\\"1\\",\\"sendTime\\":1609923570477}"
3)解码
发送端有编码并且自己定义了编码,那么接收端自然要配备对应的解码策略
代码参考
public class MyDeserializer implements Deserializer {
private final static Logger logger = LoggerFactory.getLogger(MyDeserializer.class);
@Override
public Object deserialize(String s, byte[] bytes) {
try {
String json = new String(bytes,"utf-8");
return JSON.parse(json);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return null;
}
}
在yaml中配置自己的解码器
value-deserializer: com.demo.config.MyDeserializer
再次收发,消息正常
com.demo.controller.AsyncProducer$1:ok,message={"message":"1","sendTime":1609924855896}
com.demo.controller.KafkaConsumer:message:{"message":"1","sendTime":1609924855896}
4.2.3 分区策略
分区策略决定了消息根据key投放到哪个分区,也是顺序消费保障的基石。
- 给定了分区号,直接将数据发送到指定的分区里面去
- 没有给定分区号,给定数据的key值,通过key取上hashCode进行分区
- 既没有给定分区号,也没有给定key值,直接轮循进行分区
- 自定义分区,你想怎么做就怎么做
1)验证默认分区规则
发送者代码参考
//测试分区发送
@RestController
public class PartitionProducer {
@Resource
private KafkaTemplate<String, Object> kafkaTemplate;
// 指定key发送,不指定分区
// 根据key做hash,相同的key到同一个分区
@GetMapping("/kafka/keysend/{key}")
public void setKey(@PathVariable("key") String key) {
kafkaTemplate.send("test", key, "key=" + key + ",msg=不指定分区");
}
// 指定分区发送
// 不管你key是什么,到同一个分区
@GetMapping("/kafka/partitionSend/{key}")
public void setPartition(@PathVariable("key") String key) {
kafkaTemplate.send("test", 0, key, "key=" + key + ",msg=指定0号分区");
}
}
消费者代码使用
//指定消费组消费
@Component
public class PartitionConsumer {
private final Logger logger = LoggerFactory.getLogger(PartitionConsumer.class);
//分区消费
@KafkaListener(topics = {"test"}, topicPattern = "0")
public void onMessage(ConsumerRecord<?, ?> consumerRecord) {
Optional<?> optional = Optional.ofNullable(consumerRecord.value());
if (optional.isPresent()) {
Object msg = optional.get();
logger.info("partition=0,message:[{}]", msg);
}
}
@KafkaListener(topics = {"test"}, topicPattern = "1")
public void onMessage1(ConsumerRecord<?, ?> consumerRecord) {
Optional<?> optional = Optional.ofNullable(consumerRecord.value());
if (optional.isPresent()) {
Object msg = optional.get();
logger.info("partition=1,message:[{}]", msg);
}
}
}
2)自定义分区
自己定义规则,根据要求,把消息投放到对应的分区去
参考代码
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 定义自己的分区策略
// 如果key以0开头,发到0号分区
// 其他都扔到1号分区
String keyStr = key+"";
if (keyStr.startsWith("0")){
return 0;
}else {
return 1;
}
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
@Configuration
public class MyPartitionTemplate {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
KafkaTemplate kafkaTemplate;
@PostConstruct
public void setKafkaTemplate() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
//注意分区器在这里!!!
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyPartitioner.class);
this.kafkaTemplate = new KafkaTemplate<String, String>(new DefaultKafkaProducerFactory<>(props));
}
// @Bean
public KafkaTemplate getKafkaTemplate(){
return kafkaTemplate;
}
}
发送使用
//测试自定义分区发送
@RestController
public class MyPartitionProducer {
@Autowired
MyPartitionTemplate template;
// 使用0开头和其他任意字母开头的key发送消息
// 看控制台的输出,在哪个分区里?
@GetMapping("/kafka/myPartitionSend/{key}")
public void setPartition(@PathVariable("key") String key) {
template.getKafkaTemplate().send("test", key,"key="+key+",msg=自定义分区策略");
}
}
备注:
自己定义config参数,比较麻烦,需要打破默认的KafkaTemplate设置
可以自定义KafkaConfiguration的getTemplate加上@Bean注解来覆盖系统默认bean
4.2.4 消息拦截器
参考链接: 跳转
4.3 消息消费
4.3.1 消息组别
发送者使用
kafkaTemplate.send(topicName, groupId, message);
1)代码参考
//测试组消费
@Component
public class GroupConsumer {
private final Logger logger = LoggerFactory.getLogger(GroupConsumer.class);
//组1,消费者1
@KafkaListener(topics = {"test"},groupId = "group1")
public void onMessage1(ConsumerRecord<?, ?> consumerRecord) {
Optional<?> optional = Optional.ofNullable(consumerRecord.value());
if (optional.isPresent()) {
Object msg = optional.get();
logger.info("group:group1-consumer1 , message:{}", msg);
}
}
//组1,消费者2
@KafkaListener(topics = {"test"},groupId = "group1")
public void onMessage2(ConsumerRecord<?, ?> consumerRecord) {
Optional<?> optional = Optional.ofNullable(consumerRecord.value());
if (optional.isPresent()) {
Object msg = optional.get();
logger.info("group:group1-consumer2 , message:{}", msg);
}
}
//组2,只有一个消费者
@KafkaListener(topics = {"test"},groupId = "group2")
public void onMessage3(ConsumerRecord<?, ?> consumerRecord) {
Optional<?> optional = Optional.ofNullable(consumerRecord.value());
if (optional.isPresent()) {
Object msg = optional.get();
logger.info("group:group2-consumer1 , message:{}", msg);
}
}
}
- 一个消费者组可以有多个消费者
- 同一group下的两个消费者,在group1均分消息
- group2下只有一个消费者,得到全部消息
3)消费端闲置
注意分区数与消费者数的搭配,如果 ( 消费者数 > 分区数量 ),将会出现消费者闲置,浪费资源!
4)消费者分区分配策略
消费者分区分配策略参考: 链接
4.3.2 位移提交
1)自动提交
设置了以下两个选项,则kafka会按延时设置自动提交
enable-auto-commit: true # 是否自动提交offset
auto-commit-interval: 100 # 提交offset延时(接收到消息后多久提交offset)
2)手动提交
有些时候,需要手动控制偏移量的提交时机,比如确保消息严格消费后再提交,以防止丢失或重复。
定义配置,覆盖上面的参数
代码参考:
@Configuration
public class MyOffsetConfig {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public KafkaListenerContainerFactory<?> manualKafkaListenerContainerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
configProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// 注意这里!!!设置手动提交
configProps.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
ConcurrentKafkaListenerContainerFactory<String, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(configProps));
// ack模式:
// AckMode针对ENABLE_AUTO_COMMIT_CONFIG=false时生效,有以下几种:
//
// RECORD
// 每处理一条commit一次
//
// BATCH(默认)
// 每次poll的时候批量提交一次,频率取决于每次poll的调用频率
//
// TIME
// 每次间隔ackTime的时间去commit(跟auto commit interval有什么区别呢?)
//
// COUNT
// 累积达到ackCount次的ack去commit
//
// COUNT_TIME
// ackTime或ackCount哪个条件先满足,就commit
//
// MANUAL
// listener负责ack,但是背后也是批量上去
//
// MANUAL_IMMEDIATE
// listner负责ack,每调用一次,就立即commit
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
return factory;
}
}
通过在消费端的Consumer来提交偏移量,有如下几种方式:
代码参考MyOffsetConsumer.java:
@Component
public class MyOffsetConsumer {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@KafkaListener(topics = "test", groupId = "myoffset-group-1", containerFactory = "manualKafkaListenerContainerFactory")
public void manualCommit(@Payload String message,
@Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
Consumer consumer,
Acknowledgment ack) {
logger.info("手动提交偏移量 , partition={}, msg={}", partition, message);
// 同步提交
consumer.commitSync();
//异步提交
//consumer.commitAsync();
// ack提交也可以,会按设置的ack策略走(参考里的ack模式)
// ack.acknowledge();
}
@KafkaListener(topics = "test", groupId = "myoffset-group-2", containerFactory = "manualKafkaListenerContainerFactory")
public void noCommit(@Payload String message,
@Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
Consumer consumer,
Acknowledgment ack) {
logger.info("忘记提交偏移量, partition={}, msg={}", partition, message);
// 不做commit!
}
/**
* 现实状况:
* commitSync和commitAsync组合使用
*
* 手工提交异步 consumer.commitAsync();
* 手工同步提交 consumer.commitSync()
*
* commitSync()方法提交最后一个偏移量。在成功提交或碰到无怯恢复的错误之前,
* commitSync()会一直重试,但是commitAsync()不会。
*
* 一般情况下,针对偶尔出现的提交失败,不进行重试不会有太大问题
* 因为如果提交失败是因为临时问题导致的,那么后续的提交总会有成功的。
* 但如果这是发生在关闭消费者或再均衡前的最后一次提交,就要确保能够提交成功。否则就会造成重复消费
* 因此,在消费者关闭前一般会组合使用commitAsync()和commitSync()。
*/
@KafkaListener(topics = "test", groupId = "myoffset-group-3", containerFactory = "manualKafkaListenerContainerFactory")
public void manualOffset(@Payload String message,
@Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
Consumer consumer,
Acknowledgment ack) {
try {
logger.info("同步异步搭配 , partition={}, msg={}", partition, message);
//先异步提交
consumer.commitAsync();
//继续做别的事
} catch (Exception e) {
System.out.println("commit failed");
} finally {
try {
consumer.commitSync();
} finally {
// consumer.close();
}
}
}
/**
* 甚至可以手动提交,指定任意位置的偏移量
* 不推荐日常使用!!!
*/
@KafkaListener(topics = "test", groupId = "myoffset-group-4",containerFactory = "manualKafkaListenerContainerFactory")
public void offset(ConsumerRecord record, Consumer consumer) {
logger.info("手动指定任意偏移量, partition={}, msg={}", record.partition(), record);
Map<TopicPartition, OffsetAndMetadata> currentOffset = new HashMap<>();
currentOffset.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1));
consumer.commitSync(currentOffset);
}
}
同步提交、异步提交:manualCommit() ,同步异步的差别,下面会详细讲到。
指定偏移量提交:offset()
3)重复消费问题
如果手动提交模式被打开,一定不要忘记提交偏移量。否则会造成重复消费!
代码参考和对比:manualCommit() , noCommit()
验证过程:
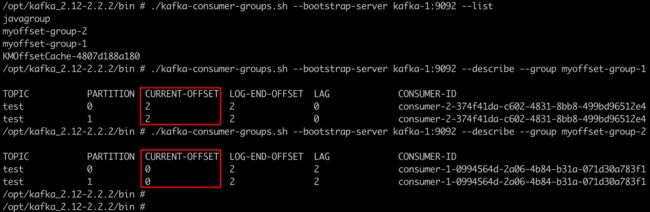
用km将test主题删除,新建一个test空主题。方便观察消息偏移 注释掉其他Consumer的Component注解,只保留当前MyOffsetConsumer.java 启动项目,使用swagger的KafkaProducer发送连续几条消息 留心控制台,都能消费,没问题:
无论重启多少次,不提交偏移量的消费组,会重复消费一遍
再通过命令行查询偏移量:
4)经验与总结
commitSync()方法,即同步提交,会提交最后一个偏移量。在成功提交或碰到无怯恢复的错误之前,commitSync()会一直重试,但是commitAsync()不会。
这就造成一个陷阱:
如果异步提交,针对偶尔出现的提交失败,不进行重试不会有太大问题,因为如果提交失败是因为临时问题导致的,那么后续的提交总会有成功的。只要成功一次,偏移量就会提交上去。
但是!如果这是发生在关闭消费者时的最后一次提交,就要确保能够提交成功,如果还没提交完就停掉了进程。就会造成重复消费!
因此,在消费者关闭前一般会组合使用commitAsync()和commitSync()。
详细代码参考:MyOffsetConsumer.manualOffset()
4.4 缓冲池
producerBatch需要空间存储消息的时候,就去缓存池申请一块内存,而不用频繁地创建和销毁内存,也就避免了频繁地GC
整个BufferPool的大小默认为32M,内部内存区域分为两块:固定大小内存块集合free、非池化缓存nonPooledAvailableMemory。固定大小内存块默认大小为16k。当ProducerBatch向BufferPool申请一个大小为size的内存块时,BufferPool会根据size的大小判断由哪个内存区域分配内存块。同时,free和nonPooledAvailableMemory这两块区域的内存可以交换
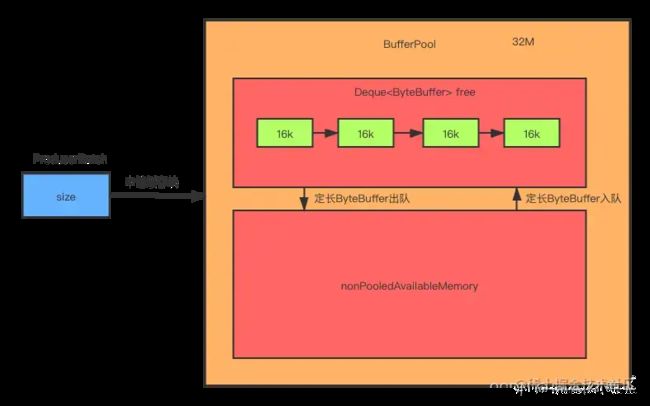
4.4.1 原理分析
类BufferPool
重要字段如下:
public class BufferPool {
static final String WAIT_TIME_SENSOR_NAME = "bufferpool-wait-time";
private final long totalMemory;//默认32M
private final int poolableSize;//池化大小16k
private final ReentrantLock lock;//分配和回收时用的锁。
private final Deque<ByteBuffer> free;//池化的内存
private final Deque<Condition> waiters;//阻塞线程对应的Condition集合
private long nonPooledAvailableMemory;//非池化可使用的内存
}
totalMemory:整个BufferPool内存大小,默认是32M。
poolableSize:池化缓存区一块内存块的大小,默认是16k。
lock:类型是ReentrantLock。因为会有多线程并发和回收ByteBuffer,所以使用锁控制并发,保证了线程的安全。
free:类型是Deque。缓存了指定大小的ByteBuffer对象。
waiters:类型是Deque队列。因为会有申请不到足够内存的线程,线程为了等待其他线程释放内存而阻塞等待,对应的Condition对象会进入该队列。
nonPooledAvailableMemory:非池化可使用的内存。
allocate()方法是向BufferPool申请ByteBuffer
public ByteBuffer allocate(int size, long maxTimeToBlockMs) throws InterruptedException {
//1.验证申请的内存是否大于总内存
if (size > this.totalMemory)
throw new IllegalArgumentException("Attempt to allocate " + size
+ " bytes, but there is a hard limit of "
+ this.totalMemory
+ " on memory allocations.");
ByteBuffer buffer = null;
//2.加锁,保证线程安全。
this.lock.lock();
if (this.closed) {
this.lock.unlock();
throw new KafkaException("Producer closed while allocating memory");
}
try {
// check if we have a free buffer of the right size pooled
//3.申请内存的大小是否是池化的内存大小,16k
if (size == poolableSize && !this.free.isEmpty())
//如果是就从池里Bytebuffer
return this.free.pollFirst();
// 池化内存空间的大小
int freeListSize = freeSize() * this.poolableSize;
//4.如果非池化可以空间加池化内存空间大于等于要申请的空间
if (this.nonPooledAvailableMemory + freeListSize >= size) {
// 如果申请的空间大小小于池化的大小,就从free队列里拿出一个池化的大小的Bytebuffer加到nonPooledAvailableMemory中
// 5.如果一个池化的大小的Bytebuffer不满足size,就持续释放池化内存Bytebuffer直到满足为止。
freeUp(size);
this.nonPooledAvailableMemory -= size;
//如果非池化可以空间加池化内存空间大于要申请的空间
} else {
// we are out of memory and will have to block
int accumulated = 0;
//创建对应的Condition
Condition moreMemory = this.lock.newCondition();
try {
//线程最长阻塞时间
long remainingTimeToBlockNs = TimeUnit.MILLISECONDS.toNanos(maxTimeToBlockMs);
//放入waiters集合中
this.waiters.addLast(moreMemory);
// 没有足够的空间就一直循环
while (accumulated < size) {
long startWaitNs = time.nanoseconds();
long timeNs;
boolean waitingTimeElapsed;
try {
//空间不够就阻塞,并设置超时时间。
waitingTimeElapsed = !moreMemory.await(remainingTimeToBlockNs, TimeUnit.NANOSECONDS);
} finally {
long endWaitNs = time.nanoseconds();
timeNs = Math.max(0L, endWaitNs - startWaitNs);
recordWaitTime(timeNs);
}
if (this.closed)
throw new KafkaException("Producer closed while allocating memory");
if (waitingTimeElapsed) {
this.metrics.sensor("buffer-exhausted-records").record();
throw new BufferExhaustedException("Failed to allocate memory within the configured max blocking time " + maxTimeToBlockMs + " ms.");
}
remainingTimeToBlockNs -= timeNs;
// check if we can satisfy this request from the free list,
// otherwise allocate memory
//ByteBuffer池化集合里是否有元素
if (accumulated == 0 && size == this.poolableSize && !this.free.isEmpty()) {
// just grab a buffer from the free list
buffer = this.free.pollFirst();
accumulated = size;
} else {
//尝试给nonPooledAvailableMemory扩容
freeUp(size - accumulated);
int got = (int) Math.min(size - accumulated, this.nonPooledAvailableMemory);
this.nonPooledAvailableMemory -= got;
//累计分配了多少空间
accumulated += got;
}
}
accumulated = 0;
} finally {
this.nonPooledAvailableMemory += accumulated;//把已经分配的内存还回nonPooledAvailableMemory
this.waiters.remove(moreMemory);//删除对应的condition
}
}
} finally {
// signal any additional waiters if there is more memory left
// over for them
try {
if (!(this.nonPooledAvailableMemory == 0 && this.free.isEmpty()) && !this.waiters.isEmpty())
this.waiters.peekFirst().signal();
} finally {
// Another finally... otherwise find bugs complains
lock.unlock();
}
}
if (buffer == null)
//非池化ByteBuffer分配内存
return safeAllocateByteBuffer(size);
else
return buffer;
}
这里先明确三个变量:
free:由固定大小ByteBuffer组成的集合。
nonPooledAvailableMemory:非池化可利用的内存。
size:申请的ByteBuffer大小。
第一步,验证申请的空间大小size是否大于总内存,BufferPool的总内存默认是32M。如果比总内存还大,就抛出异常。
第二步,因为会涉及到Deque的操作,而Deque不是线程安全的,这里要加锁,防止多线程操作引起的问题。
第三步,如果free不为空,而且申请的空间size和free的元素的大小相同,就从free中拿出一个ByteBuffer并返回,ByteBuffer申请成功。
第四步,如果不满足上述条件,free加上nonPooledAvailableMemory比要申请的大,就调用freeUp(size)方法凑齐足够的空间给size。
freeUp(size)方法源码参考:
private void freeUp(int size) {
while (!this.free.isEmpty() && this.nonPooledAvailableMemory < size)
this.nonPooledAvailableMemory += this.free.pollLast().capacity();
}
再来分析下释放空间的代码,deallocate()方法:
public void deallocate(ByteBuffer buffer, int size) {
lock.lock();
try {
//如果是池化ByteBuffer大小的ByteBuffer
if (size == this.poolableSize && size == buffer.capacity()) {
buffer.clear();
this.free.add(buffer);
} else {
//否则释放到nonPooledAvailableMemory
this.nonPooledAvailableMemory += size;
}
//拿出一个condition,并signal,唤醒阻塞。
Condition moreMem = this.waiters.peekFirst();
if (moreMem != null)
moreMem.signal();
} finally {
lock.unlock();
}
}
4.4.2 提高吞吐量
(1)buffer.memory:发送消息的缓冲区大小,默认值是32m,可以增加到64m
(2)batch.size:默认是16k。如果batch设置太小,会导致频繁网络请求,吞吐量下降;如果batch太大,会导致一条消息需要等待很久才能被发送出去,增加网络延时
(3)linger.ms:这个值默认是0,意思是消息立即被发送。一般设置一个5-100ms。如果linger.ms设置的太小,会导致频繁网络请求,吞吐量下降;如果linger.ms太长,会导致一条消息需要等待很久才能被发送出去,增加网络延时
(4)compression.type:默认是none,不压缩,但是也可以使用lz4压缩,效率还是不错的,压缩之后可以减小数据量,提升吞吐量,但是会加大producer的CPU开销
4.5 asks确认机制
分为三种情况
saks = 0, 发送方不关系数据有没有到达分区leader, 返回索引-1
asks = 1, 发送方需要确认在分区leader的位置, 返回具体索引
asks = all, 发送方确认发送到leader, 并且消息同步到follower(ISR里面的所有副本), 如果ISR里面只有leader, 和asks=1效果相同
可以引入最小副本数min.insync.replicas (leader+follower, 默认=1)进行确保副本都被同步
谨慎使用, 有些topic只有一个leader, 可能会导致消息发不出去
注: 在配置的时候同时也要配置kafka.offsets.topic.replication.factor=min.insync.replicas的数量, 否则会报错

4.6 数据去重
至少一次(At Least Once)
满足至少一次需要满足一下条件, 但是可能重复消费
- saks设置为all
- 分区副本大于等于2
- 最小副本数量min.insync.replicas大于等于2
最多一次(At Most Once)
设置asks为0, 但是可能会数据丢失
精确一次(Exactly Once)
对于比较重要的消息, 不能重复也不能丢失
- 幂等
- 至少一次
4.7 消费者优雅退出
原生API中
//注册JVM关闭时的回调钩子,当JVM关闭时调用此钩子。
Runtime.getRuntime().addShutdownHook(new Thread() {
public void run() {
System.out.println("Starting exit...");
//调用消费者的wakeup方法通知主线程退出
consumer.wakeup();
try {
//等待主线程退出
mainThread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
...
try {
// looping until ctrl-c, the shutdown hook will cleanup on exit
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
System.out.println(System.currentTimeMillis() + "-- waiting for data...");
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s\n",record.offset(), record.key(), record.value());
}
for (TopicPartition tp: consumer.assignment())
System.out.println("Committing offset at position:" + consumer.position(tp));
consumer.commitSync();
}
} catch (WakeupException e) {
// ignore for shutdown
} finally {
consumer.close();
System.out.println("Closed consumer and we are done");
}
tip: 当子线程中业务逻辑处理的时间很长时,那么主线程就会先于子线程提前结束,而如果想要主线程在子线程处理完以后再结束(比如需要子线程中返回的数据),那就可以子线程中使用 Thread .join()
SpringBoot中
@EventListener(ApplicationReadyEvent.class)
public void registerShutdownHook() {
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
// 创建Kafka消费者配置
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "my-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 创建Kafka消费者
Consumer<String, String> consumer = new KafkaConsumer<>(props);
// 暂停消费者
consumer.pause(consumer.assignment());
// 提交偏移量
consumer.commitSync();
// 关闭消费者
consumer.close();
System.out.println("Kafka Consumer gracefully shut down.");
}));
}
4.8 分区再均衡
在增加分区或者增加消费者时, 可能会分区再均衡, 分区重新分配消费者时可能造成消息重复消费
可以注册分区再均衡监听器
ConsumerRebalanceListener rebalanceListener = new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
// 在再均衡之前被调用
// 可以在此处提交偏移量,处理被撤销的分区数据等
for (TopicPartition partition : partitions) {
long offset = consumer.position(partition);
currentOffsets.put(partition, offset);
}
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
// 在再均衡之后被调用
// 可以在此处重新读取偏移量,处理重新分配的分区数据等
}
};
consumerFactory.getContainerProperties().setConsumerRebalanceListener(rebalanceListener);
5、高级特性
5.1 扩展性
5.1.1 broker扩容
1)在yaml中复制kafka-2,拷贝为新的节点,注意以下标注修改的地方!
#修改后的内容参考:cluster.yml
kafka-3: #改
container_name: kafka-3 #改
image: wurstmeister/kafka:2.12-2.2.2
ports:
- 10905:9092 #改
environment:
KAFKA_BROKER_ID: 3 #改
HOST_IP: 192.168.10.30
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_HOST_NAME: 192.168.10.30
KAFKA_ADVERTISED_PORT: 10905 #改
volumes:
- /etc/localtime:/etc/localtime
depends_on:
- zookeeper
完整的 cluster.yml
version: '3'
services:
zookeeper:
image: zookeeper:3.4.13
kafka-1:
container_name: kafka-1
image: wurstmeister/kafka:2.12-2.2.2
ports:
- 10903:9092
environment:
KAFKA_BROKER_ID: 1
HOST_IP: 192.168.10.30
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
#docker部署必须设置外部可访问ip和端口,否则注册进zk的地址将不可达造成外部无法连接
KAFKA_ADVERTISED_HOST_NAME: 192.168.10.30
KAFKA_ADVERTISED_PORT: 10903
volumes:
- /etc/localtime:/etc/localtime
depends_on:
- zookeeper
kafka-2:
container_name: kafka-2
image: wurstmeister/kafka:2.12-2.2.2
ports:
- 10904:9092
environment:
KAFKA_BROKER_ID: 2
HOST_IP: 192.168.10.30
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_HOST_NAME: 192.168.10.30
KAFKA_ADVERTISED_PORT: 10904
volumes:
- /etc/localtime:/etc/localtime
depends_on:
- zookeeper
km:
image: liggdocker/km:2002
ports:
- 10906:9000
depends_on:
- zookeeper
kafka-3: #改
container_name: kafka-3 #改
image: wurstmeister/kafka:2.12-2.2.2
ports:
- 10905:9092 #改
environment:
KAFKA_BROKER_ID: 3 #改
HOST_IP: 192.168.10.30
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_HOST_NAME: 192.168.10.30
KAFKA_ADVERTISED_PORT: 10905 #改
volumes:
- /etc/localtime:/etc/localtime
depends_on:
- zookeeper
2)更新docker集群信息
docker-compose -f cluster.yml up -d
#启动消息
kafka_zookeeper_1 is up-to-date
kafka_km_1 is up-to-date
kafka-1 is up-to-date
kafka-2 is up-to-date
Creating kafka-3 ... done
3)进命令行,或打开km查看新的broker信息
5.1.2 分区扩容
1)使用km对test主题增加分区到3个,看分区分配机器情况

可以指定新分区数量,及分配到的机器

2)注意问题
新加分区或重新调整分区,已经启动的客户端会动态更新对应的分配信息,不需要重启。
但是!!!
在同步变更消息的过程中有可能会丢失消息
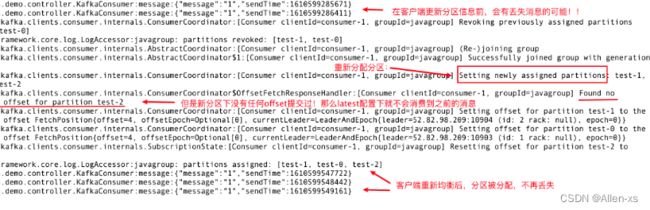
原因:
因为新分区没有任何offset提交记录
所以会在重新分配分区后从末尾开始消费!
那么分配前的那些消息就不会消费到。而分配后再发送的不会受影响,可以正常消费
分区分配正常后,查看偏移量提交信息,没问题:

km的Consumer页签里也可以查看偏移量信息:

5.2 高可用
以上动态扩容操作是怎么实现的呢?集群中必然有一个节点协调了相关操作。
这台协调者,就是controller节点。
controller节点是其中的一台broker,所有broker都有可能成为controller
当前controller宕机后,其他就会参与竞争,选出新的controller,保持集群对外的高可用
5.2.1 节点选举
1)查找controller,找到它所在的broker
#查找docker进程,找到zookeeper的容器
[root@iZ8vb3a9qxofwannyywl6zZ ~]# docker ps --format "table{{.ID}}\\t{{.Names}}\\t{{.Ports}}"
CONTAINER ID NAMES PORTS
75318748caab kafka-3 0.0.0.0:10905->9092/tcp
4807d188a180 kafka_km_1 0.0.0.0:10906->9000/tcp
4453eb0b2a36 kafka-2 0.0.0.0:10904->9092/tcp
d6fd814a0851 kafka-1 0.0.0.0:10903->9092/tcp
8c1fc2cc6e9a kafka_zookeeper_1 2181/tcp, 2888/tcp, 3888/tcp
#进入容器,连上zk
[root@iZ8vb3a9qxofwannyywl6zZ ~]# docker exec -it kafka_zookeeper_1 sh
/zookeeper-3.4.13 #
/zookeeper-3.4.13 # zkCli.sh
Connecting to localhost:2181
#查询当前controller是哪个节点,发现是2号机器(有可能是其他节点,找到这个brokerid,下面要用!)
[zk: localhost:2181(CONNECTED) 6] get /controller
{"version":1,"brokerid":2,"timestamp":"1610500701187"}
#controller变更的次数
[zk: localhost:2181(CONNECTED) 7] get /controller_epoch
1
2)docker-compose停掉它!
#docker pause 暂停容器的服务,注意是上面找到的那台broker
[root@iZ8vb3a9qxofwannyywl6zZ ~]# docker pause kafka-2
kafka-2
#查看状态,发现(Paused)
[root@iZ8vb3a9qxofwannyywl6zZ ~]# docker ps | grep kafka-2
4453eb0b2a36 wurstmeister/kafka:2.12-2.2.2 "start-kafka.sh" 2 days ago Up 2 days (Paused) 0.0.0.0:10904->9092/tcp kafka-2
#再次按 1)的步骤进入zk容器,查看当前controller,已经变为3号
[zk: localhost:2181(CONNECTED) 0] get /controller
{"version":1,"brokerid":3,"timestamp":"1610679583216"}
#变更次数加了1
[zk: localhost:2181(CONNECTED) 1] get /controller_epoch
2
5.2.2 原理剖析
当控制器被关闭或者与Zookeeper系统断开连接时,Zookeeper系统上的/controller临时节点就会被清除。
Kafka集群中的监听器会接收到变更通知,各个代理节点会尝试到Zookeeper系统中创建它。
第一个成功在Zookeeper系统中创建的代理节点,将会成为新的控制器。
每个新选举出来的控制器,会在Zookeeper系统中递增controller_epoch的值。
附:详细流程图

6、底层架构
6.1 存储架构
6.1.1 分段存储
开篇讲过,kafka每个主题可以有多个分区,每个分区在它所在的broker上创建一个文件夹
每个分区又分为多个段,每个段两个文件,log文件里顺序存消息,index文件里存消息的索引
段的命名直接以当前段的第一条消息的offset为名
注意是偏移量,不是序号! 第几条消息 = 偏移量 + 1。类似数组长度和下标。
所以offset从0开始(可以开新队列新groupid消费第一条消息打印offset得到验证)
![]()
例如:
0.log -> 有8条,offset为 0-7,[0, 8)
8.log -> 有两条,offset为 8-9,[8, 10)
10.log -> 有xx条,offset从10-xx,[10, 10 + xx)

6.1.2 日志索引
每个log文件配备一个索引文件 *.index
/opt/kafka/bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files test-0/00000000000000000000.index
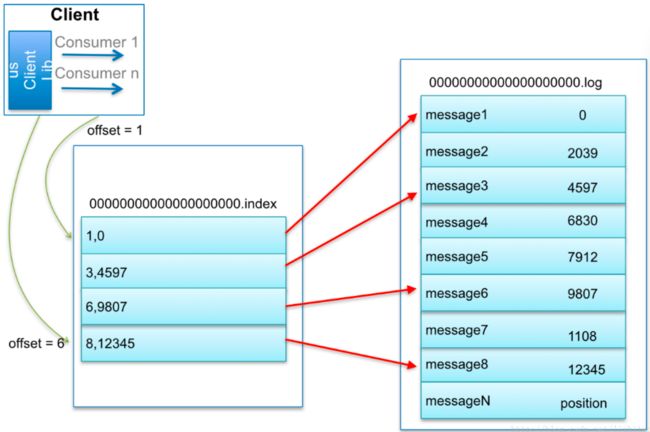
综合上述,来看一个消息的查找:
- consumer发起请求要求从offset=6的消息开始消费
- kafka直接根据文件名大小,发现6号消息在00000.log这个文件里
- 那文件找到了,它在文件的哪个位置呢?
- 根据index文件,发现 (6 , 9807),说明消息藏在这里!
- 从log文件的 9807 位置开始读取。
- 那读多长呢?简单,读到下一条消息的偏移量停止就可以了
6.1.3 日志删除
Kafka作为消息中间件,数据需要按照一定的规则删除,否则数据量太大会把集群存储空间占满。
删除数据方式:
- 按照时间,超过一段时间后删除过期消息
- 按照消息大小,消息数量超过一定大小后删除最旧的数据
Kafka删除数据的最小单位:segment,也就是直接干掉文件!一删就是一个log和index文件
6.1.4 存储验证
1)数据准备
将broker 2和3 停掉,只保留1
docker pause kafka-2 kafka-3
2)删掉test主题,通过km新建一个test主题,加2个分区
新建时,注意下面的选项:
segment.bytes = 1000 ,即:每个log文件到达1000byte时,开始创建新文件
删除策略:
retention.bytes = 2000,即:超出2000byte的旧日志被删除
retention.ms = 60000,即:超出1分钟后的旧日志被删除
以上任意一条满足,就会删除。
3)进入kafka-1这台容器
docker exec -it kafka-1 sh
#查看容器中的文件信息
/ # ls /
bin dev etc home kafka lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
/ # cd /kafka/
/kafka # ls
kafka-logs-d0b9c75080d6
/kafka # cd kafka-logs-d0b9c75080d6/
/kafka/kafka-logs-d0b9c75080d6 # ls -l | grep test
drwxr-xr-x 2 root root 4096 Jan 15 14:35 test-0
drwxr-xr-x 2 root root 4096 Jan 15 14:35 test-1
#2个分区的日志文件清单,注意当前还没有任何消息写进来
#timeindex:日志的时间信息
#leader-epoch,下面会讲到
/kafka/kafka-logs-d0b9c75080d6 # ls -lR test-*
test-0:
total 4
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 0 Jan 15 14:35 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
test-1:
total 4
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 0 Jan 15 14:35 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
4)往里灌数据。启动项目通过swagger发送消息
注意!边发送边查看上一步的文件列表信息!

#先发送2条,消息开始进来,log文件变大!消息在两个分区之间逐个增加。
/kafka/kafka-logs-d0b9c75080d6 # ls -lR test-*
test-0:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 875 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
test-1:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 875 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
#继续逐条发送,返回再来看文件,大小为1000,到达边界!
/kafka/kafka-logs-d0b9c75080d6 # ls -lR test-*
test-0:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 1000 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
test-1:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 1000 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
#继续发送消息!1号分区的log文件开始分裂
#说明第8条消息已经进入了第二个log
/kafka/kafka-logs-d0b9c75080d6 # ls -lR test-*
test-0:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 1000 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
test-1:
total 20
-rw-r--r-- 1 root root 0 Jan 15 14:46 00000000000000000000.index
-rw-r--r-- 1 root root 1000 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 12 Jan 15 14:46 00000000000000000000.timeindex
-rw-r--r-- 1 root root 10485760 Jan 15 14:46 00000000000000000008.index
-rw-r--r-- 1 root root 125 Jan 15 14:46 00000000000000000008.log #第二个log文件!
-rw-r--r-- 1 root root 10 Jan 15 14:46 00000000000000000008.snapshot
-rw-r--r-- 1 root root 10485756 Jan 15 14:46 00000000000000000008.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
#持续发送,另一个分区也开始分离
/kafka/kafka-logs-d0b9c75080d6 # ls -lR test-*
test-0:
total 20
-rw-r--r-- 1 root root 0 Jan 15 15:55 00000000000000000000.index
-rw-r--r-- 1 root root 1000 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 12 Jan 15 15:55 00000000000000000000.timeindex
-rw-r--r-- 1 root root 10485760 Jan 15 15:55 00000000000000000008.index
-rw-r--r-- 1 root root 625 Jan 15 15:55 00000000000000000008.log
-rw-r--r-- 1 root root 10 Jan 15 15:55 00000000000000000008.snapshot
-rw-r--r-- 1 root root 10485756 Jan 15 15:55 00000000000000000008.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
test-1:
total 20
-rw-r--r-- 1 root root 0 Jan 15 14:46 00000000000000000000.index
-rw-r--r-- 1 root root 1000 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 12 Jan 15 14:46 00000000000000000000.timeindex
-rw-r--r-- 1 root root 10485760 Jan 15 14:46 00000000000000000008.index
-rw-r--r-- 1 root root 750 Jan 15 15:55 00000000000000000008.log
-rw-r--r-- 1 root root 10 Jan 15 14:46 00000000000000000008.snapshot
-rw-r--r-- 1 root root 10485756 Jan 15 14:46 00000000000000000008.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
#持续发送消息,分区越来越多。
#过一段时间后再来查看,清理任务将会执行,超出的日志被删除!(默认调度间隔5min)
#log.retention.check.interval.ms 参数指定
/kafka/kafka-logs-d0b9c75080d6 # ls -lR test-*
test-0:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 19:12 00000000000000000119.index
-rw-r--r-- 1 root root 0 Jan 15 19:12 00000000000000000119.log
-rw-r--r-- 1 root root 10 Jan 15 19:12 00000000000000000119.snapshot
-rw-r--r-- 1 root root 10485756 Jan 15 19:12 00000000000000000119.timeindex
-rw-r--r-- 1 root root 10 Jan 15 19:12 leader-epoch-checkpoint
test-1:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 19:12 00000000000000000119.index
-rw-r--r-- 1 root root 0 Jan 15 19:12 00000000000000000119.log
-rw-r--r-- 1 root root 10 Jan 15 19:12 00000000000000000119.snapshot
-rw-r--r-- 1 root root 10485756 Jan 15 19:12 00000000000000000119.timeindex
-rw-r--r-- 1 root root 10 Jan 15 19:12 leader-epoch-checkpoint
6.2 零拷贝
Kafka 在执行消息的写入和读取这么快,其中的一个原因是零拷贝(Zero-copy)技术
6.2.1 传统文件读写

传统读写,涉及到 4 次数据的复制。但是这个过程中,数据完全没有变化,仅仅是想从磁盘把数据送到网卡。
那有没有办法不绕这一圈呢?让磁盘和网卡之类的外围设备直接访问内存,而不经过cpu?
有! 这就是DMA(Direct Memory Access 直接内存访问)。
6.2.2 DMA
DMA其实是由DMA芯片(硬件支持)来控制的。通过DMA控制芯片,可以让网卡等外部设备直接去读取内存,而不是由cpu来回拷贝传输。这就是所谓的零拷贝
目前计算机主流硬件基本都支持DMA,就包括硬盘和网卡。
kafka就是调取操作系统的sendfile,借助DMA来实现零拷贝数据传输的

6.2.3 java实现
为加深理解,类比为java中的零拷贝:
-
在Java中的零拷贝是通过java.nio.channels.FileChannel中的transferTo方法来实现的
-
transferTo方法底层通过native调操作系统的sendfile
-
操作系统sendfile负责把数据从某个fd(linux file descriptor)传输到另一个fd
备注:linux下所有的设备都是一个文件描述符fd
代码参考:
File file = new File("0.log");
RandomAccessFile raf = new RandomAccessFile(file, "rw");
//文件通道,来源
FileChannel fileChannel = raf.getChannel();
//网络通道,去处
SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress("1.1.1.1", 1234));
//对接上,通过transfer直接送过去
fileChannel.transferTo(0, fileChannel.size(), socketChannel);
6.3 分区一致性
6.3.1 水位值
1)先回顾两个值:

2)再看下几个值的存储位置:
注意!分区是有leader和follower的,最新写的消息会进入leader,follower从leader不停的同步
无论leader还是follower,都有自己的HW和LEO,存储在各自分区所在的磁盘上
leader多一个Remote LEO,它表示针对各个follower的LEO,leader又额外记了一份!
leader会拿这些remote值里最小的来更新自己的hw
6.3.2 同步原理

1)leader.LEO
这个很简单,每次producer有新消息发过来,就会增加
2)其他值
另外的4个值初始化都是 0
他们的更新由follower的fetch(同步消息线程)得到的数据来决定!
如果把fetch看做是leader上提供的方法,由follower远程请求调用,那么它的伪代码大概是这个样子:
//java伪代码!
//follower端的操作,不停的请求从leader获取最新数据
class Follower{
private List<Message> messages;
private HW hw;
private LEO leo;
@Schedule("不停的向leader发起同步请求")
void execute(){
//向leader发起fetch请求,将自己的leo传过去
//leader返回leo之后最新的消息,以及leader的hw
LeaderReturn lr = leader.fetch(this.leo) ;
//存消息
this.messages.addAll(lr.newMsg);
//增加follower的leo值
this.leo = this.leo + lr.newMsg.length;
//比较自己的leo和leader的hw,取两者小的,作为follower的hw
this.hw = min(this.leo , lr.leaderHW);
}
}
//leader返回的报文
class LeaderReturn{
//新增的消息
List<Messages> newMsg;
//leader的hw
HW leaderHW;
}
//leader在接到follower的fetch请求时,做的逻辑
class Leader{
private List<Message> messages;
private LEO leo;
private HW hw;
//Leader比follower多了个Remote!
//注意!如果有多个副本,那么RemoteLEO也有多个,每个副本对应一个
private RemoteLEO remoteLEO;
//接到follower的fetch请求时,leader做的事情
LeaderReturn fetch(LEO followerLEO){
//根据follower传过来的leo,来更新leader的remote
this.remoteLEO = followerLEO ;
//然后取ISR(所有可用副本)的最小leo作为leader的hw
this.hw = min(this.leo , this.remoteLEO) ;
//从leader的消息列表里,查找大于follower的leo的所有新消息
List<Message> newMsg = queryMsg(followerLEO) ;
//将最新的消息(大于follower leo的那些),以及leader的hw返回给follower
LeaderReturn lr = new LeaderReturn(newMsg , this.hw)
return lr;
}
}
6.3.3 Leader Epoch
1)产生的背景
0.11版本之前的kafka,完全借助hw作为消息的基准,不管leo。
发生故障后的规则:
- follower故障再次恢复后,从磁盘读取hw的值并从hw开始剔除后面的消息,并同步leader消息
- leader故障后,新当选的leader的hw作为新的分区hw,其余节点按照此hw进行剔除数据,并重新同步
- 上述根据hw进行数据恢复会出现数据丢失和不一致的情况
假设:
有两个副本:leader(A),follower(B)
场景一:丢数据
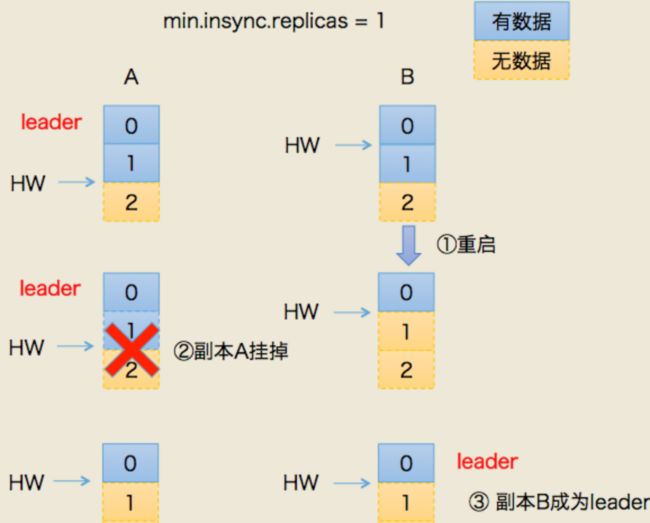
- 某个时间点B挂了。当它恢复后,以挂之前的hw为准,设置 leo = hw
- 这就造成一个问题:现实中,leo 很可能是 大于 hw的。leo被回退了!
- 如果这时候,恰恰A也挂掉了。kafka会重选leader,B被选中。
- 过段时间,A恢复后变成follower,从B开始同步数据。
- 问题来了!上面说了,B的数据是被回退过的,以它为基准会有问题
- 最终结果:两者的数据都发生丢失,没有地方可以找回!
场景二:数据不一致
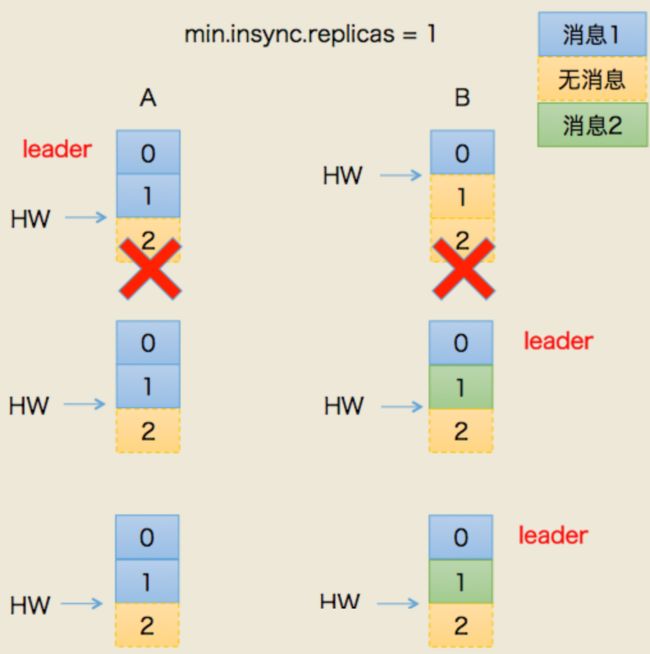
- 这次假设AB全挂了。比较惨
- B先恢复。但是它的hw有可能挂之前没从A同步过来(原来A是leader)
- 假设,A.hw = 2 , B.hw = 1
- B恢复后,集群里只有它自己,所以被选为leader,开始接受新消息
- B.hw上涨,变成2
- 然后,A恢复,原来A.hw = 2 ,恢复后以B的hw,也就是2为基准开始同步。
- 问题来了!B当leader后新接到的2号消息是不会同步给A的,A一直保留着它当leader时的旧数据
- 最终结果:数据不一致了!
2)改进思路
0.11之后,kafka改进了hw做主的规则,这就是leader epoch
leader epoch给leader节点带了一个版本号,类似于乐观锁的设计。
它的思想是,一旦发生机器故障,重启之后,不再机械的将leo退回hw
而是借助epoch的版本信息,去请求当前leader,让它去算一算leo应该是什么
3)实现原理
对比上面丢数据的问题:
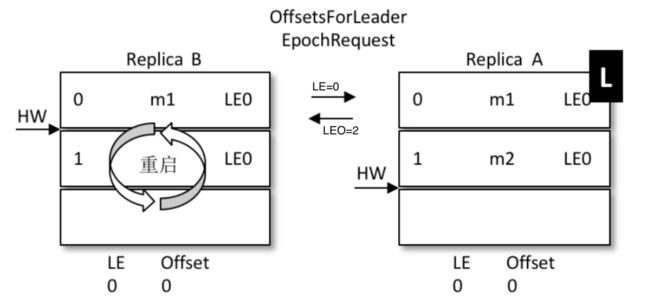
- A为(leo=2 , hw=2),B为(leo=2 , hw=1)
- B重启,但是B不再着急将leo打回hw,而是发起一个Epoch请求给当前leader,也就是A
- A收到LE=0后,发现和自己的LE一样,说明B在挂掉前后,leader没变,都是A自己
- 那么A就将自己的leo值返回给B,也就是数字2
- B收到2后和自己的leo比对取较小值,发现也是2,那么不再退回到hw的1
- 没有回退,也就是信息1的位置没有被覆盖,最大程度的保护了数据
- 如果和上面一样的场景,A挂掉,B被选为leader

-
那么A再次启动时后,从B开始同步数据
-
因为B之前没有回退,1号信息得到了保留
-
同时,B的LE(epoch号码)开始增加,从0变成1,offset记录为B当leader时的位置,也就是2
-
A传过来的epoch为0,B是1,不相等。那么取大于0的所有epoch里最小的
(现实中可能发生了多次重新选主,有多条epoch)
-
其实就是LE=1的那条。现实中可能有多条。并找到它对应的offset(也就是2)给A返回去
-
最终A得到了B同步过来的数据
再来看一致性问题的解决:

-
还是上面的场景,AB同时挂掉,但是hw还没同步,那么A.hw=2 , B.hw=1
-
B先启动被选成了leader,新leader选举后,epoch加了一条记录(参考下图,LE=1,这时候offset=1)
-
表示B从1开始往后继续写数据,新来了条信息,内容为m3,写到1号位
-
A启动前,集群只有B自己,消息被确认,hw上涨到2,变成下面的样子

-
A开始恢复,启动后向B发送epoch请求,将自己的LE=0告诉leader,也就是B
-
B发现自己的LE不同,同样去大于0的LE里最小的那条,也就是1 , 对应的offset也是1,返回给A
-
A从1开始同步数据,将自己本地的数据截断、覆盖,hw上升到2
-
那么最新的写入的m3从B给同步到了A,并覆盖了A上之前的旧数据m2
-
结果:数据保持了一致
附:epochRequest的详细流程图
