Spark MLlib快速入门(1)逻辑回归、Kmeans、决策树、Pipeline、交叉验证
Spark MLlib快速入门(1)逻辑回归、Kmeans、决策树案例
除了scikit-learn外,在spark中也提供了机器学习库,即Spark MLlib。
在Spark MLlib机器学习库提供两套算法实现的API:基于RDD API和基于DataFrame API。今天,主要介绍下DataFrame API的使用,不涉及算法的原理。
主要提供的算法如下:
-
分类
- 逻辑回归、贝叶斯支持向量机
-
聚类
- K-均值
-
推荐
- 交替最小二乘法
-
回归
- 线性回归
-
树
- 决策树、随机森林
1 Spark MLlib中逻辑回归在鸢尾花数据集上的应用
鸢尾花数据集,总共150条数据,分为三种类别的鸢尾花。
鸢尾花数据集属于分类算法,构建分类模型,此处使用逻辑回归分类算法构建分类模型,进行预测。
全部基于DataFrame API算法库和特征工程函数使用。
使用的spark版本为2.3。
1.1 读取数据
package com.yyds.tags.ml.classification
import org.apache.spark.ml.classification.{LogisticRegression, LogisticRegressionModel}
import org.apache.spark.ml.feature.{Normalizer, StringIndexer, StringIndexerModel, VectorAssembler}
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.types.{DoubleType, StringType, StructType}
import org.apache.spark.storage.StorageLevel
object IrisClassification {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[4]")
.config("spark.sql.shuffle.partitions",4)
.getOrCreate()
import spark.implicits._
// TODO step1 -> 读取数据
val isrsSchema: StructType = new StructType()
.add("sepal_length",DoubleType,nullable = true)
.add("sepal_width",DoubleType,nullable = true)
.add("petal_length",DoubleType,nullable = true)
.add("petal_width",DoubleType,nullable = true)
.add("category",StringType, nullable = true)
val rawIrisDF: DataFrame = spark.read
.option("sep",",")
// 当首行不是列名称时候,需要自动设置schema
.option("header","false")
.option("inferSchema","false")
.schema(isrsSchema)
.csv("datas/iris/iris.data")
rawIrisDF.printSchema()
rawIrisDF.show(10,truncate = false)
}
}
root
|-- sepal_length: double (nullable = true)
|-- sepal_width: double (nullable = true)
|-- petal_length: double (nullable = true)
|-- petal_width: double (nullable = true)
|-- category: string (nullable = true)
+------------+-----------+------------+-----------+-----------+
|sepal_length|sepal_width|petal_length|petal_width|category |
+------------+-----------+------------+-----------+-----------+
|5.1 |3.5 |1.4 |0.2 |Iris-setosa|
|4.9 |3.0 |1.4 |0.2 |Iris-setosa|
|4.7 |3.2 |1.3 |0.2 |Iris-setosa|
|4.6 |3.1 |1.5 |0.2 |Iris-setosa|
|5.0 |3.6 |1.4 |0.2 |Iris-setosa|
|5.4 |3.9 |1.7 |0.4 |Iris-setosa|
|4.6 |3.4 |1.4 |0.3 |Iris-setosa|
|5.0 |3.4 |1.5 |0.2 |Iris-setosa|
|4.4 |2.9 |1.4 |0.2 |Iris-setosa|
|4.9 |3.1 |1.5 |0.1 |Iris-setosa|
+------------+-----------+------------+-----------+-----------+
1.2 特征工程
// TODO step2 -> 特征工程
/*
1、类别转换数值类型
类别特征索引化 -> label
2、组合特征值
features: Vector
*/
// 1、类别特征转换 StringIndexer
val indexerModel: StringIndexerModel = new StringIndexer()
.setInputCol("category")
.setOutputCol("label")
.fit(rawIrisDF)
val df1: DataFrame = indexerModel.transform(rawIrisDF)
// 2、组合特征值 VectorAssembler
val assembler: VectorAssembler = new VectorAssembler()
// 设置特征列名称
.setInputCols(rawIrisDF.columns.dropRight(1))
.setOutputCol("raw_features")
val rawFeaturesDF: DataFrame = assembler.transform(df1)
// 3、特征值正则化,使用L2正则
val normalizer: Normalizer = new Normalizer()
.setInputCol("raw_features")
.setOutputCol("features")
.setP(2.0)
val featuresDF: DataFrame = normalizer.transform(rawFeaturesDF)
// 将数据集缓存,LR算法属于迭代算法,使用多次
featuresDF.persist(StorageLevel.MEMORY_AND_DISK).count()
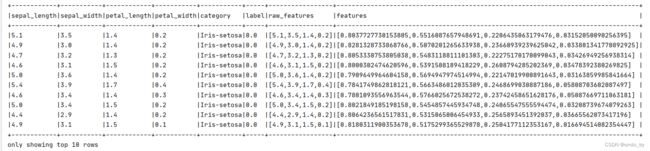
featuresDF.printSchema()
featuresDF.show(10, truncate = false)
root
|-- sepal_length: double (nullable = true)
|-- sepal_width: double (nullable = true)
|-- petal_length: double (nullable = true)
|-- petal_width: double (nullable = true)
|-- category: string (nullable = true)
|-- label: double (nullable = true)
|-- raw_features: vector (nullable = true)
|-- features: vector (nullable = true)
1.3 训练模型
// TODO step3 -> 模型训练
val lr: LogisticRegression = new LogisticRegression()
// 设置列名称
.setLabelCol("label")
.setFeaturesCol("features")
.setPredictionCol("prediction")
// 设置迭代次数
.setMaxIter(10)
.setRegParam(0.3) // 正则化参数
.setElasticNetParam(0.8) // 弹性网络参数:L1正则和L2正则联合使用
val lrModel: LogisticRegressionModel = lr.fit(featuresDF)
1.4 模型预测
// TODO step4 -> 使用模型预测
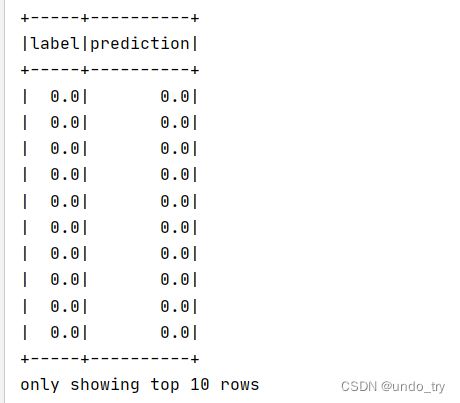
val predictionDF: DataFrame = lrModel.transform(featuresDF)
predictionDF
// 获取真实标签类别和预测标签类别
.select("label", "prediction")
.show(10)
1.5 模型评估
// TODO step5 -> 模型评估:准确度 = 预测正确的样本数 / 所有的样本数
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
.setMetricName("accuracy")
# accuracy = 0.9466666666666667
println(s"accuracy = ${evaluator.evaluate(predictionDF)}")
1.6 模型的保存与加载
// TODO step6 -> 模型调优,此处省略
// TODO step7 -> 模型保存与加载
val modelPath = s"datas/models/lrModel-${System.currentTimeMillis()}"
// 保存模型
lrModel.save(modelPath)
// 加载模型
val loadLrModel = LogisticRegressionModel.load(modelPath)
// 模型预测
loadLrModel.transform(
Seq(
Vectors.dense(Array(5.1,3.5,1.4,0.2))
)
.map(x => Tuple1.apply(x))
.toDF("features")
).show(10, truncate = false)
// 应用结束,关闭资源
spark.stop()

2 Spark MLlib中KMeans在鸢尾花数据集上的应用
2.1 读取数据集
iris_kmeans.txt数据如下
1 1:5.1 2:3.5 3:1.4 4:0.2
1 1:4.9 2:3.0 3:1.4 4:0.2
1 1:4.7 2:3.2 3:1.3 4:0.2
1 1:4.6 2:3.1 3:1.5 4:0.2
1 1:5.0 2:3.6 3:1.4 4:0.2
1 1:5.4 2:3.9 3:1.7 4:0.4
1 1:4.6 2:3.4 3:1.4 4:0.3
1 1:5.0 2:3.4 3:1.5 4:0.2
1 1:4.4 2:2.9 3:1.4 4:0.2
1 1:4.9 2:3.1 3:1.5 4:0.1
1 1:5.4 2:3.7 3:1.5 4:0.2
1 1:4.8 2:3.4 3:1.6 4:0.2
1 1:4.8 2:3.0 3:1.4 4:0.1
1 1:4.3 2:3.0 3:1.1 4:0.1
1 1:5.8 2:4.0 3:1.2 4:0.2
1 1:5.7 2:4.4 3:1.5 4:0.4
1 1:5.4 2:3.9 3:1.3 4:0.4
1 1:5.1 2:3.5 3:1.4 4:0.3
1 1:5.7 2:3.8 3:1.7 4:0.3
1 1:5.1 2:3.8 3:1.5 4:0.3
1 1:5.4 2:3.4 3:1.7 4:0.2
1 1:5.1 2:3.7 3:1.5 4:0.4
1 1:4.6 2:3.6 3:1.0 4:0.2
1 1:5.1 2:3.3 3:1.7 4:0.5
1 1:4.8 2:3.4 3:1.9 4:0.2
1 1:5.0 2:3.0 3:1.6 4:0.2
1 1:5.0 2:3.4 3:1.6 4:0.4
1 1:5.2 2:3.5 3:1.5 4:0.2
1 1:5.2 2:3.4 3:1.4 4:0.2
1 1:4.7 2:3.2 3:1.6 4:0.2
1 1:4.8 2:3.1 3:1.6 4:0.2
1 1:5.4 2:3.4 3:1.5 4:0.4
1 1:5.2 2:4.1 3:1.5 4:0.1
1 1:5.5 2:4.2 3:1.4 4:0.2
1 1:4.9 2:3.1 3:1.5 4:0.1
1 1:5.0 2:3.2 3:1.2 4:0.2
1 1:5.5 2:3.5 3:1.3 4:0.2
1 1:4.9 2:3.1 3:1.5 4:0.1
1 1:4.4 2:3.0 3:1.3 4:0.2
1 1:5.1 2:3.4 3:1.5 4:0.2
1 1:5.0 2:3.5 3:1.3 4:0.3
1 1:4.5 2:2.3 3:1.3 4:0.3
1 1:4.4 2:3.2 3:1.3 4:0.2
1 1:5.0 2:3.5 3:1.6 4:0.6
1 1:5.1 2:3.8 3:1.9 4:0.4
1 1:4.8 2:3.0 3:1.4 4:0.3
1 1:5.1 2:3.8 3:1.6 4:0.2
1 1:4.6 2:3.2 3:1.4 4:0.2
1 1:5.3 2:3.7 3:1.5 4:0.2
1 1:5.0 2:3.3 3:1.4 4:0.2
2 1:7.0 2:3.2 3:4.7 4:1.4
2 1:6.4 2:3.2 3:4.5 4:1.5
2 1:6.9 2:3.1 3:4.9 4:1.5
2 1:5.5 2:2.3 3:4.0 4:1.3
2 1:6.5 2:2.8 3:4.6 4:1.5
2 1:5.7 2:2.8 3:4.5 4:1.3
2 1:6.3 2:3.3 3:4.7 4:1.6
2 1:4.9 2:2.4 3:3.3 4:1.0
2 1:6.6 2:2.9 3:4.6 4:1.3
2 1:5.2 2:2.7 3:3.9 4:1.4
2 1:5.0 2:2.0 3:3.5 4:1.0
2 1:5.9 2:3.0 3:4.2 4:1.5
2 1:6.0 2:2.2 3:4.0 4:1.0
2 1:6.1 2:2.9 3:4.7 4:1.4
2 1:5.6 2:2.9 3:3.6 4:1.3
2 1:6.7 2:3.1 3:4.4 4:1.4
2 1:5.6 2:3.0 3:4.5 4:1.5
2 1:5.8 2:2.7 3:4.1 4:1.0
2 1:6.2 2:2.2 3:4.5 4:1.5
2 1:5.6 2:2.5 3:3.9 4:1.1
2 1:5.9 2:3.2 3:4.8 4:1.8
2 1:6.1 2:2.8 3:4.0 4:1.3
2 1:6.3 2:2.5 3:4.9 4:1.5
2 1:6.1 2:2.8 3:4.7 4:1.2
2 1:6.4 2:2.9 3:4.3 4:1.3
2 1:6.6 2:3.0 3:4.4 4:1.4
2 1:6.8 2:2.8 3:4.8 4:1.4
2 1:6.7 2:3.0 3:5.0 4:1.7
2 1:6.0 2:2.9 3:4.5 4:1.5
2 1:5.7 2:2.6 3:3.5 4:1.0
2 1:5.5 2:2.4 3:3.8 4:1.1
2 1:5.5 2:2.4 3:3.7 4:1.0
2 1:5.8 2:2.7 3:3.9 4:1.2
2 1:6.0 2:2.7 3:5.1 4:1.6
2 1:5.4 2:3.0 3:4.5 4:1.5
2 1:6.0 2:3.4 3:4.5 4:1.6
2 1:6.7 2:3.1 3:4.7 4:1.5
2 1:6.3 2:2.3 3:4.4 4:1.3
2 1:5.6 2:3.0 3:4.1 4:1.3
2 1:5.5 2:2.5 3:4.0 4:1.3
2 1:5.5 2:2.6 3:4.4 4:1.2
2 1:6.1 2:3.0 3:4.6 4:1.4
2 1:5.8 2:2.6 3:4.0 4:1.2
2 1:5.0 2:2.3 3:3.3 4:1.0
2 1:5.6 2:2.7 3:4.2 4:1.3
2 1:5.7 2:3.0 3:4.2 4:1.2
2 1:5.7 2:2.9 3:4.2 4:1.3
2 1:6.2 2:2.9 3:4.3 4:1.3
2 1:5.1 2:2.5 3:3.0 4:1.1
2 1:5.7 2:2.8 3:4.1 4:1.3
3 1:6.3 2:3.3 3:6.0 4:2.5
3 1:5.8 2:2.7 3:5.1 4:1.9
3 1:7.1 2:3.0 3:5.9 4:2.1
3 1:6.3 2:2.9 3:5.6 4:1.8
3 1:6.5 2:3.0 3:5.8 4:2.2
3 1:7.6 2:3.0 3:6.6 4:2.1
3 1:4.9 2:2.5 3:4.5 4:1.7
3 1:7.3 2:2.9 3:6.3 4:1.8
3 1:6.7 2:2.5 3:5.8 4:1.8
3 1:7.2 2:3.6 3:6.1 4:2.5
3 1:6.5 2:3.2 3:5.1 4:2.0
3 1:6.4 2:2.7 3:5.3 4:1.9
3 1:6.8 2:3.0 3:5.5 4:2.1
3 1:5.7 2:2.5 3:5.0 4:2.0
3 1:5.8 2:2.8 3:5.1 4:2.4
3 1:6.4 2:3.2 3:5.3 4:2.3
3 1:6.5 2:3.0 3:5.5 4:1.8
3 1:7.7 2:3.8 3:6.7 4:2.2
3 1:7.7 2:2.6 3:6.9 4:2.3
3 1:6.0 2:2.2 3:5.0 4:1.5
3 1:6.9 2:3.2 3:5.7 4:2.3
3 1:5.6 2:2.8 3:4.9 4:2.0
3 1:7.7 2:2.8 3:6.7 4:2.0
3 1:6.3 2:2.7 3:4.9 4:1.8
3 1:6.7 2:3.3 3:5.7 4:2.1
3 1:7.2 2:3.2 3:6.0 4:1.8
3 1:6.2 2:2.8 3:4.8 4:1.8
3 1:6.1 2:3.0 3:4.9 4:1.8
3 1:6.4 2:2.8 3:5.6 4:2.1
3 1:7.2 2:3.0 3:5.8 4:1.6
3 1:7.4 2:2.8 3:6.1 4:1.9
3 1:7.9 2:3.8 3:6.4 4:2.0
3 1:6.4 2:2.8 3:5.6 4:2.2
3 1:6.3 2:2.8 3:5.1 4:1.5
3 1:6.1 2:2.6 3:5.6 4:1.4
3 1:7.7 2:3.0 3:6.1 4:2.3
3 1:6.3 2:3.4 3:5.6 4:2.4
3 1:6.4 2:3.1 3:5.5 4:1.8
3 1:6.0 2:3.0 3:4.8 4:1.8
3 1:6.9 2:3.1 3:5.4 4:2.1
3 1:6.7 2:3.1 3:5.6 4:2.4
3 1:6.9 2:3.1 3:5.1 4:2.3
3 1:5.8 2:2.7 3:5.1 4:1.9
3 1:6.8 2:3.2 3:5.9 4:2.3
3 1:6.7 2:3.3 3:5.7 4:2.5
3 1:6.7 2:3.0 3:5.2 4:2.3
3 1:6.3 2:2.5 3:5.0 4:1.9
3 1:6.5 2:3.0 3:5.2 4:2.0
3 1:6.2 2:3.4 3:5.4 4:2.3
3 1:5.9 2:3.0 3:5.1 4:1.8
package com.yyds.tags.ml.clustering
import org.apache.spark.ml.clustering.{KMeans, KMeansModel}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 使用KMeans算法对鸢尾花数据进行聚类操作
*/
object IrisClusterTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
.config("spark.sql.shuffle.partitions", "2")
.getOrCreate()
import org.apache.spark.sql.functions._
import spark.implicits._
// 1. 读取鸢尾花数据集
val irisDF: DataFrame = spark.read
.format("libsvm")
.load("datas/iris/iris_kmeans.txt")
irisDF.printSchema()
irisDF.show(10, truncate = false)
}
}
root
|-- label: double (nullable = true)
|-- features: vector (nullable = true)
+-----+-------------------------------+
|label|features |
+-----+-------------------------------+
|1.0 |(4,[0,1,2,3],[5.1,3.5,1.4,0.2])|
|1.0 |(4,[0,1,2,3],[4.9,3.0,1.4,0.2])|
|1.0 |(4,[0,1,2,3],[4.7,3.2,1.3,0.2])|
|1.0 |(4,[0,1,2,3],[4.6,3.1,1.5,0.2])|
|1.0 |(4,[0,1,2,3],[5.0,3.6,1.4,0.2])|
|1.0 |(4,[0,1,2,3],[5.4,3.9,1.7,0.4])|
|1.0 |(4,[0,1,2,3],[4.6,3.4,1.4,0.3])|
|1.0 |(4,[0,1,2,3],[5.0,3.4,1.5,0.2])|
|1.0 |(4,[0,1,2,3],[4.4,2.9,1.4,0.2])|
|1.0 |(4,[0,1,2,3],[4.9,3.1,1.5,0.1])|
+-----+-------------------------------+
only showing top 10 rows
2.2 模型训练
// 2. 构建KMeans算法
val kmeans: KMeans = new KMeans()
// 设置输入特征列名称和输出列的名名称
.setFeaturesCol("features")
.setPredictionCol("prediction")
// 设置K值为3
.setK(3)
// 设置最大的迭代次数
.setMaxIter(20)
// 3. 应用数据集训练模型, 获取转换器
val kMeansModel: KMeansModel = kmeans.fit(irisDF)
// 获取聚类的簇中心点
kMeansModel.clusterCenters.foreach(println)
[5.88360655737705,2.7409836065573776,4.388524590163936,1.4344262295081969]
[5.005999999999999,3.4180000000000006,1.4640000000000002,0.2439999999999999]
[6.853846153846153,3.0769230769230766,5.715384615384615,2.053846153846153]
2.3 模型评估和预测
// 4. 模型评估
val wssse: Double = kMeansModel.computeCost(irisDF)
println(s"WSSSE = ${wssse}")
// 5. 使用模型预测
val predictionDF: DataFrame = kMeansModel.transform(irisDF)
predictionDF.show(10, truncate = false)
// 应用结束,关闭资源
spark.stop()
+-----+-------------------------------+----------+
|label|features |prediction|
+-----+-------------------------------+----------+
|1.0 |(4,[0,1,2,3],[5.1,3.5,1.4,0.2])|1 |
|1.0 |(4,[0,1,2,3],[4.9,3.0,1.4,0.2])|1 |
|1.0 |(4,[0,1,2,3],[4.7,3.2,1.3,0.2])|1 |
|1.0 |(4,[0,1,2,3],[4.6,3.1,1.5,0.2])|1 |
|1.0 |(4,[0,1,2,3],[5.0,3.6,1.4,0.2])|1 |
|1.0 |(4,[0,1,2,3],[5.4,3.9,1.7,0.4])|1 |
|1.0 |(4,[0,1,2,3],[4.6,3.4,1.4,0.3])|1 |
|1.0 |(4,[0,1,2,3],[5.0,3.4,1.5,0.2])|1 |
|1.0 |(4,[0,1,2,3],[4.4,2.9,1.4,0.2])|1 |
|1.0 |(4,[0,1,2,3],[4.9,3.1,1.5,0.1])|1 |
+-----+-------------------------------+----------+
3 Spark MLlib中决策树入门案例
决策树学习采用的是 自顶向下 的递归方法 ,其基本思想是以信息熵为度量构造一颗熵值下降最快的树,到叶子节点处,熵值为0。其具有可读性、分类速度快的优点,是一种有监督学习。
最早提及决策树思想的是Quinlan在1986年提出的ID3算法和1993年提出的C4.5算法,以及Breiman等人在1984年提出的CART算法。
决策树算法是机器学习算法中非常重要的算法之一,既可以分类又可以回归,其中还可以构建出集成学习算法。
由于决策树分类模型 DecisionTreeClassificationModel 属于概率分类模型ProbabilisticClassificationModel ,所以构建模型时要求数据集中标签label必须从0开始。
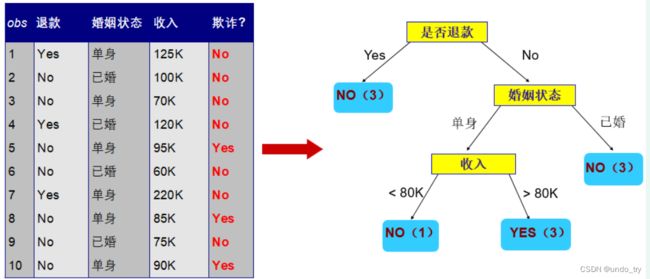
上述数据集中特征:退款和婚姻状态,都是类别类型特征,需要将其转换为数值特征,数值从0开始计算。
针对 特征:退款 来说,将其转换为【0,1】两个值,不能是【1,2】数值。
3.1 读取数据
package com.yyds.tags.ml.classification
import org.apache.spark.ml.classification.{DecisionTreeClassificationModel, DecisionTreeClassifier}
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{StringIndexer, StringIndexerModel, VectorIndexer, VectorIndexerModel}
import org.apache.spark.sql.{DataFrame, SparkSession}
object DecisionTreeTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[4]")
.getOrCreate()
import org.apache.spark.sql.functions._
import spark.implicits._
// 1. 加载数据
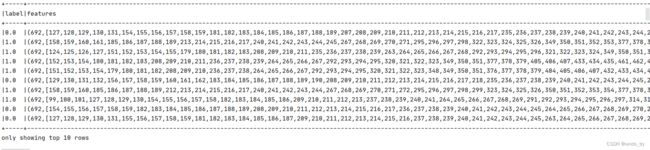
val dataframe: DataFrame = spark.read
.format("libsvm")
.load("datas/iris/sample_libsvm_data.txt")
dataframe.printSchema()
dataframe.show(10, truncate = false)
spark.stop()
}
}
3.2 特征工程
// 2. 特征工程:特征提取、特征转换及特征选择
// a. 将标签值label,转换为索引,从0开始,到 K-1
val labelIndexer: StringIndexerModel = new StringIndexer()
.setInputCol("label")
.setOutputCol("index_label")
.fit(dataframe)
val df1: DataFrame = labelIndexer.transform(dataframe)
// b. 对类别特征数据进行特殊处理, 当每列的值的个数小于设置K,那么此列数据被当做类别特征,自动进行索引转换
val featureIndexer: VectorIndexerModel = new VectorIndexer()
.setInputCol("features")
.setOutputCol("index_features")
.setMaxCategories(4)
.fit(df1)
val df2: DataFrame = featureIndexer.transform(df1)
df2.printSchema()
df2.show(10, truncate = false)
root
|-- label: double (nullable = true)
|-- features: vector (nullable = true)
|-- index_label: double (nullable = true)
|-- index_features: vector (nullable = true)
3.3 训练模型
// 3. 划分数据集:训练数据和测试数据
val Array(trainingDF, testingDF) = df2.randomSplit(Array(0.8, 0.2))
// 4. 使用决策树算法构建分类模型
val dtc: DecisionTreeClassifier = new DecisionTreeClassifier()
.setLabelCol("index_label")
.setFeaturesCol("index_features")
// 设置决策树算法相关超参数
.setMaxDepth(5)
.setMaxBins(32) // 此值必须大于等于类别特征类别个数
.setImpurity("gini") // 也可以是香农熵:entropy
val dtcModel: DecisionTreeClassificationModel = dtc.fit(trainingDF)
println(dtcModel.toDebugString)
DecisionTreeClassificationModel (uid=dtc_338073100075) of depth 1 with 3 nodes
If (feature 406 <= 72.0)
Predict: 1.0
Else (feature 406 > 72.0)
Predict: 0.0
3.4 模型评估
// 5. 模型评估,计算准确度
val predictionDF: DataFrame = dtcModel.transform(testingDF)
predictionDF.printSchema()
predictionDF
.select($"label", $"index_label", $"probability", $"prediction")
.show(10, truncate = false)
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("index_label")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy: Double = evaluator.evaluate(predictionDF)
println(s"Accuracy = $accuracy")
Accuracy = 0.8823529411764706
4、ML Pipeline
管道 Pipeline 概念:将多个Transformer转换器和Estimators模型学习器按照 依赖顺序 组工作流WorkFlow形式,方面数据集的特征转换和模型训练及预测。
将上面的决策树分类代码,改为使用 Pipeline 构建模型与预测。

package com.yyds.tags.ml.classification
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.{DecisionTreeClassificationModel, DecisionTreeClassifier}
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{StringIndexer, StringIndexerModel, VectorIndexer, VectorIndexerModel}
import org.apache.spark.sql.{DataFrame, SparkSession}
object PipelineTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[4]")
.getOrCreate()
import org.apache.spark.sql.functions._
import spark.implicits._
// 1. 加载数据
val dataframe: DataFrame = spark.read
.format("libsvm")
.load("datas/iris/sample_libsvm_data.txt")
//dataframe.printSchema()
//dataframe.show(10, truncate = false)
// 划分数据集:训练集和测试集
val Array(trainingDF, testingDF) = dataframe.randomSplit(Array(0.8, 0.2))
// 2. 构建管道Pipeline
// a. 将标签值label,转换为索引,从0开始,到 K-1
val labelIndexer = new StringIndexer()
.setInputCol("label")
.setOutputCol("index_label")
.fit(dataframe)
// b. 对类别特征数据进行特殊处理, 当每列的值的个数小于设置K,那么此列数据被当做类别特征,自动进行索引转换
val featureIndexer = new VectorIndexer()
.setInputCol("features")
.setOutputCol("index_features")
.setMaxCategories(4)
.fit(dataframe)
// c. 使用决策树算法构建分类模型
val dtc: DecisionTreeClassifier = new DecisionTreeClassifier()
.setLabelCol("index_label")
.setFeaturesCol("index_features")
// 设置决策树算法相关超参数
.setMaxDepth(5)
.setMaxBins(32) // 此值必须大于等于类别特征类别个数
.setImpurity("gini")
// d. 创建Pipeline,设置Stage(转换器和模型学习器)
val pipeline: Pipeline = new Pipeline().setStages(
Array(labelIndexer, featureIndexer, dtc)
)
// 3. 训练模型
val pipelineModel: PipelineModel = pipeline.fit(trainingDF)
// 获取决策树分类模型
val dtcModel: DecisionTreeClassificationModel =
pipelineModel.stages(2)
.asInstanceOf[DecisionTreeClassificationModel]
println(dtcModel.toDebugString)
// 4. 模型评估
val predictionDF: DataFrame = pipelineModel.transform(testingDF)
predictionDF.printSchema()
predictionDF
.select($"label", $"index_label", $"probability", $"prediction")
.show(20, truncate = false)
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("index_label")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy: Double = evaluator.evaluate(predictionDF)
println(s"Accuracy = $accuracy")
// 应用结束,关闭资源
spark.stop()
}
}
5、模型调优
使用决策树算法训练模型时,可以调整相关超参数,结合训练验证(Train-Validation Split)或交叉验证(Cross-Validation),获取最佳模型。
5.1 训练验证
将数据集划分为两个部分 ,静态的划分,一个用于训练模型,一个用于验证模型
通过评估指标,获取最佳模型,超参数设置比较好。

// 无论使用何种验证方式通过调整算法超参数来进行模型调优,需要使用工具类ParamGridBuilder 将 超参数封装到Map集合中
import org.apache.spark.ml.tuning.ParamGridBuilder
val paramGrid: Array[ParamMap] = new ParamGridBuilder()
.addGrid(lr.regParam, Array(0.1, 0.01))
.addGrid(lr.elasticNetParam, Array(0.0, 0.5, 1.0))
.build()
// 使用训练验证 TrainValidationSplit 方式获取最佳模型
val trainValidationSplit = new TrainValidationSplit()
.setEstimator(lr) // 也可以是pipeline
.setEvaluator(new RegressionEvaluator) // 评估器
.setEstimatorParamMaps(paramGrid) // 超参数
// 80% of the data will be used for training and the remaining 20% for validation.
.setTrainRatio(0.8)
训练验证的使用
package com.yyds.tags.ml.classification
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.{DecisionTreeClassificationModel, DecisionTreeClassifier}
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{VectorAssembler, VectorIndexer}
import org.apache.spark.ml.param.ParamMap
import org.apache.spark.ml.tuning.{ParamGridBuilder, TrainValidationSplit, TrainValidationSplitModel}
import org.apache.spark.sql.{DataFrame, SparkSession}
object HPO {
/**
* 调整算法超参数,找出最优模型
* @param dataframe 数据集
* @return
*/
def trainBestModel(dataframe: DataFrame): PipelineModel = {
// a. 特征向量化
val assembler: VectorAssembler = new VectorAssembler()
.setInputCols(Array("color", "product"))
.setOutputCol("raw_features")
// b. 类别特征进行索引
val indexer: VectorIndexer = new VectorIndexer()
.setInputCol("raw_features")
.setOutputCol("features")
.setMaxCategories(30)
// .fit(dataframe)
// c. 构建决策树分类器
val dtc: DecisionTreeClassifier = new DecisionTreeClassifier()
.setFeaturesCol("features")
.setLabelCol("label")
.setPredictionCol("prediction")
// d. 构建Pipeline管道流实例对象
val pipeline: Pipeline = new Pipeline().setStages(
Array(assembler, indexer, dtc)
)
// e. 构建参数网格,设置超参数的值
val paramGrid: Array[ParamMap] = new ParamGridBuilder()
.addGrid(dtc.maxDepth, Array(5, 10))
.addGrid(dtc.impurity, Array("gini", "entropy"))
.addGrid(dtc.maxBins, Array(32, 64))
.build()
// f. 多分类评估器
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
// 指标名称,支持:f1、weightedPrecision、weightedRecall、accuracy
.setMetricName("accuracy")
// g. 训练验证
val trainValidationSplit = new TrainValidationSplit()
.setEstimator(pipeline)
.setEvaluator(evaluator)
.setEstimatorParamMaps(paramGrid)
// 80% of the data will be used for training and the remaining 20% for validation.
.setTrainRatio(0.8)
// h. 训练模型
val model: TrainValidationSplitModel =
trainValidationSplit.fit(dataframe)
// i. 获取最佳模型返回
model.bestModel.asInstanceOf[PipelineModel]
}
}
5.2 交叉验证(K折)
将数据集划分为两个部分 ,动态的划分为K个部分数据集,其中1份数据集为验证数据集,其他K-1分数据为训练数据集,调整参数训练模型。

/**
* 采用K-Fold交叉验证方式,调整超参数获取最佳PipelineModel模型
* @param dataframe 数据集
* @return
*/
def trainBestPipelineModel(dataframe: DataFrame): PipelineModel = {
// a. 特征向量化
val assembler: VectorAssembler = new VectorAssembler()
.setInputCols(Array("color", "product"))
.setOutputCol("raw_features")
// b. 类别特征进行索引
val indexer: VectorIndexer = new VectorIndexer()
.setInputCol("raw_features")
.setOutputCol("features")
.setMaxCategories(30)
// .fit(dataframe)
// c. 构建决策树分类器
val dtc: DecisionTreeClassifier = new DecisionTreeClassifier()
.setFeaturesCol("features")
.setLabelCol("label")
.setPredictionCol("prediction")
// d. 构建Pipeline管道流实例对象
val pipeline: Pipeline = new Pipeline().setStages(
Array(assembler, indexer, dtc)
)
// e. 构建参数网格,设置超参数的值
val paramGrid: Array[ParamMap] = new ParamGridBuilder()
.addGrid(dtc.maxDepth, Array(5, 10))
.addGrid(dtc.impurity, Array("gini", "entropy"))
.addGrid(dtc.maxBins, Array(32, 64))
.build()
// f. 多分类评估器
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
// 指标名称,支持:f1、weightedPrecision、weightedRecall、accuracy
.setMetricName("accuracy")
// g. 构建交叉验证实例对象
val crossValidator: CrossValidator = new CrossValidator()
.setEstimator(pipeline)
.setEvaluator(evaluator)
.setEstimatorParamMaps(paramGrid)
.setNumFolds(3)
// h. 训练模式
val crossValidatorModel: CrossValidatorModel = crossValidator.fit(dataframe)
// i. 获取最佳模型
val pipelineModel: PipelineModel = crossValidatorModel.bestModel.asInstanceOf[PipelineModel]
// j. 返回模型
pipelineModel
}