从混沌到秩序的蜕变,SRE解码云计算运维奥秘
什么是SRE
SRE(Site Reliability Engineering)即站点可靠性工程,最初由Google公司提出,通过将开发、运维等多方面进行整合,协同推进系统可靠性,从而确保业务服务能够持久运行。
这是一种新的模式,与传统的运维相比,更加强调服务于目标的多维因素整合,通过开发自动化、智能化工具、实时监测等手段,从根本上解决系统稳定性和可靠性问题。
为什么需要SRE
数字经济的发展日新月异,云计算已经成为企转数改的重要支撑和推动力量。云计算的优势无须多讲,随之而至的管理问题亦令人酸爽,本文以云计算平台管理为目标进展案例性分析。
-
环境复杂:从云主机、存储、数据库、中间件等主要类型向大数据、人工智能、容器、超算、智算等服务及云原生类产品衍生;其分散多样性以及规模都在不断增长。
-
可靠性要求高:作为应用系统的基础设施,承载了大量的业务;运维的目标就是保障业务安全运行的连续性,杜绝系统崩溃或者服务不可用。
-
维护成本高:不断演进的不仅仅是应用,各种云平台版本和服务类型也需要相应提升。运维团队及系统的知识、能力和经验需要快速更迭,才能满足运维目标要求。
-
运维协同难:平台服务日益复杂的应用环境,支撑工作日益繁杂的知识领域,运维团队日益壮大,运维协同日趋艰难。
SRE的核心原则
《SRE Google运维解密》一书中给出了SRE的经典核心原则,就不再赘述,本文以其为基础,抽象了几个核心关键点。
-
可靠性:可靠性应该被赋予与安全等同的重要性,对于每一个服务的设计都是以可靠性为首要目标。
-
自动化:通过自动化工具和流程来替代手动操作,提高效率和准确性,降低人为错误和重复性工作的发生。
-
监控和告警:对系统进行全面、实时的监控,通过监测关键指标辅助SRE团队快速发现问题,降低故障的影响。
-
故障演练和容量规划:通过分析历史数据,预测系统的资源需求,并进行容量规划;避免系统出现资源瓶颈。
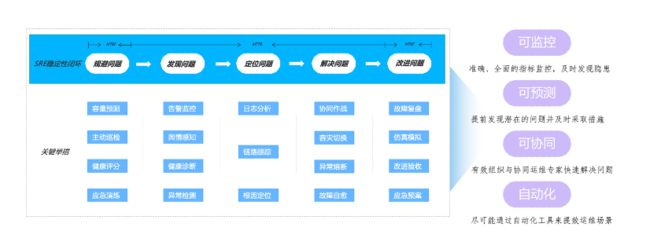
借鉴行业优秀实践,并结合云计算业务场景与特性,可以进一步提炼为以下4个核心原则,来组织日常运维工作。
-
可监控:通过采集业务指标、日志、性能、告警等数据,快速分析与定位问题;准确识别故障,并及时采取措施解决问题。
-
可预测:通过故障预测来提高系统的可靠性和稳定性。预测故障可以帮助SRE团队比较早的了解到潜在的问题并及时采取措施。SRE通常会通过数据分析、模拟测试来预测故障。
-
可协同:将运维操作手册化、流程化,以便确保运维作业的一致性;提供线上协同工具,当出现问题时能够快速召集运维专家协同处理问题。
-
自动化:自动化是SRE方法论的核心,SRE强调尽可能的自动化来提高服务可靠性和生产率。自动化可以减少人为错误,提高一致性和重复性,并释放人力资源进行更有价值的工作。
SRE的核心原则不仅是构建高可靠性、可扩展性和弹性的系统关键能力要素,也是塑造运维工作方式的重要基础。通过遵循SRE的核心原则,能够快速发现、定位、响应和协同处理问题,同时也能够主动预防性维护和持续优化,提升系统的运行质量和稳定性。
基于SRE的工具链实践
SRE 的方法固然重要,但没有强有力的工具链来作为支撑,在执行面将面临步步维艰,因此,建设一套适合自身业务服务场景的SRE工具链,是让SRE实践得以高效运转的关键。
本文基于SRE 的核心原则,即在“事前”发现潜在问题,“事中”快速定位、处理问题,“事后”持续优化来规避问题。通过实时监控和分析数据,并采用自动化工具套件来减少手动操作,从而缩短故障处理时间,排除潜在故障点,并持续优化服务稳定性。
01 发现问题:准确、实时、全面的运行监测
在云计算环境中,算力服务的运行监控至关重要。开发/运维人员时常面临以下典型的问题:
-
监控指标无体系,监控指标覆盖不全,可配置化程度低。
-
告警风暴导致预警混乱,分不清需要处理的预警,甚至忽视重要预警。
-
告警被动响应,无法及时、可信地推送关键告警和故障信息,导致故障处理不及时。
-
预警能力弱,无法提前对潜在的风险或异常行为进行识别和报警。
SRE稳定性治理很重要的一部分就是预警治理,通过监控分层、统一预警配置、统一预警优化配置策略等措施来实现主动预警。从规则驱动向内生智能驱动转变,提升监控准确性,及时发现隐患。
指标有体系
建立一套全面覆盖的运维指标体系,通过指标分级的方式,提供丰富的业务监控指标,保障能够及时的发现问题。
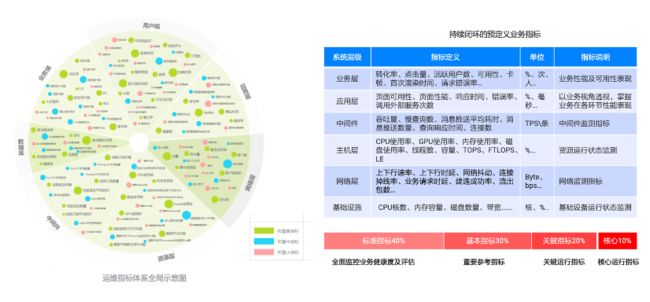
根据对大量指标的分析,定义一套全面覆盖的指标度量体系。并根据指标的权重、关系以及对应运维人员的权责进行划定。设计指标时采取场景分类的方法:
-
脱管、中断类,定义为核心指标;如设备或者云服务宕机、网络不可达等。就是关键业务及服务指标异常代表业务不可用。通过抓主要矛盾的方法,关注核心路由器、IDC出口、资源池出入口等。
-
资源过载类,定义为关键指标;关键指标代表业务运行状态的健康度,如受到网络攻击,对应的网络流量、资源会发生指标的变化、产生告警,通过这类指标快速发现问题。
-
运行质量类,定义为重要指标;重要指标代表业务运行质量状态,如端口抖动、时延造成业务质量不达标等,关注事件的关联及变化。
信息有关联
告警的内容过于简单,会让处理告警的过程变成一个猜迷游戏,往往需要运维人员重新通过多种手段验证与推测后,才能确定问题所在。这也是处理告警耗时最多的地方。
-
影响资源:单机、集群、资源池、相关依赖;
-
影响业务:核心业务、旁路业务、非核心业;
-
关联trace:给出预警问题的一条trace链路,相当于把现场还原;
-
关联日志:详细的错误日志link能定位到具体代码和当时的堆栈信息;
-
关联告警:关联的预警信息,方便快速判断是否由其它关联问题引起;
-
异常检测:通过从推理速度、准确性和参数调整的变异性等多个维度验证,Matrix Profile算法能够极大的提高告警的准确度;
-
智能基线:兼顾多个指标波动变化,预测动态安全区间,准确发现异常。
核心上大屏
从底层物理机到云主机、到中间件、到客户业务的全链路端到端打通。实现业务指标全景监测,确保重大事件及时发现。

-
通信保障屏,对各类重要保障、风险操作、云主机接入操作、IDC机房入场事件进行过程追踪发现隐患,提供及时预警手段。
-
指挥调度屏,当发生重大故障、应急事件时,指挥调度屏可以一键发起联合作战。
-
态势感知屏,对资源池运行质量进行数据分析,提前预测趋势避免故障发生。
-
舆情屏,快速识别火灾、交通事故、自然灾害等热点事件对资源池、业务、客户的影响度,跟踪隐患和提前预案处理。
-
核心指标屏,核心业务监测指标上屏,发现突发事件、重大故障、网络攻击、宕机、运维人员非法操作时;能够快速的通过大屏做出声光电告警。
02 定位问题:智能诊断与根因分析
SRE倡导通过预测来提高系统的可靠性和稳定性。预警诊断就是把运维专家脑海中的经验转化成规则+多种数据间的潜在关联性,通过一些智能化的分析手段变成结果输出。
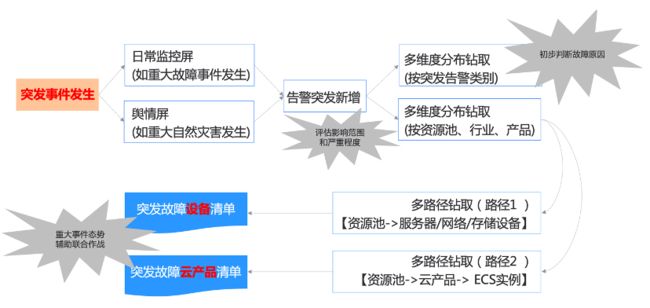
1) 多维度数据分布钻取,辅助问题定位
将整个全链路的监控数据进行汇聚并统一呈现,出问题时能够及时发现;同时通过多维度数据分布钻取,还能辅助问题定位。
2) 基于专家经验构建因果图,结合算法根因推断
结合专家经验和算法模型,通过构建因果图实现根因分析,从而识别故障的根本原因。以ECS为例,实例与云服务器的网络配置、端口通信、防火墙配置、安全组配置等多个环节相关联。任意一个环节出现问题,都会导致ECS运行实例无法访问。
ECS访问异常关联因素及可能导致的症状;从客户端到服务端的整个链路上,可能引发访问异常的关联因素如下:
收集其专家经验和知识,建立因果图。这些因果关系可能是定性的或定量的,以及直接或间接的。ECS相关联因素可能导致的症状如下:
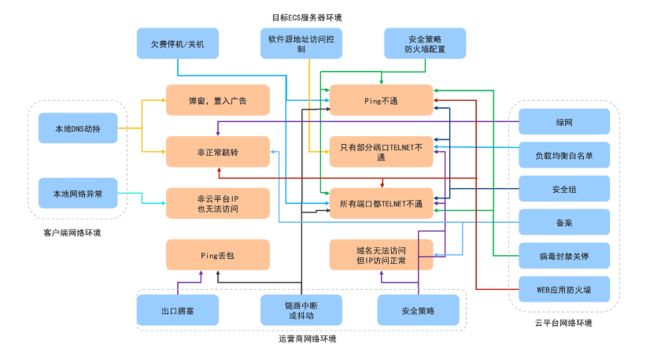
目标ECS服务器内部环境可能因目标服务器欠费停机、CPU利用率过高、目标服务器内部配置等因素导致访问异常。对于ECS访问异常问题,建立故障因果排查图:
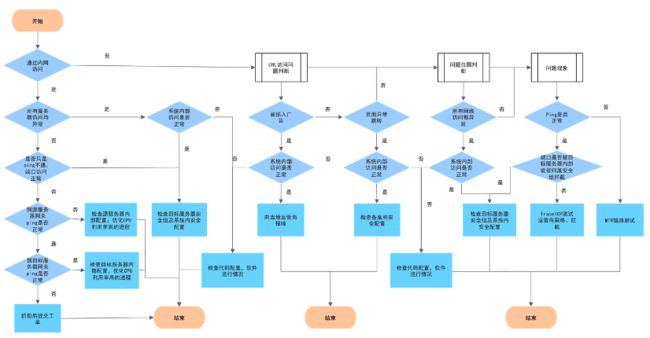
从异常点出发,综合时间序列相关性分析、剪技操作,并结合故障排查图的因果推断等算法,输出根因分析topr排序结果。
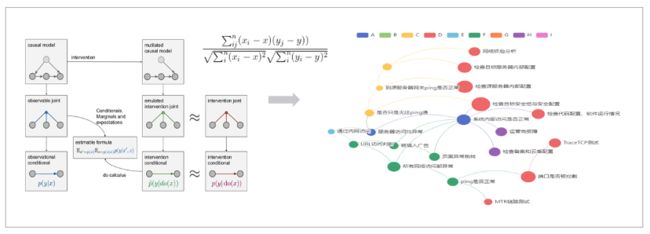
根据异常排障因果图,并结合算法模型以及专家经验和实际数据,逐步深入推断和识别问题的根本原因。需要注意的是,该过程中需要对算法模型和异常变量进行精细调整,以提高根本原因诊断的准确性和有效性。
03 解决问题:高效协同
当面对重大故障、风险操作、应急事件时,SRE团队是否能快速协作处理问题是至关重要的。传统的处理方法是召开网络会议,拉取相关专家人员参与讨论和解决问题。但这种方式存在很多弊端,如任务调度不清晰、无法进行实时跟踪和反馈、操作步骤难以留存等等,这些将会影响处理问题的效率。
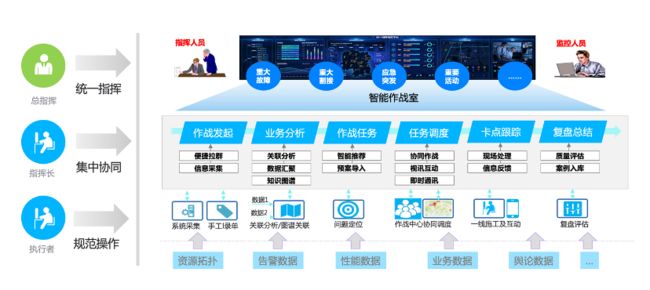
协同作战的主要思路是将底层数据汇总,通过指挥调度快速解决问题,同时利用投屏可视化和机器人入驻作战室提醒等方式提高执行效率。
04 规避问题:风险控制
扁鹊见蔡桓公的故事家喻户晓,名医扁鹊的高超医术让我们惊叹。然而,从运维的角度思考这个故事,会发现提前预防,总比治疗好!最好的措施不是在你生病后采取治疗行动,而是在你身体健康的时候、根据你的日常生活习惯和体貌特征、体验报告,帮你未病先防,保护你免受病痛困扰。
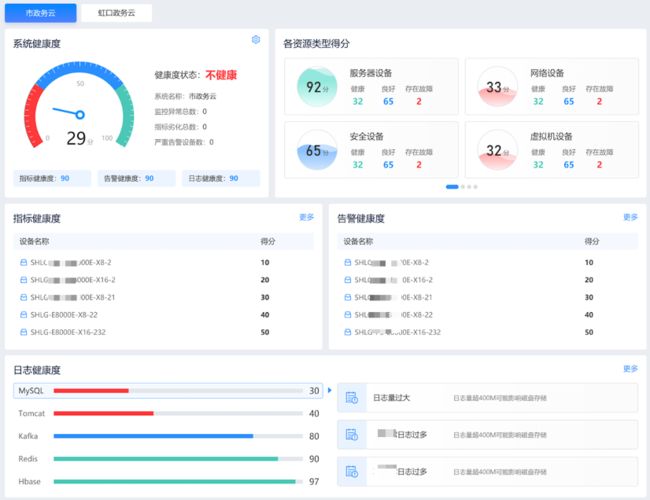
健康检查项

评估规则与算法
-
健康度指标评分计算
初始根据提供的指标评分模型,每天定时计算当天的均值、峰值和标准差,进行分数测算。
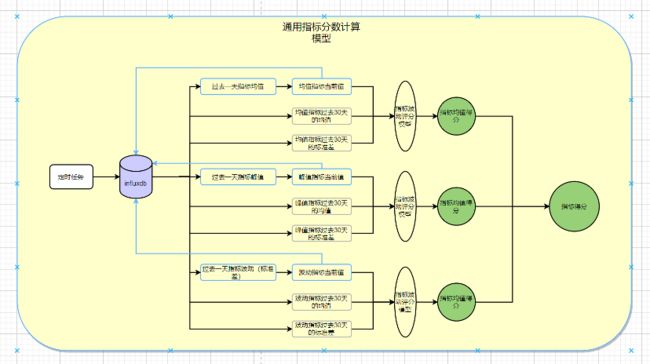
-
健康度日志评分计算
通过定时任务每天收集日志,提取日志文件大小,日志数量,异常日志大小,异常日志数量指标,并通过设定预设的阈值来计算得分;同时,会对异常日志进行采样,并进行聚类分析,收集聚类结果。

除了设定阈值计算得分之外,还可以对指标进行多维度分析,如均值、峰值、标准差(波动性)等,以挖掘更多异常情况。对于每个指标,系统会使用相应的算法计算得分,异常的概率越大得分越低。
健康度告警评分计算
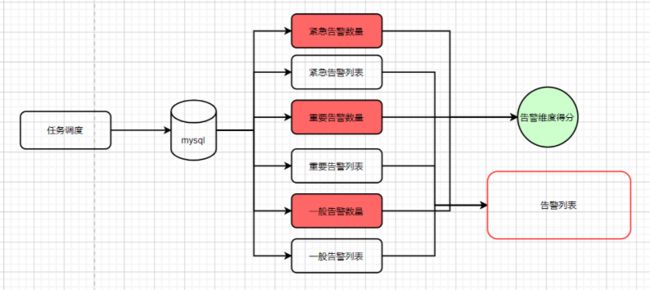
定期收集设备的存量告警,对于每个设备的告警,会根据告警等级和数量进行扣分,并根据设备告警维度得分计算规则进行计算。配置设备的告警维度得分计算规则可以设置不同告警等级的权重值、数量阈值等参数,从而得出每个设备告警得分。
![]()
-
健康度视图与呈现
提供健康度监测、性能监测、健康报告,通过展示各类资源的得分情况,帮助用户全面了解运行状况和健康情况。