【期末专题】数据库知识点整理
1.要求:修改表的“价格”列,使其数据类型为decimal(6,2)
语句:alter table BookInfo modify price decimal(6,2);
注意点:修改一个表中已有列的数据类型的语句格式:
alter table <表名> modify <列名> <数据类型>
2.要求:
#创建触发器,修改学生成绩时,如果成绩不在0-100之间,不改变原成绩(即本次成绩修改无效)。
1、student(学生表):
SNO学号CHAR(7)
SNAME姓名CHAR(10)
SSEX性别CHAR(2)
SAGE年龄SMALLINT
SDEPT所在系 VARCHAR(20)
2、course(课程表)
CNO课程号CHAR(10)
CNAME课程名VARCHAR(20)
CCREDIT学分SMALLINT
SEMSTER学期SMALLINT
PERIOD学时SMALLINT
3、sc(选课表)
SNO 学号CHAR(7)
CNO 课程号CHAR(10)
GRADE 成绩 SMALLINT
[注意:SQL表名请用小写]语句:
delimiter $$
create trigger tri_grade
before update
on sc
for each row
begin
if NEW.grade<0 or NEW.grade>100 then
set NEW.grade=OLD.grade;
end if;
end$$
delimiter;注意点:
创建触发器的语法:
create trigger 触发器名
before | after
insert | delete | update
on 表名
for each row
<触发器名>
程序中变量的使用:
1)声明变量
在存储程序(如存储函数、存储过程、触发器等)中需要使用DECLARE声明局部变量,语法如下:
declare 局部变量名[,局部变量名,......] 数据类型 [default 默认值]
注意:DECLARE声明的局部变量,变量名前不能加@
DEFAULT子句提供了一个默认值,如果没有给默认值,初始默认为NULL
2)为变量赋值
使用SET命令为变量赋值:
SET 局部变量名=表达式1[,局部变量名=表达式2,……]
3.要求:
定义一个函数f_getstar,任意输入一个date型,返回对应的星座名
注意:1、函数名必须为规定的名称f_getstar
2、返回的星座名称必须跟下面的名称完全一样(3个字)
星座名 日期(公历)
摩羯座 (12/22 - 01/19)
水瓶座 (01/20 - 02/18)
双鱼座 (02/19 - 03/20)
牡羊座 (03/21 - 04/20)
金牛座 (04/21 - 05/20)
双子座 (05/21 - 06/21)
巨蟹座 (06/22 - 07/22)
狮子座 (07/23 - 08/22)
处女座 (08/23 - 09/22)
天秤座 (09/23 - 10/22)
天蝎座 (10/23 - 11/21)
射手座 (11/22 - 12/21)
语句:
delimiter $$
create function f_getstar(b date)
returns varchar(20)
begin
return
(case
when month(b)=1 and day(b)>20 or month(b)=2 and day(b)<=18 then "水瓶座"
when month(b)=2 and day(b)>18 or month(b)=3 and day(b)<=20 then "双鱼座"
when month(b)=3 and day(b)>20 or month(b)=4 and day(b)<=20 then "牡羊座"
when month(b)=4 and day(b)>20 or month(b)=5 and day(b)<=20 then "金牛座"
when month(b)=5 and day(b)>20 or month(b)=6 and day(b)<=21 then "双子座"
when month(b)=6 and day(b)>21 or month(b)=7 and day(b)<=22 then "巨蟹座"
when month(b)=7 and day(b)>22 or month(b)=8 and day(b)<=22 then "狮子座"
when month(b)=8 and day(b)>22 or month(b)=9 and day(b)<=22 then "处女座"
when month(b)=9 and day(b)>22 or month(b)=10 and day(b)<=22 then "天秤座"
when month(b)=10 and day(b)>22 or month(b)=11 and day(b)<=21 then "天蝎座"
when month(b)=11 and day(b)>21 or month(b)=12 and day(b)<=21 then "射手座"
else "摩羯座"
end);
end$$
注意点:
①创建函数的语法:
create function 函数名([参数名 参数类型,[...]])
returns 函数返回值的数据类型
begin
函数体;
return 语句;
end
②case语句的语法:
注意case语句每一个条件分支后都没有分号,end后也没有分号
case 表达式
when v1 then r1
when v2 then r2
...
[else rn]
end
case
when 条件1 then sql语句块1
when 条件2 then sql语句块2
……
when 条件n then sql语句块n
else sql语句块n+1
end
③sql里的相等是一个等号,例如: mon(b)=1
4.
要求:
#创建视图 V_userDeviceList ,返回用户设备统计信息,结果形式要求如下。
第一列 用户姓名
第二列 用户设备数量
要求统计所有用户设备数量,如果用户没有任何设备,第二列值显示零(可以使用函数 ifnull(expr1, expr2) )。
/*参考语法*/
CREATE VIEW V_userDeviceList(姓名, 设备数)
AS
。。。。。。
#相关表结构
/* 装备类别 */
CREATE TABLE devicveType(
ID INT PRIMARY KEY comment '类别编号',
name NCHAR(50) NOT NULL comment '类别名'
);
/* 用户 */
CREATE TABLE user(
ID INT PRIMARY KEY comment '用户账号',
name NCHAR(50) NOT NULL comment '用户名称',
coins int comment '游戏币余额'
);
/* 装备 */
CREATE TABLE device(
ID INT PRIMARY KEY comment '装备编号',
desc_deveice NCHAR(200) NOT NULL comment '装备描述',
IDofdevicveType int comment '类别编号',
price int comment '价格'
);
/* 用户装备关系表 */
CREATE TABLE user_device(
IDofuser INT comment '用户编码',
IDofdevice INT comment '装备编码',
qty smallint default 1 comment '用户拥有该装备的数量',
primary key (IDofuser, IDofdevice)
);
#相关测试数据
insert into devicveType values( 105, '主武器');
insert into devicveType values( 260, '治愈力');
insert into devicveType values( 1457, '防护武器');
insert into user values( 1998, 'ADa', 60 );
insert into user values( 1999, 'batman', 30 );
insert into user values( 2001, 'Fa– Mulan', 500 );
insert into device values(587, '血滴子, 可提高体力', 260, 10);
insert into device values(254, '制式大刀, 普通材质', 105, 5);
insert into device values(3895, '光甲,稀有,神级材质', 1457, 5);
insert into user_device values(1998, 587, 10 );
insert into user_device values(1998, 254, 1 );
insert into user_device values(2001, 254, 2 );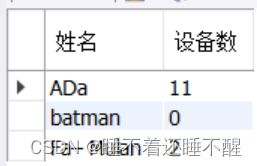
语句:
create view V_userDeviceList
as
select name 姓名, ifnull(sum(qty),0) 设备数
from user left outer join user_device on id=IDofuser
group by id;注意点:
①创建视图:
create [or replace] view 视图名[(别名[,别名])]
as
SELECT 语句
[with check option];
②对设备数求和使用sum()函数
③本题的含义是根据用户id分组,对用户所有的设备数求和
④为了显示所有用户,使用左外连接,防止信息丢失
5.
要求:
#创建存储过程:total_order(IN orderid INT , OUT totals NUMERIC(9,2), OUT cid INT)
要求:根据输入的订单编号(order_id),返回订单总金额(total_money),顾客编号(customer_id)。
订单表:orders如下:
语句:
delimiter $$
create procedure total_order
(
in orderid int,
out totals numeric(9,2),
out cid int
)
begin
select total_money,customer_id into totals,cid
from orders
where order_id=orderid;
end$$
delimiter;注意点:
在查询语句中可以使用into关键字,将查询到的值转换为out输出的值
也可以使用set关键字,总之就是将得到的结果转换为out关键字后的名字
6.
要求:
创建触发器,插入学生成绩时,限制必须在0-100之间。如果准备插入的成绩不在有效范围内,将成绩重设为 0。
1、student(学生表):
SNO学号CHAR(7)
SNAME姓名CHAR(10)
SSEX性别CHAR(2)
SAGE年龄SMALLINT
SDEPT所在系 VARCHAR(20)
2、course(课程表)
CNO课程号CHAR(10)
CNAME课程名VARCHAR(20)
CCREDIT学分SMALLINT
SEMSTER学期SMALLINT
PERIOD学时SMALLINT
3、sc(选课表)
SNO 学号CHAR(7)
CNO 课程号CHAR(10)
GRADE 成绩 SMALLINT
[注意:SQL表名请用小写]语句:
delimiter $$
create trigger insert_grade
before insert
on sc
for each row
begin
if new.grade<0 or new.grade>100 then
set new.grade=0;
end if;
end$$
delimiter ;注意点:题目说的是插入成绩,所以应该是before insert!
7.
要求:
按照salary的累计和running_total,其中running_total为前两个员工的salary累计和,其他以此类推。 具体结果如下Demo展示。。
CREATE TABLE `salaries` ( `emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
输出格式:
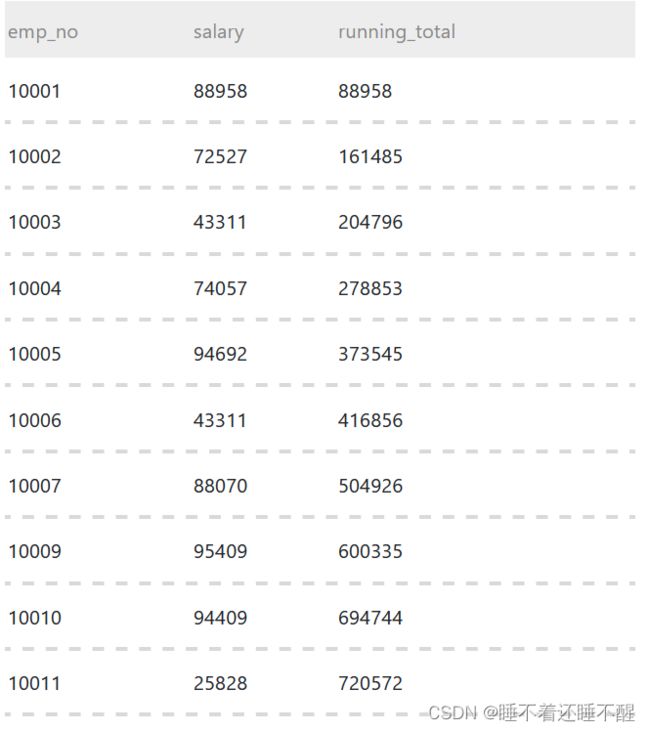
语句:
select emp_no,salary,
(select sum(salary) from salaries as s2 where s2.emp_no<=s1.emp_no and s2.to_date="9999-01-01") as running_total
from salaries as s1
where s1.to_date="9999-01-01"
order by s1.emp_no asc;注意点:
本题的子查询是根据emp_no,只要子查询中的emp_no小于等于主查询中的emp_no,就对salary迭代求和。
8.
要求:
使用含有关键字exists 的SQL 语句查找未分配具体部门的员工的所有信息。
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));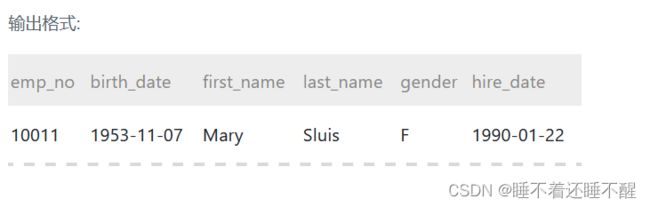
语句:
select * from employees where emp_no not in (select emp_no from dept_emp);注意点:
因为dept_emp中dept_no是主键不能为空,所以查询出dept_emp中的所有emp_no,只要不在其中就是没有具体分配部门的员工。
9.
要求:
查找字符串'10,A,B' 中逗号','出现的次数cnt。
备注:
可以使用MySQL内部函数 length 和 replace
语句:
select length("10,A,B")-length(replace("10,A,B",",","")) as cnt;
注意点:
-- Replace "SQL" with "HTML"
SELECT REPLACE("SQL Tutorial", "SQL", "HTML");10.
要求:
film表
字段 说明
film_id 电影id
title 电影名称
description 电影描述信息
CREATE TABLE IF NOT EXISTS film (
film_id smallint(5) NOT NULL DEFAULT '0',
title varchar(255) NOT NULL,
description text,
PRIMARY KEY (film_id));
category表
字段 说明
category_id 电影分类id
name 电影分类名称
last_update 电影分类最后更新时间
CREATE TABLE category (
category_id tinyint(3) NOT NULL ,
name varchar(25) NOT NULL, `last_update` timestamp,
PRIMARY KEY ( category_id ));
film_category表
字段 说明
film_id 电影id
category_id 电影分类id
last_update 电影id和分类id对应关系的最后更新时间
CREATE TABLE film_category (
film_id smallint(5) NOT NULL,
category_id tinyint(3) NOT NULL, `last_update` timestamp);
查找描述信息中包括robot的电影对应的分类名称以及电影数目,而且还需要该分类对应电影数量>=5部语句:
select c.name,count(f.film_id)
from film f,film_category fc,category c,
(select category_id from film_category group by category_id having count(film_id)>=5) cc
where f.description like "%robot%"
and f.film_id=fc.film_id
and fc.category_id=c.category_id
and c.category_id=cc.category_id;注意点:条件中需要找到描述信息包括robot电影对应的分类名称以及电影数目,而且分类对应电影数量>=5,这两个应该是同等条件而非递进条件。
11.
要求:
汇总各个部门当前员工的title类型的分配数目,结果给出部门编号dept_no、dept_name、其当前员工所有的title以及该类型title对应的数目count
CREATE TABLE `departments` (
`dept_no` char(4) NOT NULL,
`dept_name` varchar(40) NOT NULL,
PRIMARY KEY (`dept_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE IF NOT EXISTS `titles` (
`emp_no` int(11) NOT NULL,
`title` varchar(50) NOT NULL,
`from_date` date NOT NULL,
`to_date` date DEFAULT NULL);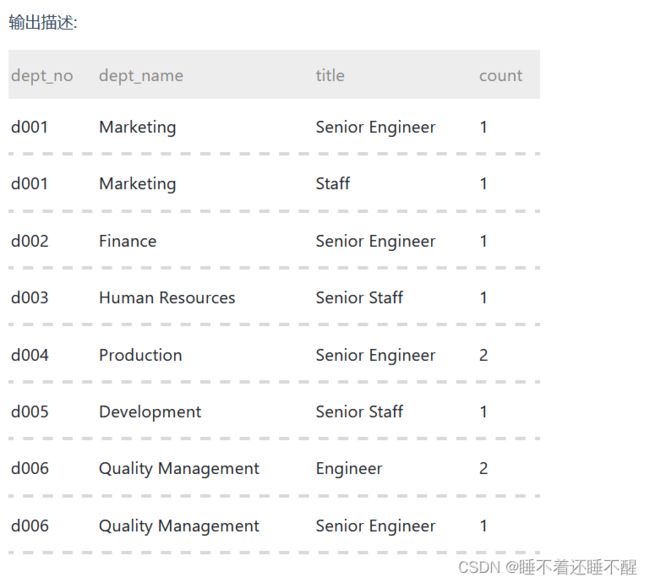
语句:
select d.dept_no,d.dept_name,t.title,count(t.title)
from departments d,dept_emp de,titles t
where d.dept_no=de.dept_no and de.emp_no=t.emp_no and de.to_date='9999-01-01' and t.to_date='9999-01-01'
group by d.dept_no,t.title
order by d.dept_no asc;
注意点:
分组的时候,是“每个部门”“不同的title”,即要先按照部门分组,然后在每个部门内按照不同的title分组。
注意是当前员工、当前title,记得限制to_date为9999-01-01
12.
要求:
获取员工其当前的薪水比其manager当前薪水还高的相关信息,当前表示to_date='9999-01-01',
结果第一列给出员工的emp_no,
第二列给出其manager的manager_no,
第三列给出该员工当前的薪水emp_salary,
第四列给该员工对应的manager当前的薪水manager_salary
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));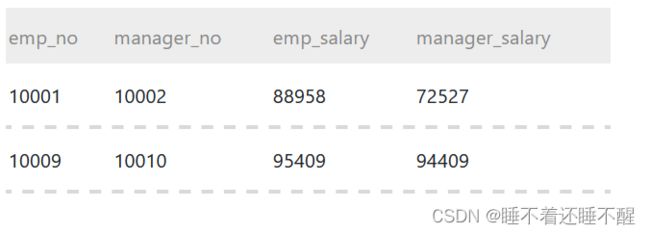
语句:
select es.emp_no as emp_no,ms.emp_no as manager_no,es.salary as emp_salary,ms.salary as manager_salary
from
(
select dept_emp.emp_no,salary,dept_no from salaries,dept_emp where salaries.to_date="9999-01-01" and salaries.emp_no=dept_emp.emp_no
) as es,
(
select dept_manager.emp_no,salary,dept_no from salaries,dept_manager where salaries.to_date="9999-01-01" and salaries.emp_no=dept_manager.emp_no
) as ms
where es.dept_no=ms.dept_no and es.salary>ms.salary;注意点:
尽量不要引入过多的表(比如额外引入dept_emp和dept_manager),而是从两个查询中得到员工的员工编号、部门编号和薪水,以及经理的经理编号、部门编号和薪水,确保薪水对应的员工一致。
13.
要求:
查找排除当前最大、最小salary之后的员工的平均工资avg_salary。
CREATE TABLE `salaries` ( `emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));语句:
select avg(salary)
from salaries
where to_date="9999-01-01"
and salary!=(select max(salary) from salaries)
and salary!=(select min(salary) from salaries);注意点:
复合函数不能嵌套使用,可以在条件部分排除最大和最小的salary
14.
要保证数据库物理数据独立性,需要修改的是:D
A.模式
B.内模式
C.模式和外模式的映射
D.模式与内模式的映射

15.数据库管理系统功能包括下面哪些 :BCD
A.数据挖掘
B.数据操纵
C.安全控制
D.数据结构定义
16.数据库逻辑模型主要包括: BCD
A.结构模型
B.网状模型
C.关系模型
D.层次模型
17.
网上订餐平台系统需求背景:每个加盟店(Shop)可以提供多种食品(Food)销售,每种食品需要归到某个类别(type);每个顾客(Customer)在一个订单(Orders)中只能订购一个加盟店的食品,但可以订购多种食品,每种食品可以订购多个数量,订单需要记录订单时间、商店和总价,另外需要记录食品明细。
触发器:编写1个触发器,在往订单明细表中添加食品时,如果输入的食品跟订单中其它食品不属于一个商店,则取消本次插入。
注意:要考虑到订单中没有食品的特殊情况
/* signal使用语法参考 */
signal sqlstate '45000' set message_text = '错误信息!';
/*触发器创建语法参考(注意增加delimiter语句)*/
delimiter $$
create trigger tr_check_shop before|after insert|delete|update
on 表名
for each row
begin
mysql代码;
end$$
delimiter ;
/****** 以下为表结构及测试数据(可直接粘贴到调试工具使用) ******/
drop database if exists sales;
create database sales;
use sales;
/* 食品类别 */
CREATE TABLE food_type (
tno int NOT NULL COMMENT '类别编号',
tname varchar(50) NOT NULL COMMENT '类别名称',
PRIMARY KEY (tno)
);
/* 顾客 */
CREATE TABLE customer (
cid int NOT NULL COMMENT '顾客ID',
cname varchar(50) NOT NULL COMMENT '用户名',
pwd varchar(32) NOT NULL COMMENT '密码',
cardid varchar(18) NOT NULL COMMENT '身份证号',
PRIMARY KEY (cid)
);
/* 商店 */
CREATE TABLE shop (
sno int NOT NULL COMMENT '商店编号',
sname varchar(50) NOT NULL COMMENT '商店名称',
addr varchar(100) NOT NULL COMMENT '地址',
PRIMARY KEY (sno)
);
/* 食品 */
CREATE TABLE food (
fno int NOT NULL COMMENT '食品编号',
fname varchar(50) NOT NULL COMMENT '食品名称',
price decimal(10,2) NOT NULL COMMENT '食品价格',
stock int NOT NULL COMMENT '库存数量',
sno int NOT NULL COMMENT '商店编号',
tno int NOT NULL COMMENT '食品类别编号',
PRIMARY KEY (fno),
FOREIGN KEY (sno) REFERENCES shop (sno),
FOREIGN KEY (tno) REFERENCES food_type (tno)
);
/* 订单 */
CREATE TABLE orders (
oid int NOT NULL COMMENT '订单编号',
order_time datetime NOT NULL COMMENT '下单时间',
cid int NOT NULL COMMENT '顾客ID',
sno int NOT NULL COMMENT '商店编号',
total_price decimal(10,2) COMMENT '总价',
PRIMARY KEY (oid)
);
/* 订单明细 */
CREATE TABLE order_detail (
id int AUTO_INCREMENT COMMENT '明细编号',
oid int NOT NULL COMMENT '订单编号',
fno int NOT NULL COMMENT '食品编号',
num int NOT NULL COMMENT '数量',
PRIMARY KEY (id)
);
/* 向 food_type 表中插入数据 */
INSERT INTO food_type (tno, tname) VALUES
(1, '川菜'),
(2, '粤菜'),
(3, '湘菜'),
(4, '鲁菜');
/* 向 customer 表中插入数据 */
INSERT INTO customer (cid, cname, pwd, cardid) VALUES
(1, '张三', '123456', '360102199001010015'),
(2, '李四', '654321', '360102199002020016'),
(3, '王五', 'abcdef', '360102199003030017'),
(4, '赵六', 'fedcba', '360102199004040018');
/* 向 shop 表中插入数据 */
INSERT INTO shop (sno, sname, addr) VALUES
(1, '老北京炸酱面', '南昌市洪都大街1号'),
(2, '天下第一小吃', '南昌市井冈山路2号'),
(3, '川渝香锅', '南昌市青山湖区麻坊街55号'),
(4, '东北乡村烧烤', '南昌市红谷滩新区维也纳国际B座');
/* 向 food 表中插入数据 */
INSERT INTO food (fno, fname, price, stock, sno, tno) VALUES
(1, '麻辣火锅', 88.00, 50, 3, 1),
(2, '宫保鸡丁', 38.00, 100, 3, 1),
(3, '回锅肉', 28.00, 120, 3, 1),
(4, '佛跳墙', 888.00, 10, 1, 2),
(5, '清蒸龙虾', 588.00, 8, 1, 2),
(6, '广东煲仔饭', 15.00, 150, 2, 2),
(7, '小资手工奶茶', 18.00, 200, 2, 4),
(8, '重庆辣子鸡', 48.00, 80, 3, 1),
(9, '担担面', 22.00, 150, 3, 1),
(10, '香辣火锅', 33.00, 100, 3, 1),
(11, '大盘鸡', 58.00, 70, 3, 1),
(12, '南瓜粥', 8.00, 200, 2, 4);
/* 向 orders 表中插入数据 */
INSERT INTO orders (oid, order_time, cid, sno) VALUES
(1, NOW(), 1, 1);语句:
delimiter $$
create trigger tr_check_shop
before insert
on order_detail
for each row
begin
declare shop_id int;
select sno into shop_id from orders where oid=NEW.oid;
if (select count(*) from food where fno=NEW.fno and sno!=shop_id)>0 then
signal sqlstate '45000' set message_text = '插入的食品商店不一致';
end if;
end$$
delimiter ;注意点:
触发器:编写1个触发器,在往订单明细表中添加食品时,如果输入的食品跟订单中其它食品不属于一个商店,则取消本次插入。
注意:要考虑到订单中没有食品的特殊情况
要考虑查询商店时是“订单”表
如果能查到一个食物,它是插入的食品且所属商店不等于订单表中查到的商店,则触发signal
考虑了订单中没有食品的特殊情况,因为此时不会大于0
18.
网上订餐平台系统需求背景:每个加盟店(Shop)可以提供多种食品(Food)销售,每种食品需要归到某个类别(type);每个顾客(Customer)在一个订单(Orders)中只能订购一个加盟店的食品,但可以订购多种食品,每种食品可以订购多个数量,订单需要记录订单时间、商店和总价,另外需要记录食品明细。
存储过程:编写1个存储过程add_detail,完成往指定订单中添加食品的业务操作,输入参数包括订单号、食品号、数量。
要求:
1、检查订单号、食品号是否有效
2、检查食品的数量是否在合理范围
3、自动更新对应的食品库存数量
4、自动计算订单总价
【注意】
1、存储过程名必须为add_detail
2、订单表增加订单总价字段total_price,请重新运行下面的测试数据
/*相关语法*/
/*存储过程创建语法参考(注意增加delimiter语句)*/
delimiter $$
Create procedure P_Consume(
参数1 类型,
参数2 类型,
参数3 类型
)
begin
mysql代码;
end$$
delimiter ;
/****** 以下为表结构及测试数据(可直接粘贴到调试工具使用) ******/
drop database if exists sales;
create database sales;
use sales;
/* 食品类别 */
CREATE TABLE food_type (
tno int NOT NULL COMMENT '类别编号',
tname varchar(50) NOT NULL COMMENT '类别名称',
PRIMARY KEY (tno)
);
/* 顾客 */
CREATE TABLE customer (
cid int NOT NULL COMMENT '顾客ID',
cname varchar(50) NOT NULL COMMENT '用户名',
pwd varchar(32) NOT NULL COMMENT '密码',
cardid varchar(18) NOT NULL COMMENT '身份证号',
PRIMARY KEY (cid)
);
/* 商店 */
CREATE TABLE shop (
sno int NOT NULL COMMENT '商店编号',
sname varchar(50) NOT NULL COMMENT '商店名称',
addr varchar(100) NOT NULL COMMENT '地址',
PRIMARY KEY (sno)
);
/* 食品 */
CREATE TABLE food (
fno int NOT NULL COMMENT '食品编号',
fname varchar(50) NOT NULL COMMENT '食品名称',
price decimal(10,2) NOT NULL COMMENT '食品价格',
stock int NOT NULL COMMENT '库存数量',
sno int NOT NULL COMMENT '商店编号',
tno int NOT NULL COMMENT '食品类别编号',
PRIMARY KEY (fno),
FOREIGN KEY (sno) REFERENCES shop (sno),
FOREIGN KEY (tno) REFERENCES food_type (tno)
);
/* 订单 */
CREATE TABLE orders (
oid int NOT NULL COMMENT '订单编号',
order_time datetime NOT NULL COMMENT '下单时间',
cid int NOT NULL COMMENT '顾客ID',
sno int NOT NULL COMMENT '商店编号',
total_price decimal(10,2) COMMENT '总价',
PRIMARY KEY (oid)
);
/* 订单明细 */
CREATE TABLE order_detail (
id int AUTO_INCREMENT COMMENT '明细编号',
oid int NOT NULL COMMENT '订单编号',
fno int NOT NULL COMMENT '食品编号',
num int NOT NULL COMMENT '数量',
PRIMARY KEY (id)
);
/* 向 food_type 表中插入数据 */
INSERT INTO food_type (tno, tname) VALUES
(1, '川菜'),
(2, '粤菜'),
(3, '湘菜'),
(4, '鲁菜');
/* 向 customer 表中插入数据 */
INSERT INTO customer (cid, cname, pwd, cardid) VALUES
(1, '张三', '123456', '360102199001010015'),
(2, '李四', '654321', '360102199002020016'),
(3, '王五', 'abcdef', '360102199003030017'),
(4, '赵六', 'fedcba', '360102199004040018');
/* 向 shop 表中插入数据 */
INSERT INTO shop (sno, sname, addr) VALUES
(1, '老北京炸酱面', '南昌市洪都大街1号'),
(2, '天下第一小吃', '南昌市井冈山路2号'),
(3, '川渝香锅', '南昌市青山湖区麻坊街55号'),
(4, '东北乡村烧烤', '南昌市红谷滩新区维也纳国际B座');
/* 向 food 表中插入数据 */
INSERT INTO food (fno, fname, price, stock, sno, tno) VALUES
(1, '麻辣火锅', 88.00, 50, 3, 1),
(2, '宫保鸡丁', 38.00, 100, 3, 1),
(3, '回锅肉', 28.00, 120, 3, 1),
(4, '佛跳墙', 888.00, 10, 1, 2),
(5, '清蒸龙虾', 588.00, 8, 1, 2),
(6, '广东煲仔饭', 15.00, 150, 2, 2),
(7, '小资手工奶茶', 18.00, 200, 2, 4),
(8, '重庆辣子鸡', 48.00, 80, 3, 1),
(9, '担担面', 22.00, 150, 3, 1),
(10, '香辣火锅', 33.00, 100, 3, 1),
(11, '大盘鸡', 58.00, 70, 3, 1),
(12, '南瓜粥', 8.00, 200, 2, 4);
/* 向 orders 表中插入数据 */
INSERT INTO orders (oid, order_time, cid, sno) VALUES
(1, NOW(), 1, 1);语句:
delimiter $$
create procedure add_detail
(
in p_oid int,
in p_fno int,
in p_num int
)
label_p:begin
declare v_price decimal(10,2);
declare v_stock int;
declare v_total_price decimal(10,2);
-- 检查订单号是否有效
if not exists (select oid from orders where oid=p_oid) then
leave label_p;
end if;
-- 检查食品号是否有效
select price,stock into v_price,v_stock from food where fno=p_fno;
if v_price is NULL then
leave label_p;
end if;
-- 检查食品范围是否合理
if p_num<=0 or p_num>v_stock then
leave label_p;
end if;
-- 插入订单详情
insert into order_detail(oid,fno,num) values (p_oid,p_fno,p_num);
-- 自动更新食品对应库存
update food set stock=stock-p_num where fno=p_fno;
-- 自动计算订单总价
select sum(food.price*order_detail.num) into v_total_price from food,order_detail where food.fno=order_detail.fno and oid=p_oid;
update orders set total_price=v_total_price where oid=p_oid;
end$$
delimiter ;19.

20.

21.数据库类型是按照数据模型来划分的,层次模型、网状模型和关系模型是三种重要的数据模型

22.代理键是理想的主键,它的值对用户没有任何意义

23.利用视图不能加快查询速度

24.

25.在 Microsoft Access 数据库中,默认的数字型字段的数据类型是 "Number"。

26.数据流程图(DFD)是用于描述结构化方法中需求分析阶段的工具

27.视图是一个虚表,视图的构建基于基本表或视图
(数据流图必须与描述并组织数据条目的数据字典配套使用。没有数据字典,数据流图不精确;没有数据流图,数据字典不知用于何处)

28.在概念设计阶段采用E-R模型来描述概念结构,反应现实世界,设计出的图称为E-R图,也叫实体―关系图。

29.按照传统的数据模型分类,数据库系统可分为:层次模型,网状模型和关系模型

30.在视图上不能定义新的表

31.文件系统与数据库系统最大的区别在于:数据结构化
32.并发操作会带来哪些数据不一致性:丢失数据、不可重复读、读脏数据
33.如果仅仅提交更新部分的数据而不是全部数据违反了数据的哪个原则:原子性
34.数据库的封锁机制是什么的主要方法:并发控制
35.什么是DBMS的基本单位,它是用户定义的一组逻辑一致的程序序列:事务
36.事务是数据库进行的基本单位。如果一个事务执行成功,则全部更新提交;如果一个事务执行失败,则已做过的更新被恢复原状,这样保持了数据库处于什么状态:一致性
37.事务的一致性指的是:事务必须使数据库从一个一致性状态变成另一个一致性状态
38.解决并发操作带来的数据不一致性问题普遍采用:封锁
39.关于死锁,说法正确的是:只有出现并发操作时,才有可能出现死锁
40.对并发操作若不加以控制,可能会带来什么问题:不一致
并发操作如果不加以控制,可能会带来 丢失修改、不可重复读和读脏数据的数据不一致问题
41.数据库系统的并发控制的主要方法是采用什么机制:封锁
42.如果数据库中只包含成功事务提交的结果,则此数据库就称为处于什么状态:一致
43.如系统在运行过程中,由于某种原因,造成系统停止运行,致使事务在执行过程中以非控制方式终止,这时内存中的信息丢失,而存储在外存上的数据未受影响,这种情况称为:系统故障
44.若系统在运行过程中,由于某种硬件故障,使存储在外存上的数据部分损失或全部损失,这种情况称为:介质故障
45.什么用来记录数据库中数据进行的每一次更新操作:日志文件
46.后援副本的用途是:故障后的恢复
47.用于数据库恢复的重要文件是:日志文件
48.数据库恢复的基础是利用转存的冗余数据。这些转存的冗余数据包括:日志文件、数据库后备副本
49.在数据库的安全性控制中,为了保证用户只能存取他有权存取的数据,在授权的定义中,数据对象越怎样,授权子系统就越灵活:范围越小
50.授权编译系统和合法性检查机制一起组成了什么子系统:安全性
51.在数据系统中,对存取权限的定义称为:授权
52.数据库的什么是指数据的正确性和相容性:完整性
53.判断:持久性是指在事务提交以后,该事务所做的更改持久保存在存储介质中,不会被回滚 正确
54.系统死锁属于:事务故障
55.计算机系统中的三类安全性是指:①技术安全性 ②管理安全性 ③政策法律安全性
56.SQL的强制存取控制中,DBMS所管理的全部实体被分为主题和客体两大类。前者为系统中的活动实体,后者为系统中的被动实体,DBMS为它们每个实例(值)指派一个敏感度标记。
其中主题的敏感度标记称为许可证级别,客体的敏感度标记称为密级
强制存取控制规则
(1)仅当 主体 的许可证级别 大于 或 等于 客体 的密级时,该主体才能 读 相应的客体
(2)仅当 主体 的许可证级别 小于 或 等于 客体 的密级时,该主体才能 写 相应的客体
简记为:向下读,向上写

57.敏感度标记(label) :分为若干级别,绝密TS、机密S、可信C、公开P
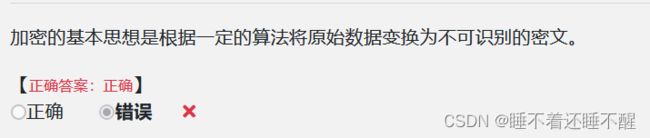
58.加密的基本思想是根据一定的算法将原始数据 -- ( 明文) 变换为不可直接识别的格式 - - (密文 ) ,从而使得不知道解密算法的人无法获知数据的内容。
58.角色是具有名称的一组相关权限的组合,即将不同的权限集合在一起就形成了角色,可以使用角色为用户授权,同样也可以撤销角色。由于角色集合了多种权限,相当于为用户授予了多种权限,这样就避免了为用户逐一授权,从而简化了用户权限的管理。
59.