list的讲解及模拟实现(c++)
与介绍vector时相同为了方便大家理解, 我们采用边模拟实现边讲解使用的方式, 展开对list容器的讲解.
目录
一.list的介绍
二.list中的经常使用的一些方法
1.构造函数
2.迭代器的使用
3.容量的相关函数
4.容器中元素的访问
5.容器中元素的修改
三.list实现中的相关声明(后面对其进行具体实现)
四.list中的节点类
五.list中迭代器的封装
1.一个友元外加两个重命名
2.构造函数
3.拷贝构造函数
4.*运算符重载
5.->运算符重载
6.前置++和后置++
7.前置--和后置--
8.==和!=的重载
9.注意
六.list类的成员函数
1.六个重命名
2.创建头结点
3.list的构造
4.迭代器的使用
5.list容量相关操作
6.list中元素的访问
7.list中元素的修改
8.list的迭代器失效问题
七.list和vector的对比
一.list的介绍
使用时注意包含头文件: #include
list相关特性介绍:
1.list的底层是一个带头结点的双向循环链表.
2. list是可以在常数范围内在任意位置进行插入和删除的序列式容器, 并且该容器可以前后双向迭代.
3. list的底层是双向链表结构, 双向链表中每个元素存储在互不相关的独立节点中, 在节点中通过指针指向其前一个元素和后一个元素.
4. list与forward_list非常相似:最主要的不同在于forward_list是单链表, 只能朝前迭代, 而list让其更简单高效.
5. 与其他的序列式容器相比(array,vector,deque), list通常在任意位置进行插入、移除元素的执行效率更好.
6. 与其他序列式容器相比, list和forward_list最大的缺陷是不支持任意位置的随机访问, 比如: 要访问list的第6个元素, 必须从已知的位置(比如头部或者尾部)迭代到该位置, 在这段位置上迭代需要线性的时间开销;list还需要一些额外的空间, 以保存每个节点的相关联信息.(对于存储类型较小元素的大list来说这可能是一个重要的因素)
7.在类和对象的位置, 知道静态成员变量, 也可以通过: 类名: :静态成员变量 进行访问, 而类中包含的其他类型, 也可以通过: 类名: :类内部定义类型 使用, 但要注意访问的是类型时要以"typename"为前缀来表示类型, 要不然编译器无法区分是类型还是静态成员变量.
前面看不懂没关系, 跟随讲解后面便会一一了解.
二.list中的经常使用的一些方法
1.构造函数

2.迭代器的使用
![]()
我们这里要注意, 前面介绍过的string和vector中因为底层使用的是连续空间的原因, 他们的迭代器都是原生态的指针, 但到list就不同了, list的底层是以双向链表的方式组织起来的不同空间位置的节点, 此时我们必须在list的类外重新封装一个迭代器的类, 该迭代器类中必须对++,--,==,!=等运算符进行重载, 与其他容器中的迭代器的某些功能保持一致, 之所以这样要求是因为有一些常用的算法例如: sort, find等等, 我们只用实现一份代码然后用不同容器的迭代器进行传参, 就能使用该算法, 不仅节省了资源, 还能防止了出现大量的重复代码.
3.容量的相关函数

4.容器中元素的访问

5.容器中元素的修改
三.list实现中的相关声明(后面对其进行具体实现)
我们要实现的list, c++系统已经给出了, 所以我们这里的实现将其放到自已定义的一个命名空间中.
namespace lz {
// List的节点类
template class list;
template
struct ListNode {
ListNode(const T& val = T());
ListNode* _pPre;
ListNode* _pNext;
T _val;
};
//List的正向迭代器类
template
class ListIterator {
friend class list;
typedef ListNode* PNode;
typedef ListIterator Self;
public:
ListIterator(PNode pNode = nullptr);
ListIterator(const Self& l);
T& operator*();
T* operator->();
Self& operator++();
Self& operator++(int);
Self& operator--();
Self& operator--(int);
bool operator!=(const Self& l);
bool operator==(const Self& l);
private:
PNode _pNode;
};
//list类
template
class list {
typedef ListNode Node;
typedef Node* PNode;
public:
typedef ListIterator iterator;
typedef ListIterator const_iterator;
public:
///
// List的构造
list();
list(int n, const T& value = T());
template
list(Iterator first, Iterator last);
list(const list& l);
list& operator=(list l);
~list();
///
// List Iterator
iterator begin();
iterator end();
const_iterator begin() const;
const_iterator end() const;
///
// List Capacity
size_t size()const;
bool empty()const;
// List Access
T& front();
const T& front()const;
T& back();
const T& back()const;
// List Modify
void push_back(const T& val);
void pop_back();
void push_front(const T& val);
void pop_front();
// 在pos位置前插入值为val的节点
iterator insert(iterator pos, const T& val);
// 删除pos位置的节点,返回该节点的下一个位置
iterator erase(iterator pos);
void clear();
void swap(list& l);
private:
void CreateHead();
PNode _pHead;
};
};
四.list中的节点类
说明:
因为在list底层是一个带头结点的双向循环链表, 所以我们要对其节点进行封装, 具体形式和C语言中的相同, 两个类类型的指针, 一个指向前面的节点类, 一个指向后面的节点类, 再加一个数据域来存储数据, 我们这里采用模板类的方式进行实现, 与c++系统的list保持同步, 并且这种模板类的方式, 可以针对于各种类型的数据, 只用使用者使用时将类型传入即可, 避免了同类代码的冗余.
代码说明:
根据上面说明的, 我们类中的数据成员有三个, 类类型的两个指针, 外加一个数据域, 再自定义一个传入数据用来初始化的构造函数即可, 至于节点的组织则再list类中进行实现.
// List的节点类
template class list;
template
struct ListNode {
ListNode(const T& val = T()) {//构造函数
_pPre = nullptr;
_pNext = nullptr;
_val = val;
}
//数据成员
ListNode* _pPre;
ListNode* _pNext;
T _val;
};
五.list中迭代器的封装
1.一个友元外加两个重命名
friend class list;
typedef ListNode* PNode;
typedef ListIterator Self;
①.我们需要在迭代器的类中将list类声明为其的友元类, 因为我们实现迭代器类就是为了在list中使用, 所以在list中需要访问到迭代器中的所有成员.
②.对节点类的类类型指针进行重命名, 方便我们后续的使用.
③.对自身的类类型进行重命名, 方便后续的使用.
2.构造函数
ListIterator(PNode pNode = nullptr) {
_pNode = pNode;
}
说明: 我们封装的迭代器类, 只是为了在遍历容器时与其他容器保持一致, 因此该迭代器类中只需要存储节点的地址就行, 我们就可以根据节点的地址去对--, ++, 这种类型的运算符进行重载了, 因此对于迭代器类的构造函数我们传入节点地址进行初始化即可.
3.拷贝构造函数
ListIterator(const Self& l) {
_pNode = l._pNode;
}
拷贝构造函数就更简单了, 直接将参数中类类型对象的引用中的节点地址, 赋值给该对象的数据成员就行.
4.*运算符重载
T& operator*() {
return _pNode->_val;
}
跟别的容器中的原生态指针类型的迭代器相同, 对迭代器解引用就可以访问到迭代器指向位置的元素, 因此我们在list的迭代器类中对*进行重载时, 就要返回该迭代器所指向的节点中存储的数据.
5.->运算符重载
T* operator->() {
return &(_pNode->_val);
}
我们平时拿到一个结构体的地址要想访问该结构体中的成员的话, 就需要使用->这个运算符, 而这里我们对迭代器使用->时想要访问到迭代器指向的节点中的数据域, 但是我们这里函数返回的明明是数据域的地址呀, 而根据我们这样的重载要想访问到节点的数据域则需要使用->->两次这个运算符才行, 这里就需要了解c++中的机制了, c++中默认对于->->进行了优化, 将->->省略为->, 所以我们这里只用返回数据域的地址就行, 用户对迭代器使用->, 在编译器编译时会默认将->转化为->->从而获取到节点的数据域.
6.前置++和后置++
Self& operator++() {
_pNode = _pNode->_pNext;
return *this;
}
Self& operator++(int) {
Self temp(_pNode);
_pNode = _pNode->_pNext;
return temp;
}
对于这两个运算符的重载我们必须参考其他容器中以原生态指针为迭代器时, 他们的++是有什么作用, 在对一个指向连续内存空间的指针进行++时, 就是让其向后移动一个类型的单位, 指向空间中该元素的下一个元素, 那么在list的迭代器中, ++操作也应该让迭代器向后移一位, 指向该节点的下一个节点, 因此在前置++的重载中直接让该迭代器类的数据成员存储其下一个节点的地址即可, 为了区分前置++和后置++我们特意在后置++的参数位置加一个int方便区分, 而进行后置++重载时, 要注意后置++, 加完之后, 实际迭代器指向的位置改变了, 但是返回值是没有改变的, 因此我们需要创建一个临时的迭代器类型的对象存储++前的节点的地址, 并在函数最后将其返回.
7.前置--和后置--
Self& operator--() {
_pNode = _pNode->_pPre;
return *this;
}
Self& operator--(int) {
Self temp(_pNode);
_pNode = _pNode->_pPre;
return temp;
}
对于--操作的重载和前面++相同, 参考于指向连续空间的指针的--操作, 相当与该指针向前移一位, 指向空间中该元素的前一个元素, 因此对于前置--的重载我们只需让迭代器类中的数据成员存储其前一个节点的地址, 前置--和后置--的区分依旧是使用参数列表的int, 对后置--进行重载时创建一个临时的迭代器类对象指向该节点, 而本迭代器对象存储该节点的前一个节点的地址, 函数最后返回这个临时对象即可.
8.==和!=的重载
bool operator!=(const Self& l) {
return _pNode == l._pNode ? false : true;
}
bool operator==(const Self& l) {
return _pNode == l._pNode;
}
因为我们list里面节点在内存中的存储位置不是连续的, 没法比较大小只能对比是否相同, 所以在这里只对==和!=运算符进行重载, 对==重载时如果相等返回true反之返回false, 对与!=重载时如果不等返回true反之返回false.
9.注意
在list中还有一个反向的迭代器类需要封装, 而封装反向迭代器类有两种方法, ①.依照上面的正向迭代器再原原本本实现一个, ②.或者在反向迭代器的类中直接调用正向迭代器进行实现.(对于这种我们也称其为迭代器适配器)
在这里我们不一一实现了, 正向迭代器会了, 反向迭代器就变的很简单了.
六.list类的成员函数
1.六个重命名
private:
typedef ListNode Node;
typedef Node* PNode;
public:
typedef ListIterator iterator;
typedef ListIterator const_iterator;
typedef ReverseListIterator Riterator;
typedef ReverseListIterator const_Riterator;
(重命名的作用就是为了方便使用)
前两个重命名是私有类型的:
①.对节点的类类型进行重命名.
②.对节点的类类型指针进行重命名.
后四个重命名是公有类型的:
①.对正向迭代器的类类型进行重命名.
②.对正向迭代器的const类类型进行重命名.(有的成员函数需要使用const类型的迭代器实现)
③.对反向迭代器的类类型进行重命名.
④.对反向迭代器的const类类型进行重命名.
2.创建头结点
void CreateHead() {
_pHead->_pNext = _pHead;
_pHead->_pPre = _pHead;
}
我们的list中不需要存储别的东西, 因为list是一个带头结点的双向循环链表, 因此只用将其头结点存储起来, 依照头结点就能访问到链表中的所有结点了, 所以我们定义一个创建头结点的函数, 在构造函数中使用, 后续插入的元素全部链接在头结点后面, 因为是循环的双向链表所以让其next和pre都指向自己.
3.list的构造
a.构造函数
list() {
_pHead = new Node;
CreateHead();
}
首先给数据成员, 也就是头结点, 申请空间并调用createHead函数创建它.
b.以n个val初始化构造list
list(int n, const T& value = T()) {
_pHead = new Node;
CreateHead();
for (int i = 0; i < n; i++) {
push_back(value);
}
}
同样的, 先申请空间创建头结点, 然后使用循环向头结点后面插入n个值域为value的结点.
(使用push_back()后面会介绍)
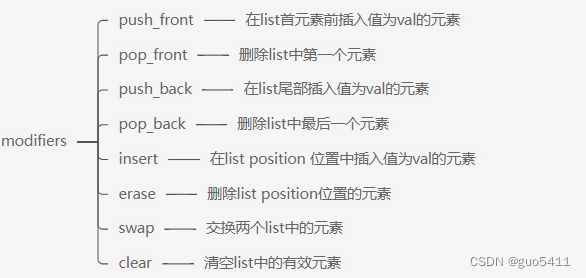
测试:(注意put是我们自定义的一个打印list中所有元素的函数)
lz::lista1(4, 1); put(a1); 运行结果:
c.区间构造
template
list(Iterator first, Iterator last) {
_pHead = new Node;
CreateHead();
while (first != last) {
push_back(*first);
first++;
}
}
我们定义区间构造函数时是不知道用户会以那种区间传入来构造list的, 因此以函数模板的方式定义该函数, 因为是构造函数所以进入函数的第一步就是申请空间创建头结点, 然后遍历区间将区间中的元素全部插入到头结点后面. (既然是区间那么对应的空间应该是连续的, 如果不是连续的那么其类中也应对++运算符进行重载, 否则就无法调用该构造函数)
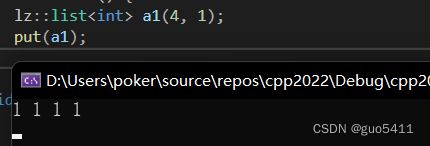
测试:
int a[] = { 1,2,3,4,5,6,7,8 }; lz::lista1(a, a + sizeof(a) / sizeof(a[0])); put(a1); 运行 结果:
d.拷贝构造
list(const list& l) {
_pHead = new Node;
CreateHead();
const_iterator i = l.begin();
while (i != l.end()) {
push_back(*i);
i++;
}
}
首先第一步, 申请空间创建头结点, 我们可以看到, 这个函数的参数是const类型的list对象,
因此想要遍历它, 我们就必须使用到上面的const类型的迭代器了, 创建一个迭代器指向参数链表的首元素, 然后遍历该链表并将其元素插入到我们新创建的链表中.
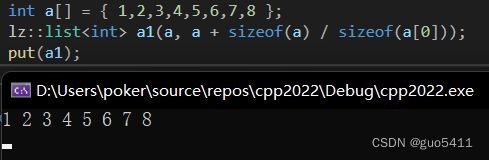
测试:
int a[] = { 1,2,3,4,5,6,7,8 }; lz::lista1(a, a + sizeof(a) / sizeof(a[0])); lz::list a2(a1); put(a2); 运行结果:
e.赋值运算符重载
list& operator=(list l) {
swap(l);
return *this;
}
这个就简单了, 因为我们的参数是以传值的方式进行的, 因此参数L的出现已经是调用过拷贝构造函数对于实参拷贝了一份了, 所以我们只用将该list对象中的结点指针指向L就行了, 调用swap函数将L中的头结点交换过来.
测试:
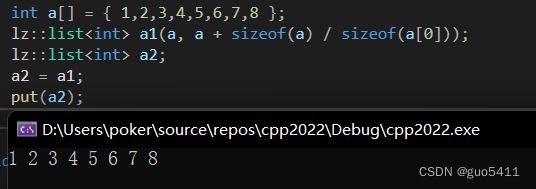
int a[] = { 1,2,3,4,5,6,7,8 }; lz::lista1(a, a + sizeof(a) / sizeof(a[0])); lz::list a2; a2 = a1; put(a2); 运行结果:
f.析构函数
~list() {
if (_pHead != nullptr) {
clear();
delete _pHead;
_pHead = nullptr;
}
}
判断头结点是否指向空, 指向空无需释放, 不指向空先将链表中的元素清空, 然后释放头结点对应的空间, 并让指向头结点的指针指向空.
4.迭代器的使用
a.四个正向迭代器的初始化函数
iterator begin() {
return _pHead->_pNext;
}
iterator end() {
return _pHead;
}
const_iterator begin() const{
return _pHead->_pNext;
}
const_iterator end() const{
return _pHead;
}
创建迭代器, 调用begin()函数那么该迭代器会指向第一个元素, 因此在begin()中我们返回头结点的下一位, 也就是首元素, 调用end()函数那么该迭代器会指向最后一个元素的后一位, 因此在end()函数中直接返回头结点就行, 因为是双向循环链表所以头结点是最后一个元素的后一位.(const类型的也相同)
测试:
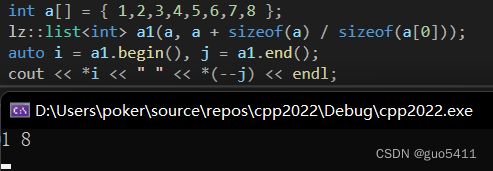
int a[] = { 1,2,3,4,5,6,7,8 };
lz::list a1(a, a + sizeof(a) / sizeof(a[0]));
auto i = a1.begin(), j = a1.end();
cout << *i << " " << *(--j) << endl;
运行结果:
b.四个反向迭代器的初始化函数
Riterator rbegin() {
return _pHead->_pPre;
}
Riterator rend() {
return _pHead;
}
const_Riterator rbegin() const{
return _pHead->_pPre;
}
const_Riterator rend() const{
return _pHead;
}
创建迭代器, 调用rbegin()函数则指向最后一个元素, 因此在rbegin()函数中我们返回头结点的前一位, 也就是最后一个结点, 调用rend()函数则指向第一个元素的前一位, 因此我们在rend()函数中返回头结点即可, 头结点就是第一个结点的前一位.(const类型的实现也相同)
测试:
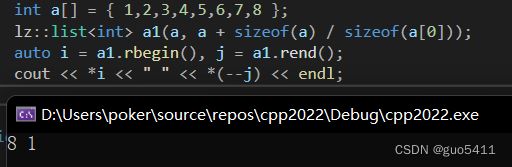
int a[] = { 1,2,3,4,5,6,7,8 };
lz::list a1(a, a + sizeof(a) / sizeof(a[0]));
auto i = a1.rbegin(), j = a1.rend();
cout << *i << " " << *(--j) << endl;
运行结果:
5.list容量相关操作
a.链表中有效元素个数
size_t size()const {
size_t count = 0;
const_iterator i = begin();
while (i != end()) {
count++;
i++;
}
return count;
}
我们在函数中使用迭代器遍历链表,参数为const类型, 因此迭代器也要使用const类型的, 用count进行计数, 最终返回count的值即可.
测试:
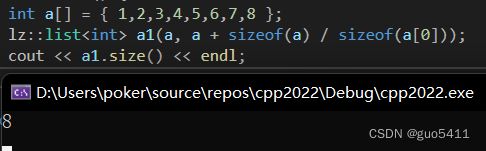
int a[] = { 1,2,3,4,5,6,7,8 };
lz::list a1(a, a + sizeof(a) / sizeof(a[0]));
cout << a1.size() << endl;
运行结果:
b.判断链表是否为空
bool empty()const {
if (size() == 0) {
return true;
}
return false;
}
直接调用size()函数, 判断有效元素个数是否为0, 如果为0则链表为空, 如果不为0则链表不空.
6.list中元素的访问
list底层使用的空间是不连续的, 因此不能像vector那样能依靠下标直接访问空间中的元素, list中只有首元素和尾元素可以直接访问, 因为他们都是和头结点直接接触的, 而其他结点的访问需要遍历链表, 因此c++中只给出了首元素和尾元素的访问函数, 如果要访问其他元素, 则需要用户自己去遍历.
a.访问首元素
T& front() {
if (size() == 0) {
assert(false);
}
return _pHead->_pNext->_val;
}
const T& front()const {
if (size() == 0) {
assert(false);
}
return _pHead->_pNext->_val;
}
在函数中先判断链表中是否存在元素, 如果不存在那就无法访问了, 直接返回报错, 存在的话返回头结点的后一个结点中的数据域, 我们的第一个结点也就是头结点的后一个,首元素则存
在其中.(const类型的实现完全相同)
测试:
int a[] = { 1,2,3,4,5,6,7,8 };
lz::list a1(a, a + sizeof(a) / sizeof(a[0]));
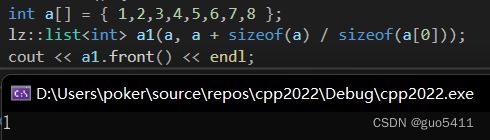
cout << a1.front() << endl;
运行结果:
b.访问尾元素
T& back() {
if (size() == 0) {
assert(false);
}
return _pHead->_pPre->_val;
}
const T& back()const {
if (size() == 0) {
assert(false);
}
return _pHead->_pPre->_val;
}
进入函数先判断链表中是否存在有效元素, 不存在报错返回, 存在则返回头结点的前一个结点中的数据域, 因为尾结点就是头结点的前一位, 最后一个元素也存在其中.(const类型的实现完全相同)
测试:
int a[] = { 1,2,3,4,5,6,7,8 };
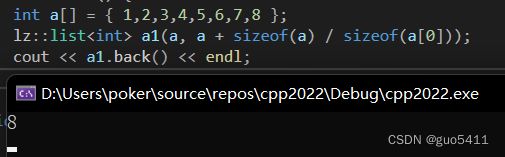
lz::list a1(a, a + sizeof(a) / sizeof(a[0]));
cout << a1.back() << endl;
运行结果:
7.list中元素的修改
a.尾插尾删和头插头删
在这里我们四个函数都分别调用insert和erase实现后面会讲解insert和erase的实现.
void push_back(const T& val) { insert(end(), val); }
void pop_back() { erase(--end()); }
void push_front(const T& val) { insert(begin(), val); }
void pop_front() { erase(begin()); }
①.尾插, 使用insert在最后一个位置插入一个val即可, 插入的位置使用迭代器进行传参.
②.尾删, 传入要删除元素的位置(使用迭代器), 调用erase直接删除.
③.头插, 使用insert在第一个位置插入一个val即可, 插入的位置使用迭代器进行传参.
④.头删, 传入要删除元素的位置(使用迭代器), 调用erase直接删除.
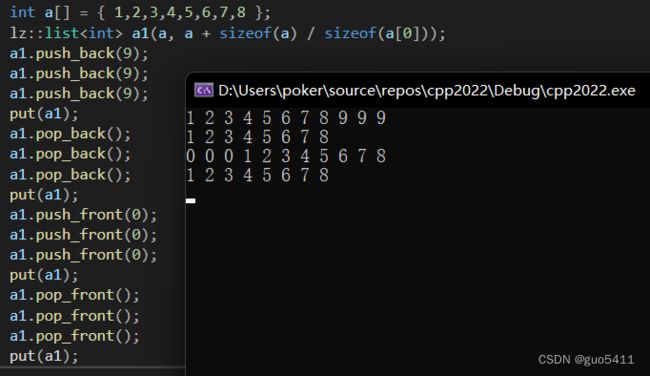
测试:
int a[] = { 1,2,3,4,5,6,7,8 };
lz::list a1(a, a + sizeof(a) / sizeof(a[0]));
a1.push_back(9);
a1.push_back(9);
a1.push_back(9);
put(a1);
a1.pop_back();
a1.pop_back();
a1.pop_back();
put(a1);
a1.push_front(0);
a1.push_front(0);
a1.push_front(0);
put(a1);
a1.pop_front();
a1.pop_front();
a1.pop_front();
put(a1);
运行结果:
b.任意位置的插入(insert)
iterator insert(iterator pos, const T& val) {
PNode temp = new Node(val);
temp->_pNext = pos._pNode;
temp->_pPre = pos._pNode->_pPre;
temp->_pPre->_pNext = temp;
pos._pNode->_pPre = temp;
return iterator(temp);
}
参数:一个是插入位置(迭代器指向的位置), 一个新插入结点值域的值.
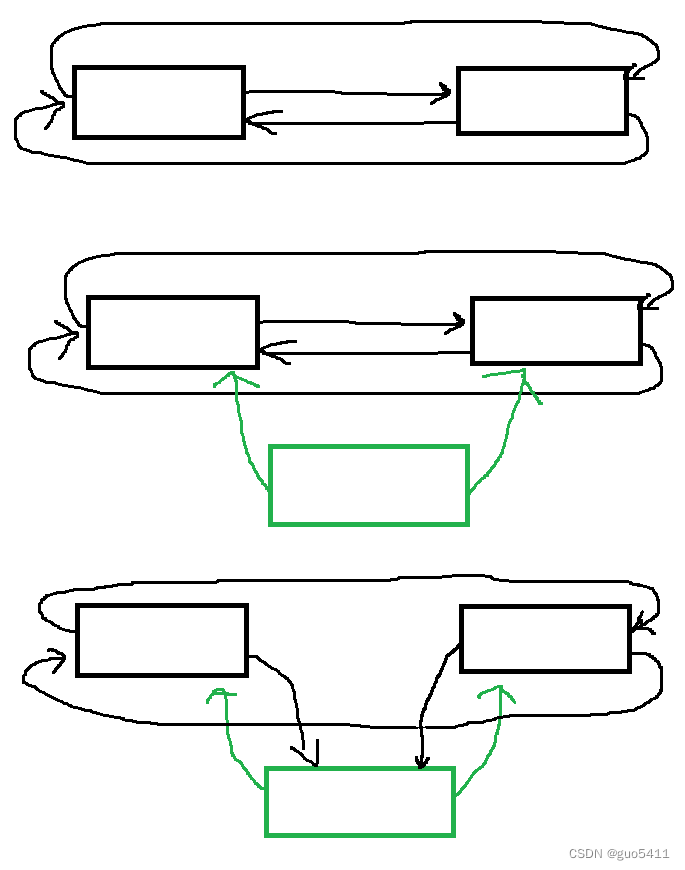
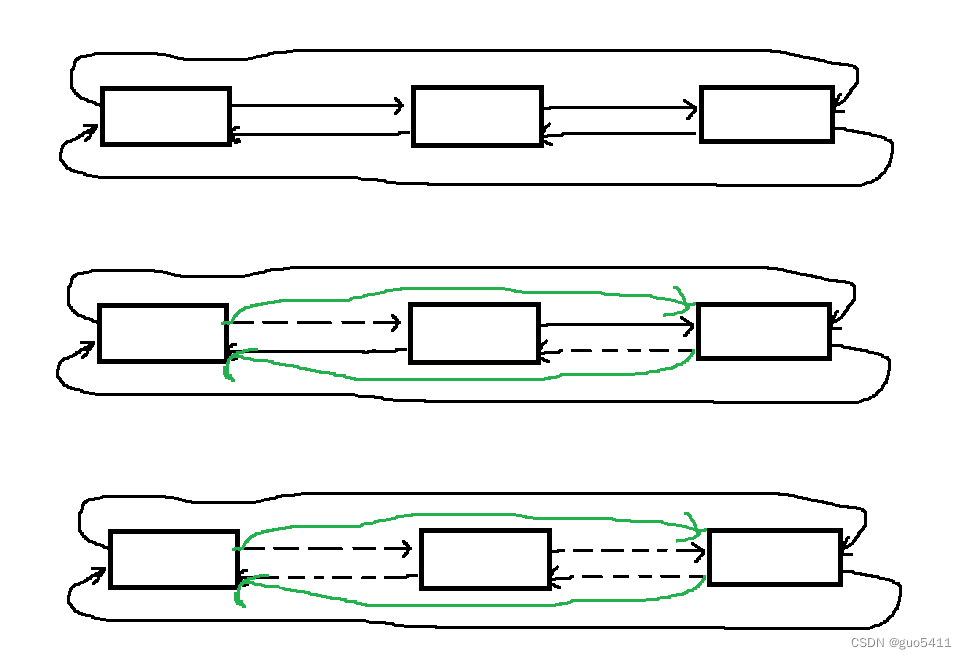
要想插入新元素必须创建新的结点, 我们以val为值域的值创建新的结点并将其插入链表中, 第一步新创建的结点next指针指向要插入位置的元素, pre指针指向该位置的前一个元素, 然后要插入位置的前一个元素的next指针指向我们新创建的这个元素, 最后将要插入位置的元素的pre指针指向我们的新结点即可, 此时我们的新结点插入链表已经完成了, 返回值类型为迭代器的类类型, 我们这里返回一个指向新插入结点的迭代器, 方便用户后面使用.
图示插入过程:
测试:
int a[] = { 1,2,3,4,5,6,7,8 };
lz::list a1(a, a + sizeof(a) / sizeof(a[0]));
auto pos = a1.begin();
pos++;
pos++;
a1.insert(pos, 11);
a1.insert(pos, 12);
a1.insert(pos, 13);
a1.insert(pos, 14);
put(a1);
运行结果:
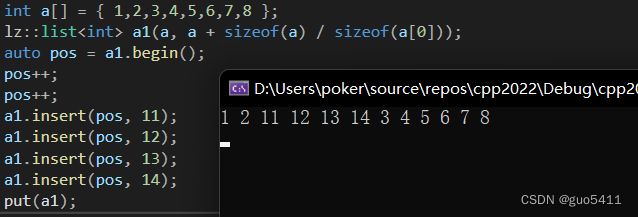
c.任意位置的删除(erase)
iterator erase(iterator pos) {
iterator temp(pos._pNode->_pNext);
pos._pNode->_pPre->_pNext = pos._pNode->_pNext;
pos._pNode->_pNext->_pPre = pos._pNode->_pPre;
delete pos._pNode;
pos._pNode = nullptr;
return temp;
}
(迭代器失效的问题在最后会详细讲解)
改变要删除位置前后结点中指针的指向就行, 创建一个新的迭代器指向要删除位置的后一个结点(供函数最后返回给用户, 方便用户继续使用, 因为删除操作执行完之后, 传入的pos迭代器就会失效), 第一步将要删除位置前一个结点的next指针指向要删除位置的后一个结点, 第二步将要删除位置的后一个结点的pre指针指向要删除位置的前一个结点, 第三步释放要删除的这个位置的结点所在的空间并将迭代器中记录该空间的地址清空防止后续访问, 最后返回新的迭代器就行.
图示删除过程:
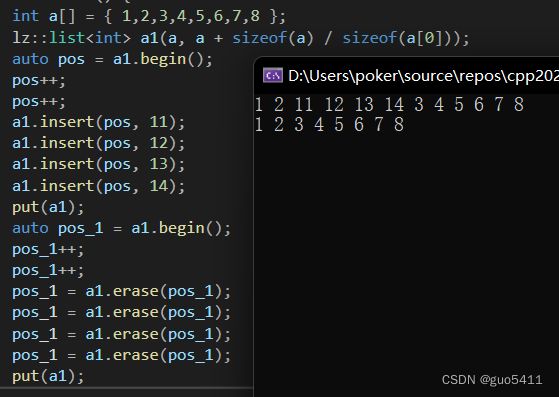
测试:
int a[] = { 1,2,3,4,5,6,7,8 };
lz::list a1(a, a + sizeof(a) / sizeof(a[0]));
auto pos = a1.begin();
pos++;
pos++;
a1.insert(pos, 11);
a1.insert(pos, 12);
a1.insert(pos, 13);
a1.insert(pos, 14);
put(a1);
auto pos_1 = a1.begin();
pos_1++;
pos_1++;
pos_1 = a1.erase(pos_1);
pos_1 = a1.erase(pos_1);
pos_1 = a1.erase(pos_1);
pos_1 = a1.erase(pos_1);
put(a1);
运行结果:
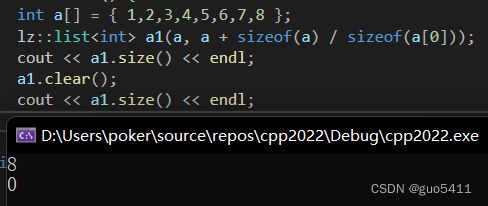
d.清空有效元素
void clear() {
CreateHead();
}
清空有效元素让list中只存在一个头结点, 我们直接调用创建头结点的函数, 让头结点的next和pre指针都指向自己, 这样其他的元素结点就无法再访问到了, 有效元素个数自然就清空了.
测试:
int a[] = { 1,2,3,4,5,6,7,8 };
lz::list a1(a, a + sizeof(a) / sizeof(a[0]));
cout << a1.size() << endl;
a1.clear();
cout << a1.size() << endl;
运行结果:
e.内置交换函数(swap)
void swap(list& l) {
std::swap(_pHead, l._pHead);
}
既然是内置的交换函数, 自然是用来交换两个list对象所对应的链表的, 我们在list中只保存链表的头结点的地址, 依靠头结点就可以找到链表中的所有元素, 因此在这里将两个list中存储的头结点的地址交换即可, 调用c++系统的swap进行交换, 交换完后, 两个list对象分别存储着对方的头结点的地址, 也就完成了内置swap的功能了.
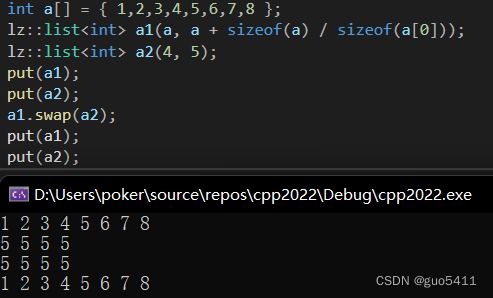
测试:
int a[] = { 1,2,3,4,5,6,7,8 };
lz::list a1(a, a + sizeof(a) / sizeof(a[0]));
lz::list a2(4, 5);
put(a1);
put(a2);
a1.swap(a2);
put(a1);
put(a2);
运行结果:
8.list的迭代器失效问题
list中的成员都是使用结点的方式进行数据存储的(非连续空间), 并用链表进行组织, 而我们使用的迭代器可以看做记录结点地址的指针, 因此只有当我们删除在这个迭代器位置的结点时,该迭代器才会失效, 而其他的插入操作并不会使迭代器失效.
七.list和vector的对比
a.图示
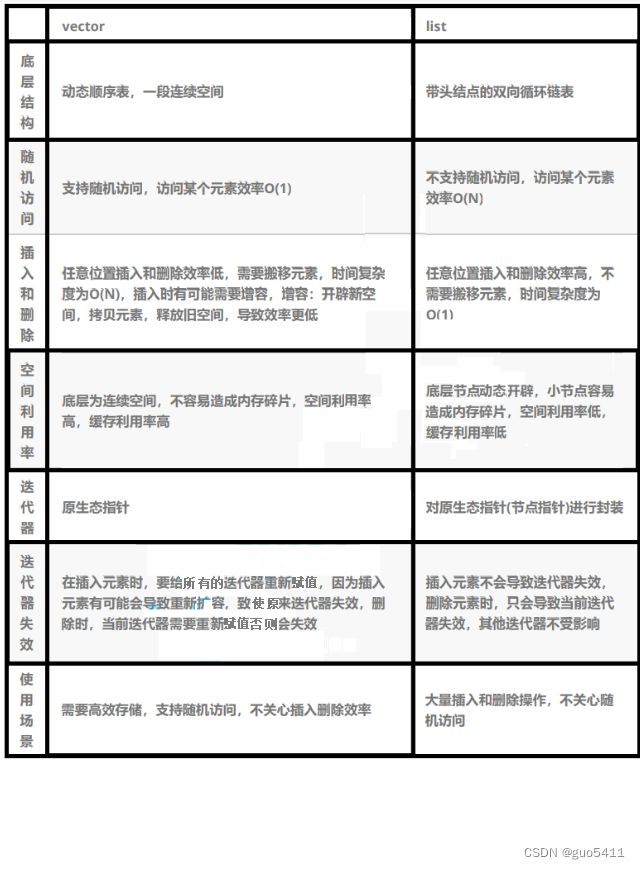
其它的区别, 相信经过前面的学习大家都已经了解了, 我们这里只针对缓存利用率做个解释.
缓存利用率: 因为vector中数据的存储空间是连续的, 因此将其加载到缓存中的时候, 是一整块全部加载的, 而list中的存储空间是分散的, 因此再将其加载到缓存中时, 有的结点可能进来了, 有的可能没进来, 所以说list的缓存利用率低, 而vector的缓存利用率高.