【业务功能篇44】Mysql 海量数据查询优化,进行分区操作
业务场景:当前有个发料表,随着业务数据量增多,达到了几千万级别水平,查询的效率就越来越低了,针对当前的架构情况,我们进行了分区的设置,通过对时间字段,按年月,一个月作为一个分区,这样查询效率会有一定程度的提升
业务上,会查询表中多个字段,比如条码,批次,时间。其中,作为时间字段来说,可能是种类比较少的,分区的个数不建议过多,那么我们最后就选择了按时间分区
- 由于表是先创建的,后续进行分区的设计,所以就是要进行修改表
- PARTITION by LIST COLUMNS (YEAR_MON) 按照时间列分区,这里采用按一个月为一个分区,进行划分,如果数据量越发增大,可能后续也需要将较远的历史数据分区切到一个外部表中
- 假如一个月的数据量不多,结合实际业务场景,可能将多个月划分在一个分区中
分区表的操作sql
alter table `表名称` PARTITION by LIST COLUMNS (YEAR_MON)
(
PARTITION p1 VALUES IN ('2023-01'),
PARTITION p2 VALUES IN ('2023-02'),
PARTITION p3 VALUES IN ('2023-03'),
……
PARTITION pN VALUES IN ('2023-07')
)- 下面介绍下分区整体的一些知识点
- 一个表最多只能有1024个分区(mysql5.6之后支持8192个分区)
分区类型
range,list,hash,key这四种分区中,分区的条件是:数据必须是整型,如果不是整型,那应该通过函数将其转化为整型(如:YEAR(),TO_DAYS(),MONTH()等函数)。
range分区
- 对于range分区的查询,优化器只能对YEAR(),TO_DAYS(),TO_SECONDS(),UNIX_TIMESTAMP()这类函数进行优化分区。
create table sales (
money int unsigned not null,
date datetime
) engine=innodb
partition by range (TO_DAYS(date)) (
partition p201001 values less than (TO_DAYS('2010-02-01')),
partition p201002 values less than (TO_DAYS('2010-03-01')),
partition p201003 values less than (TO_DAYS('2010-04-01'))
);
list分区
- list分区,如果是插入多行数据时,有不符合分区规则情况下,myisam存储引擎会存放符合分区规则的,而innodb会把它看成一个事务,不会插入数据,会报错
create table t1(
a int,
b int
) engine=innodb
partition by list(b) (
partition p0 values in (1,3,5,7,9),
partition p1 values in (0,2,4,6,8)
);
hash分区
- --- hash分区 是将数据均匀的分配到预先定义的各个分区中,保证各分区的数量大致都是一样的
- --- 要使hash分区来分割一个表,要在create table 语句上添加“partition by hash(expr)”子句,其中expr是一个返回一个整数的表达式,它可以仅仅是字段类型为mysql整型的列名。
- --- 此外用户很可能需要在后面再添加一个"partitions num"子句,其中num是一个非负整数,表示表将要分割成分区的数量,没有这个子句,默认是1
- hash分区是取模算法:如b为2010-04-01时 mod(year('2010-04-01'), 4) = mod(2010, 4) = 2 因此记录会被放入分区p2中。
create table t2(
a int,
b datetime
) engine=innodb
partition by hash (year(b))
partitions 4;另一种hash分区——linear hash(hash算法不同)
- 这种分区算法的优点是:增加、删除、合并、和拆分分区将变得更加快捷,有利于含有处理大量数据的表。
- 缺点是:与使用hash分区得到的数据分布相比,各个分区间数据的分布可能不大均匀。
- 分区算法是:同样是2010-04-01
- 1、取大于分区数量num=4的下一个2的幂值V,V = power(2, ceiling(log(2, NUM))) = 4;即log以2为底num的指数作为2的幂值。2^log(2, num)
- 2、所在分区N = YEAR('2010-04-01') & (V - 1) = 2
create table t3(
a int,
b datetime
)engine=innodb
partition by linear hash (year(b))
partitions 4;key分区
- key分区和hash分区相似,不同之处在于hash分区使用用户定义的函数进行分区,key分区使用MySQL数据库提供的函数进行分区。对于NDB cluster引擎,MySQL数据库使用MD5函数分区,对于其他的数据库引擎,MySQL数据库使用其内部的哈希函数,这些函数基于与password()一样的运算法则
- 在key分区中使用关键字linear和在hash分区中使用具有相同的效果,分区标号是通过2的幂算法(powers-of-two)得到的,而不是通过模数算法。
create table t4(
a int,
b datetime
)engine=innodb
partition by key (b)
partitions 4;columns分区
MySQL5.5版本开始支持columns分区,可以看做range分区和list分区的一种进化。
columns分区可以直接使用非整型的数据进行分区,分区根据类型直接比较而得,不需要转化为整型。
columns分区支持以下的数据类型:
1、所有的整数类型,如int,smallint,tinyint,mediumint,bigint。float和decimal则不予支持
2、日期类型,如date和datetime。其余的日期类型不予支持。
3、字符串类型,如char,varchar,binary和varbinary。blob和text类型不予支持。
range columns
create table t5(
a int,
b datetime
)engine=innodb
partition by range columns (b) (
partition p0 values less than ('2009-01-01'),
partition p1 values less than ('2010-01-01')
);range columns 分区可以对多个列的值进行分区。
create table t5_rcx(
a int,
b int,
c char(3),
d int
)engine=innodb
partition by range columns (a,d,c) (
partition p0 values less than (5, 10, 'ggg'),
partition p1 values less than (10, 20, 'mmm'),
partition p2 values less than (15, 20, 'sss'),
partition p3 values less than (maxvalue, maxvalue, maxvalue)
);list columns 中文也可以
create table t6(
first_name varchar(25),
last_name varchar(25),
street_1 varchar(30),
street_2 varchar(30),
city varchar(15),
renewal date
)engine=innodb
partition by list columns (city) (
partition pRegion_1 values in ('北京','上海','广州'),
partition pRegion_2 values in ('武汉','郑州','成都')
);子分区
子分区是指在分区的基础上再进行分区,也称该分区为复合分区。MySQL允许在range和list的分区上再进行hash和key的子分区。
子分区建立需要注意以下几个问题:
1、每个子分区的数量必须相同
2、要在一个分区表的任何分区上使用subpartition明确定义任何子分区,就必须定义所有的子分区。
3、每个subpartition子句必须包括子分区的一个名字
4、子分区的名字必须是唯一的。
b列进行range分区,又进行了一次hash分区,分区的数量是(3 x 2 = 6)
create table ts(
a int,
b date
)engine=innodb
partition by range (YEAR(b))
subpartition by hash(TO_DAYS(b))
subpartitions 2
(
partition p0 values less than (1990),
partition p1 values less than (2000),
partition p2 values less than maxvalue
);我们也可以使用subpartition语法显示的指出各个子分区的名字:
create table dspy_sub_name(
a int,
b date
)engine=innodb
partition by range (YEAR(b))
subpartition by hash (TO_DAYS(b))
(
partition p0 values less than (2009) (
subpartition s0,
subpartition s1
),
partition p1 values less than (2010) (
subpartition s2,
subpartition s3
),
partition p2 values less than maxvalue (
subpartition s4,
subpartition s5
)
);子分区可以用于特别大的表,在多个磁盘间分别分配数据和索引。假设有6个磁盘,分别为/disk0,/disk1,/disk2等,现在考虑下面的例子:
create table ts1(
a int,
b date
)engine=innodb
partition by range (YEAR(b))
subpartition by hash (TO_DAYS(b))
(
partition p0 values less than (2009) (
subpartition s0
DATA DIRECTORY = '/disk0/data'
INDEX DIRECTORY = '/disk0/idx',
subpartition s1
DATA DIRECTORY = '/disk1/data'
INDEX DIRECTORY = '/disk1/idx'
),
partition p1 values less than (2010) (
subpartition s2
DATA DIRECTORY = '/disk2/data'
INDEX DIRECTORY = '/disk2/idx',
subpartition s3
DATA DIRECTORY = '/disk3/data'
INDEX DIRECTORY = '/disk3/idx'
),
partition p2 values less than (2011) (
subpartition s4
DATA DIRECTORY = '/disk4/data'
INDEX DIRECTORY = '/disk4/idx',
subpartition s5
DATA DIRECTORY = '/disk5/data'
INDEX DIRECTORY = '/disk5/idx'
)
);由于innodb存储引擎使用表空间自动的进行数据和索引的管理,因此会忽略DATA DIRECTORY 和INDEX DIRECTORY语法,因此上述分区表的数据和索引文件的分开放置对其是无效的。
分区中的null值
mysql数据库允许对null值做分区。MySQL数据库的分区总是把null值看做是小于任何一个非null值,这和MySQL数据库中处理null值得order by操作是一样的。因此对于不同的分区类型,MySQL数据库对于null值的处理也是不相同的。
1、对于range分区,如果向分区中插入null值,则MySQL数据库会将该值放入最左边的分区,另外注意的是如果删除最左边的分区,则会删除该分区的记录包括null值的记录
2、list分区下要使用null值,则必须显示地指出哪个分区中放入null值,否则会报错。3、hash和key分区对于null的处理方式和range分区、list分区不一样。任何分区的函数都会将含有null值得记录返回为0
create table t(
int a,
int b
)engine=innodb
partition by list (b) (
partition p0 values in (1,3,5,7,9,null),
partition p1 values in (0,2,4,6,8)
);在表和分区间交换数据
MySQL5.6开始支持alter table
table_nameexchange partitionpartition_namewith tabletable_name的语法。该语法允许分区或子分区中的数据与另一个非分区的表中的数据进行交换。如果表中的数据为空,那么相当于将分区中的数据移动到非分区表中。若分区表中的数据为空,则相当于将外部表中的数据导入到分区中。
要使用这个语法要满足以下条件:
1、要交换的表必须和分区表有相同的表结构,但是要交换的表不能含有分区
2、在非分区表中的数据必须在交换的分区定义内
3、被交换的表中不能含有外键或者其他的表含有对该表的外键引用
4、用户除了需要alter,insert,create权限外,还需要有drop权限
另外,有两个小细节需要注意:
1、使用该语句时不会触发交换表和被交换表上的触发器
2、auto_increment列将被重置
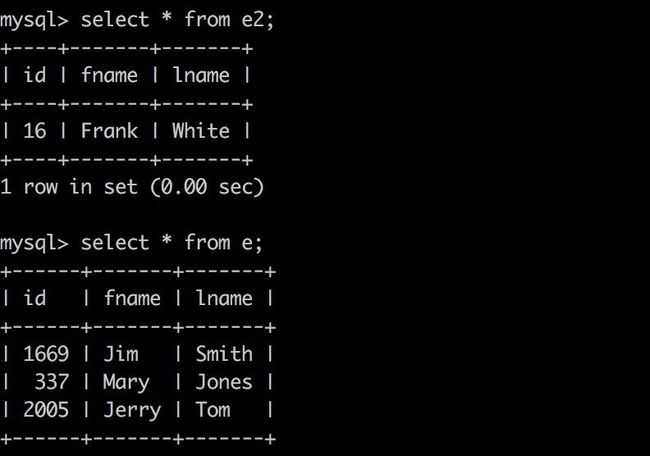
create table e(
id int not null,
fname varchar(30),
lname varchar(30)
)engine=innodb
partition by range (id) (
partition p0 values less than (50),
partition p1 values less than (100),
partition p2 values less than (150),
partition p3 values less than maxvalue
);
--- 插入数据
insert into e values
(1669, 'Jim', 'Smith'),
(337, 'Mary', 'Jones'),
(16, 'Frank', 'White'),
(2005, 'Jerry', 'Tom');
--- 创建e2表,复制e表结构,并清除partition
create table e2 like e;
alter table e2 remove partitioning;
--- 交换数据
alter table e exchange partition p0 with table e2;备注:一个分区只能交换到一个外部物理表中,不能将多个分区交换到同一个表。