高速存储器
更好的阅读体验
双端口存储器
双端口处理器的逻辑结构
1、一个存储器具有两组相互独立的读写控制电路。
2、两个端口具有独立的数据线、读写线、控制线。
3、两个端口可对存储器中任何位置上的数据进行独立的存取操作

双端口处理器的读写
无冲突读写
当两个端口的地址不同时,在两个端口上进行读写操作一定不会发生冲突
有冲突读写
两个端口同时读写一个地址时便可能发生冲突,这是我们通过设置一个BUSY标志来解决冲突
多模块交叉存储器
存储器的模块化组织
多体并行存储器也能解决cpu速度与存储器速度不匹配的问题
这里存取我们都考虑的是存取连续空间里的数据,因为我们通常的数据、代码、指令还有数组等这些东西,都是在连续的地址空间里进行存储的,也就是说大部分情况我们访存都是访问的连续地址
顺序存储
假如我们现在要访问一段连续地址(00000~00100),我们访问00000后需要等待T(存储器的存取周期)后才能进行下一次访问00001
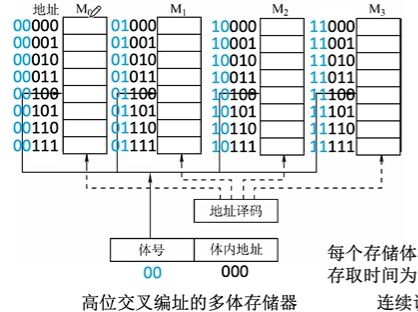
所以我们需要的总时间就如下:
5T
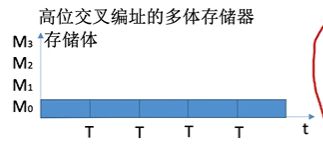
交叉存储
而交叉存储时,我们访问一段连续地址,当我们访问00000之后,00000所在存储体进入恢复阶段,我们可以接着访问00001,因为他们不在一个存储体中,而访问玩00001后,我们可以直接访问00010,这样前两个存储题都进行了恢复,所以通过这种交叉存储可以实现流水线式的并行工作

所以低位交叉存储的时间如下:
这里我们假设T=4r,T为存取周期,r为cpu取数的时间,也就是说,当我们访问完最后一个存储体后,第一个存储体就又恢复好了,我们就可以接着对第一个存储体进行访问了,
读取n个字所需的时间为
t = T + (n - 1)r
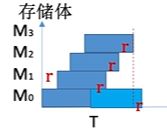
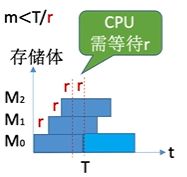
低位交叉存储中我们需要设计多少个存储体合适呢?
我们应该保证存储体个数m >= T / r,这是什么原因呢?
我们可以这样考虑,当T / r表示一个存储体从访问开始到下次再能访问需要有几个存储体可以
当存储体个数比较少时,cpu访问完所有存储体后,第二次访问第一次访问的存储体,这时这个存储体还没有恢复好,cpu需要等待其恢复好,才能进行访问,而当m个数比较多时,cpu还没有再次访问到第一次访问的存储体,他就已经回复好了,这是存储体就需要等待cpu
所以最好的状态是cpu刚好访问一遍存储体,最初访问的存储体刚刚恢复好,这样既没有产能过剩也没有有人偷懒的情况


Cache
Cache概述
Cache的功能
1、Cache是为了解决CPU与主存之间速度不匹配的一项技术
2、介于CPU和主存之间的一种小容量的高速缓冲器
3、基于局部性原理
4、全部功能由硬件实现,对程序员透明
Cache的基本原理
CPU与Cache之间的数据交换是以字为单位的,而Cache和主存之间的数据交换是以块为单位的。一个块是由若干字组成的。当CPU需要读取内存中的一个字时,就会发出这个字的内存地址到Cache和主存。此时Cache控制逻辑依据地址判断此字目前是否在Caxhe中。若在,则此字立刻传送给CPU若不在,则用主存读周期读出送入CPU,并且不含有这个字的块送入Cache。

Cache命中率
h表示Cache命中率,Nc表示Cache存取次数,Nm表示主存完成的存取次数,
h = Nc / (Nc + Nm)
Cache平均访问时间
tm未命时主存的访问时间,tc命中时Cache的访问时间
t = (1 - h)tm + h*tc
Caxhe的访问效率

主存与Cache的映射
主存与Cache的映射方式共有三种:全相联映射、直接映射、组相联映射,下面依次介绍这三种
全相联映射
主存中的任意块可以放在Cache中的任意行中
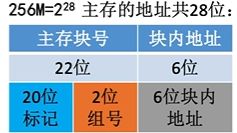
假设计算机的主存地址空间为256MB,按字节编址,其中Cache有8行,行长为64B

Cache与主存之间的信息交换是以块为单位的

所以我们需要有效位来指明Cache中的数据是否有效,然后需要标记为指明当前Cache中存储的信息是主存中哪个地址的信息。
CPU如何访存呢?首先,拿出要访问主存的地址的前22位和Cache中的所有块一一对比,并检查是否命中,若命中则根据低6位在每块中查找,若未命中则在主存中进行访存

直接映射
每个主存块只能放在Cache的固定位置
没有全相联映射灵活,而且Cache中空间利用很不充分
![]()

我们可以优化主存块号这一项,因为主存快号末尾3位就直接指示了该地址在Cache中的存放位置,所以我们就没有必要再存储

组相联映射
每一个主存块可以被放在特定Cache组的任意位置

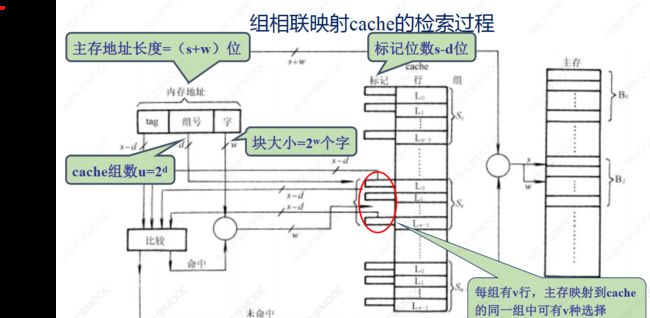
Cache的替换
Cache的工作原理是使其保存新的数据,这样当Cache满了或则我们的旧数据占据了新数据的Cache位时这时就会需要替换策略
而直接映射是不需要替换策略的,因为直接映射,每个内存块能在Cache中存放的位置固定的
常见的替换算法共三种1、最不经常使用(LFU)、2、近期最少使用(LRU)3、随机替换
最不经常使用LFU
算法思想:我们为每一个Cache块分配一个计数器,用于记录当前Cache块被访问过几次,d当Cache满了之后,我们挑选出计数器最小的进行替换。这种替换算法看似很科学,但是却忽略了很重的时间局部性原理,因为我们是从全局考虑的,我们可以思考这种情况,曾经我们经常访问的数据,未来并不一定经常访问,当我们之前一直访问一个内存块,这时这个内存块的计数器会变的很大,但是我们后来不再使用这个内存块,但是由于这个内存块的计数器很大,几乎不会被替换出来,这就导致这个Cache块基本被浪费掉了
近期最少使用LRU
算法思想:将一段时间内访问次数最少的行换出,我们为每一个Cache块分配一个计数器,用于记录当前块多久没有被访问过,每次需要替换时将计数器最大Cache块替换出来
这种算法遵循了时间局部性原理,保护了刚拷贝到Cache中的新数据行,Cache的命中率比较高

我们也可以在Cache命中时,把当前计数器置为0,其余行加1
随机替换
算法思想:顾名思义就是当Cache满了之后随机把Cache中的一个块替换出来
Cache的写操作
Cache中保存的是主存数据的副本,当CPU对Cache中的数据进行修改时,我们怎么保证Cache中的数据副本和主存中的数据母本的一致性呢?这就是Cache写操作需要解决的问题
写回法
1、当CPU写入Cache命中时,只修改Cache中的内容而不立即写入主存,只有当这一行被替换时,才将Cache中的内容写回主存
2、未命中时,依然是先将主存中的内容调入Cache,然后再Cache中进行写操作,当这一行被替换时,才将Cache中的内容写回主存
3、这种方法可以有效减少访问主存的次数,但是存在数据不一致的风险,我们是现实时需要有一个脏位记录当前是否修改过
全写法
1、当cache写命中时,将同时写入cache和主存,较好地维护了主存与Cache数据的一致性
2、当擦车未命中时,只能直接向主存中进行写入,同时又有一个问题就是是否要将修改过的主存块放入Cache?可以放也可以不放
写一次法
?这里并不是很理解写一次法是什么
