【文末送书 - 数据分析之pandas篇④】- DataFrame数据合并

向阳花花花花 - 个人主页
迄今所有人生都大写着失败,但并不妨碍我继续向前
Python 数据分析专栏 正在火热更新中
文章目录
- 一、concat
- 二、append
- 三、merge
-
- 3.1 没有属性相同时
- 3.2 只有一个属性相同时
-
-
- 1.一对一合并
- 2.一对多合并
- 3.多对多合并
-
- 3.3 有多个属性相同时
- 3.4 merge连接模式
- 结语
- 文末送书
一、concat
pd.concat()函数可以沿着指定的轴将多个dataframe或者series拼接到一起,这一点和另一个常用的pd.merge()函数不同,pd.merge()函数只能实现两个表的拼接。
concat 默认是上下合并,下面讲解该函数的常用参数。
| 参数 | 作用 |
|---|---|
| axis | 控制轴,值为0为横轴,1为纵轴 |
| ignore_index | 忽略行索引,将行索引重置(0-N-1) |
| keys | 设置多层索引 |
| join | join=outer,相当于取并集,补NaN模式,是默认模式;join=inner,相当于取交集,只连接匹配的项 |
首先导入包:
import numpy as np
import pandas as pd
定义一个返回 dataframe 对象的函数:
def make_df(indexs,columns):
data = [[str(j)+str(i) for j in columns] for i in indexs]
df = pd.DataFrame(data=data,index=indexs,columns=columns)
return df
获取两个 dataframe 对象:
df1 = make_df([1,2],['A','B'])
df2 = make_df([3,4],['A','B'])
display(df1,df2)
展示 df1 和 df2 :

将 df1 和 df2 使用 concat 合并:
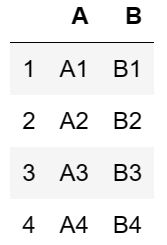
pd.concat([df1,df2])
得到如下结果:
使用 axis 控制合并方向:
pd.concat([df1,df2],axis=1)
得到如下结果:

使用 ignore_index 重置索引:
pd.concat([df1,df2],ignore_index=True)
运行结果如下:

使用 keys 设置多层索引:
pd.concat([df1,df2],keys=['one','two'])
结果如下:

为了演示
join参数,重新构建两个 dataframe 对象,演示结果如下。
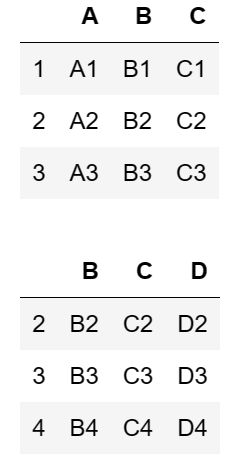
构建两个 dataframe 对象:
df1 = make_df(indexs=[1,2,3],columns=['A','B','C'])
df2 = make_df(indexs=[2,3,4],columns=['B','C','D'])
display(df1,df2)
展示 df1 和 df2 :
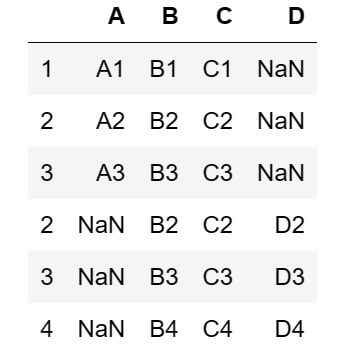
外连接:
pd.concat([df1,df2],join='outer',sort=True)
得到如下结果:
其中,sort = True 是为了解决如下警告而添加的:

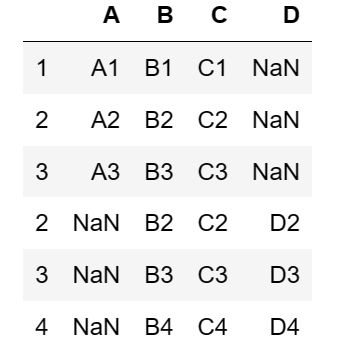
内连接:
pd.concat([df1,df2],join='inner')
结果如下:

二、append
pd.append() 函数专门用于在 dataframe 对象后
添加新的行,如果添加的列名不在 dataframe 对象中,将会被当作新的列进行添加。
还是使用上面的 df1 和 df2 对象,先查看一下:
display(df1,df2)

然后使用 append 追加:
df1.append(df2,sort=True)
结果如下:
三、merge
pd.merge()的使用需要分3种情况讨论:当需要合并的两个 dataframe 对象,没有属性相同时,只有一个属性相同时,有多个属性相同时。
3.1 没有属性相同时
如果两个 dataframe 对象没有相同的属性,则需要使用
left_on,right_on分别来指定2个表中不同列作为连接的字段。
首先构建两个 dataframe 对象:
df1 = pd.DataFrame({
'name':['张三','李四','王五'],
'id':[1,2,2],
'age':[22,33,44]
})
df2 = pd.DataFrame({
'sex':['男','女','男'],
'job':['Saler','CEO','Programmer']
})
display(df1,df2)
展示 df1 和 df2 结果如下:

可以看到两个 df 对象没有相同字段,下面使用 merge 连接:
df1.merge(df2,left_on='id',right_index=True)

注意:要合并的两个列,必须要有相同的值才能合并,否则报错,下面是错误示例:
df1.merge(df2,left_on='name',right_on='sex')
报错部分截图如下:

也可以使用行索引作为连接的字段:
left_index=True左表使用行索引作为连接字段,right_index=True右表使用行索引作为连接字段。
3.2 只有一个属性相同时
只有一个属性列相同时,也分为三种情况,分别是一对一合并,一对多合并,多对多合并。
1.一对一合并
当属性值在一个 dataframe 对象中不重复时,为一对一合并。
首先构建两个 dataframe 对象:
df1 = pd.DataFrame({
'name':['张三','李四','王五'],
'id':[1,2,3],
'age':[22,33,44]
})
df2 = pd.DataFrame({
'id':[2,3,4],
'sex':['男','女','男'],
'job':['Saler','CEO','Programmer']
})
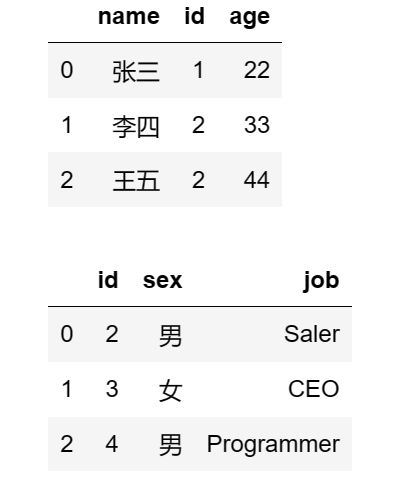
display(df1,df2)
查看 df1 和 df2 :

两个 dataframe 对象,只有一个相同的属性列 id ,并且两个 df 对象的 id 列都是唯一的,不重复。
下面使用 merge 合并:
df1.merge(df2)
结果如下:
2.一对多合并
当属性值在一个 dataframe 对象中有两个或以上相同值时,为一对多合并。
重新构建两个 dataframe 对象:
df3 = pd.DataFrame({
'name':['张三','李四','王五'],
'id':[1,2,2],
'age':[22,33,44]
})
df4 = pd.DataFrame({
'id':[2,3,4],
'sex':['男','女','男'],
'job':['Saler','CEO','Programmer']
})
display(df3,df4)
查看 df3 和 df4 :
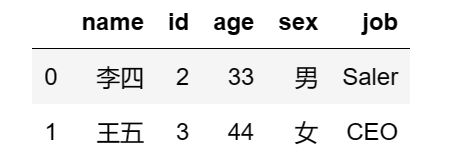
可以看到,两个 dataframe 对象,只有一个相同的属性列 id,并且只有 df3 的 id 有重复值。
下面使用 merge 合并:
df3.merge(df4)
得到如下结果:
3.多对多合并
两个 dataframe 对象同一个属性都有两个或以上相同值,为多对多合并。
重新构建两个 dataframe 对象:
df5 = pd.DataFrame({
'name':['张三','李四','王五'],
'id':[1,2,2],
'age':[22,33,44]
})
df6 = pd.DataFrame({
'id':[2,2,4],
'sex':['男','女','男'],
'job':['Saler','CEO','Programmer']
})
display(df5,df6)
查看 df5 和 df6 :

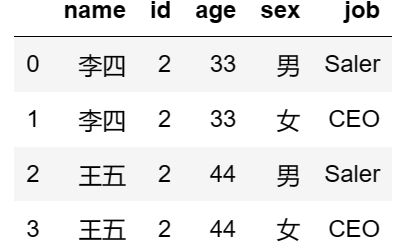
可以看到,两个 dataframe 对象,只有一个相同的属性列 id,并且 df5 和 df6 的 id 均有重复值。
下面使用 merge 合并:
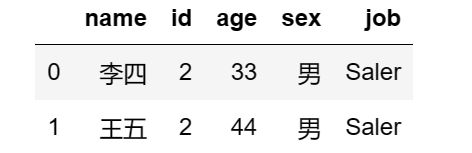
df5.merge(df6)
得到如下结果:
3.3 有多个属性相同时
如果不止一个属性相同,那么merge合并,只有多个属性值相同才能合并,否则报错;
此时需要使用参数on指定一个属性作为连接的字段。
重新构建两个 dataframe 对象:
df1 = pd.DataFrame({
'name':['张三','李四','王五'],
'id':[1,2,2],
'age':[22,33,44]
})
df2 = pd.DataFrame({
'id':[2,3,4],
'age':[2,3,4],
'job':['Saler','CEO','Programmer']
})
display(df1,df2)
查看 df1 和 df2:

可以看到,两个 df 对象有两个相同的列 id 和 age,如果我们直接合并:
df1.merge(df2)
会报如下错误(只截取部分):

此时,需要使用 on 参数指定连接的属性,这里指定 id 为连接属性:
df1.merge(df2,on='id')
查看结果:

因为
age字段重复了,所以 pandas 自动给 age 用_x_y的形式区分开来了,我们可以通过suffixes属性指定重复时的后缀名。
df1.merge(df2,on='id',suffixes=['_1','_2'])
结果如下:

3.4 merge连接模式
merge 连接模式类似于关系型数据库表的连接方式,包括内连接(交、how =
inner)、外连接(并,how = outer)、左外连接(how =left)、右外连接(how =right)。通过how属性可以指定连接模式,默认是外连接。
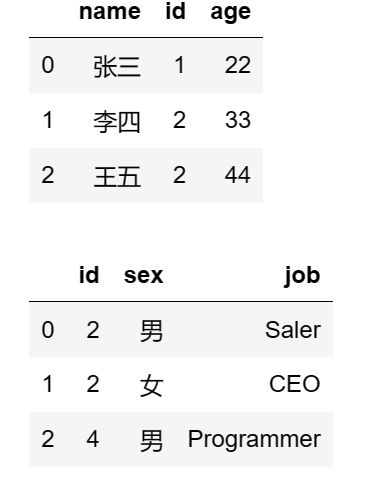
首先构建两个 dataframe 对象:
df5 = pd.DataFrame({
'name':['张三','李四','王五'],
'id':[1,2,2],
'age':[22,33,44]
})
df6 = pd.DataFrame({
'id':[2,2,4],
'sex':['男','女','男'],
'job':['Saler','CEO','Programmer']
})
display(df5,df6)
查看 df5 和 df6 :
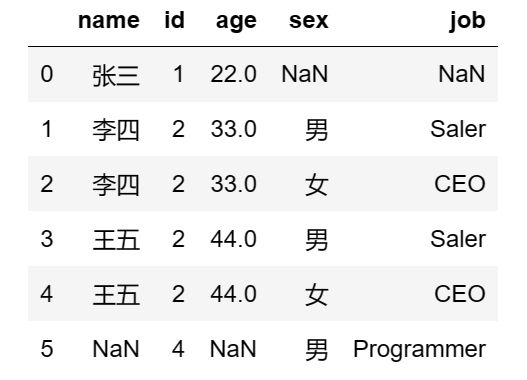
外连接:
df5.merge(df6,how='outer')
内连接:
df5.merge(df6,how='inner')
左外连接:
df5.merge(df6,how='left')
右外连接:
df5.merge(df6,how='right')
由于篇幅原因,这里不再演示每一个的结果,大家可以自己动手实践。
结语
本文主要带大家了解 pandas 中的数据合并3个函数,在后面的学习中会经常使用到。

您的支持是我创作的动力

希望我的文章能成为您的有用参考

我会继续改进和分享更好的内容
如果文中有些地方不清楚的话,欢迎联系我,我会给大家提供思路及解答。
| 文章直达 | 链接 |
|---|---|
| 上期回顾 | 【数据分析 - 基础入门之pandas篇③】- pandas数据结构——DataFrame |
| 下期预告 | 【数据分析 - 基础入门之pandas篇⑤】- pandas 数据清洗 |
文末送书
这是博主第一次开展送书活动,是和出版社谈了好久才谈成的给予粉丝的福利。
《Python从入门到精通》(第三版)是“软件开发视频大讲堂”丛书中的三剑客之一,代码基于Python 3.11,涵盖语言新特性,如:match…case语句、类型联合运算符、异步编程等。
本书配套了41小时同步微课视频,让学习更轻松);127个实例,随学随练;还有32个“实践与练习”,可以帮助我们巩固所学技能;还有Python六大热门应用方向,每个方向都在剖析技术储备之后设计并实现对应的热门项目,具体包括游戏开发与项目、爬虫开发与项目、数据可视化与项目、Web开发与项目、Python自动化办公、人工智能初探,可使读者将所学的Python基础知识与当前的Python开发热点无缝对接,成就Python开发无限可能;更有在线开发资源库,随查随用,可以快速提升编程水平和解决实际问题的能力。

京东购买链接:点我去往京东购买
- 本次送书一本
- 活动时间:截止到2023年7月25日
- 参与方式:关注博主、点赞、收藏并评论 “
人生苦短,我用Python”- 抽奖方式:利用程序产生随机数,对应哪条评论即为中奖
- 如何查看自己是否获奖:
如果获奖我会私信你们哟,记得关注我,不然中奖了联系不上!