堆排序+TopK问题

本期带大家学习堆排序+TopK问题
1、堆排序
堆排序,是根据堆的结构而设计出的一种排序算法,其时间复杂度:O(N * logN),空间复杂度:O(1)。
堆排序的前提是需要 构建一个堆,而建堆有两种方法:
向上调整建堆
向上调整算法(Upward Heapify)用于在堆中插入新元素后,调整堆的结构,以满足堆的性质


那么时间复杂度是多少呢
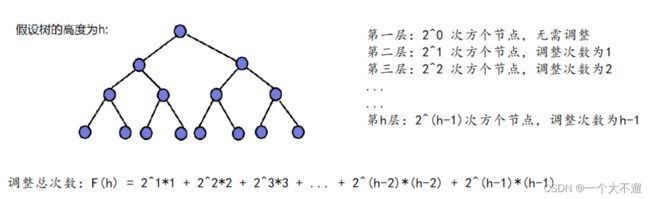
对于向上调整建堆,在每一层中都需要进行调整操作。假设二叉树总共有 h 层,除了第一层外,其他层的节点数是递增
的,最后一层的节点数为 2^(h-1) * (h-1)。经过计算和简化,可以得出最后一层节点数为 2^h * (h-1)/2。
假设二叉树的总节点数为 N,如果假设每一层都是满的,那么每层节点数会形成一个等比数列:2^0, 2^1, 2^2, … , 2^(h-1)。
通过等比数列求和,可以得出二叉树的总节点数为 2^h - 1。由此可以推导出二叉树的高度 h 与节点数 N 之间的关系为 2^h - 1 = N。
将式子 2^h * (h-1)/2 进行转换,可以得到 (N+1)(logN-1)/2 的形式。在时间复杂度分析中,省去常数项和除数,可以得出向
上调整算法的时间复杂度为 O(N * logN)。
综上所述,向上调整建堆的时间复杂度为 O(N * logN),其中 N 是二叉树的节点数。
向下调整建堆
向下调整建堆的话需要保证左右子树都是堆
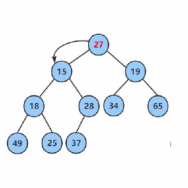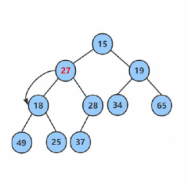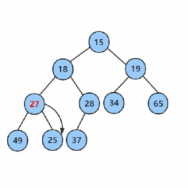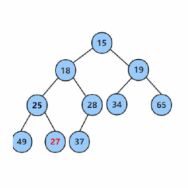

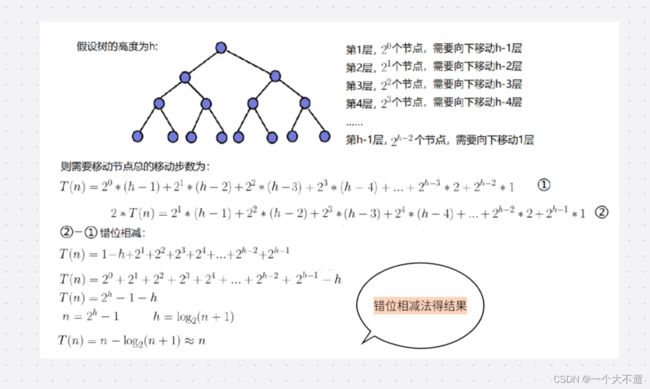
所以我们可以得知向下调整建堆的时间复杂度是O(n)
然而向上调整建堆和向下调整建堆的时间复杂度不一样
所以我们选择最佳时间复杂度进行建堆
选择大堆还是小堆
比如,我们现在实现降序排列
那我们是选择建立小堆还是建立大堆??
我们假设降序的话我们选择建立大堆
那我们堆顶的元素就是最大的,那他的位置就保持不动
去选择次大的元素
但是次大的元素是在左右子树当中
假设我们把剩下的数据看作堆的话,那么堆的关系就全乱了,所以我们排除降序建立大堆’
那我们选择降序建立小堆,那么堆顶的元素就是最小的,我们这时候将堆顶的元素和堆当中元素进行交换
然后堆中最小的元素就放到了最后,然后堆顶的元素在进行向下调整,循环,这样子我们就可以得到降序的数据
// 交换
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
// 向下调整
void AdjustDown(int* a, int sz, int parent)
{
int child = 2 * parent + 1;
// 建小堆
while (child < sz)
{
if (child + 1 < sz && a[child + 1] < a[child])
{
child++;
}
// 判断孩子是否小于父亲
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, int sz)
{
// 建堆
for (int i = (sz - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, sz, i);
}
// 此刻堆已经建好了
// 排升序,已经建了大堆,就需要调整元素
int end = sz - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
end--;
}
}
void TestHeap1()
{
int array[] = { 27, 15, 19, 18, 28, 34, 65, 49, 25, 37 };
HeapSort(array, sizeof(array) / sizeof(int));
for (int i = 0; i < sizeof(array) / sizeof(int); ++i)
{
printf("%d ", array[i]);
}
printf("\n");
}
int main()
{
TestHeap1();
}
2、TopK问题
对于TopK问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能数据都不能一下子全部加载到内存中)。
对于TopK问题的话,核心思想就是建立一个K个数据的堆
比如我们需要100个最大的数据
我们可以建立一个100个数据的小堆
然后我们从先读取前100个数据,然后再用向下调整建堆
然后再读取剩下的数据,假设读取的数据比我的堆顶的数据还要小,那么就不进来
如果比堆顶的数据要大的话,那么就把堆顶数据换掉,在使用向下调整算法调整堆
直到数据被读取完,那么就前100大的数据就是堆当中的了
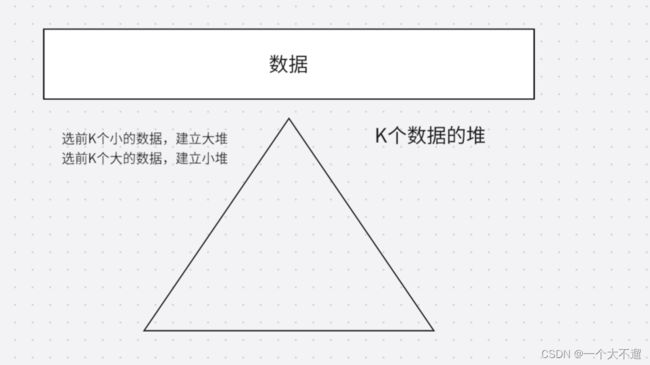
建小堆的时间复杂度为:O(k),遍历选数的时间复杂度为:O(N - k) * logk。那么总体就是 k + (N - k) * logk,化简一下就为:O(N * logk)。
而空间复杂度由于建了 k 个数的堆,就是O(k)
这里选择读取文件来实现TopK问题
void CreateNDate()
{
int n = 10000;
srand(time(0));
const char* file = "data.txt";
FILE* fp = fopen(file,"w");
if (fp == NULL)
{
perror("fopen error");
return;
}
for (int i = 0; i < 10000; i++)
{
fprintf(fp, "%d\n", rand() % 10000);
}
fclose(fp);
}
//TopK问题的解决办法是建立一个有K个数据的堆
//然后再进行相关的操作
void TestTopK()
{
//CreateNDate();
int k = 10;
const char* file = "data.txt";
FILE* fp = fopen(file,"r");
if (fp == NULL)
{
perror("fopen error");
return;
}
int* topk = (int*)malloc(sizeof(int) * k);
for (int i = 0; i < k; i++)
{
fscanf(fp, "%d", &topk[i]);
}
//建小堆
for (int i = (k - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(topk, k, i);
}
while(!feof(fp))
{
int val = 0;
fscanf(fp, "%d", &val);
if (val > topk[0])
{
topk[0] = val;
AdjustDown(topk, k, 0);
}
}
printf("\n");
for (int i = 0; i < k; i++)
printf("%d ", topk[i]);
fclose(fp);
}
3、感谢与交流✅
如果大家通过本篇博客收获了,对堆排序+TopK问题有了新的了解的话
那么希望支持一下哦如果还有不明白的,疑惑的话,或者什么比较好的建议的话,可以发到评论区,
我们一起解决,共同进步 ❗️❗️❗️
最后谢谢大家❗️❗️❗️
