实时数据集成的完美搭档:CDC技术与Kafka集成的解决方案
目录
一、实时数据同步
二、可靠的数据传输
三、灵活的数据处理
四、解耦数据系统
五、主流免费CDC工具介绍
六、Flink CDC安装使用步骤:
七、ETL CDC安装使用步骤
八、写在最后
一、实时数据同步
随着企业数据不断增长,如何高效地捕获、同步和处理数据成为了业务发展的关键。在这个数字化时代,CDC技术与Kafka集成为企业提供了一种无缝的数据管理方案,为数据的流动和实时处理打开了全新的大门。
CDC技术与Kafka集成能够实现快速、可靠的实时数据同步。CDC技术可以捕获数据库事务日志中的数据变更,并将其转化为可靠的数据流。这些数据流通过Kafka的高吞吐量消息队列进行传输,确保数据的实时性和一致性。无论是从源数据库到目标数据库的同步,还是跨不同数据存储系统的数据传输,CDC技术与Kafka集成提供了高效且无缝的解决方案。
二、可靠的数据传输
Kafka作为一个分布式、可扩展的消息队列系统,提供了高度可靠的数据传输机制。借助Kafka的持久性存储和数据复制机制,数据不会丢失或损坏。即使在高并发的情况下,Kafka集成能够保证数据的完整性和可靠性。这为企业提供了强大的数据传输基础,确保数据在各个环节的安全传输。
三、灵活的数据处理
CDC技术与Kafka集成不仅提供了实时数据同步,还为企业提供了灵活的数据处理能力。Kafka的消息队列和流处理特性使得企业可以在数据传输的同时进行实时的数据处理和分析。借助Kafka的消费者应用程序,企业可以对数据流进行转换、过滤、聚合等操作,实现实时数据的清洗、加工和分析。这种实时数据处理能力为企业提供了即时的洞察力,帮助其做出快速而准确的决策。
四、解耦数据系统
CDC技术与Kafka集成还能帮助企业解耦数据系统。通过将CDC技术与Kafka作为中间层,不同的数据源和目标系统可以独立操作,彼此之间解除了紧耦合的依赖关系。这种解耦带来了极大的灵活性,使得企业能够更加容易地添加、移除或升级数据源和目标系统,而无需对整个数据流程进行重构。
CDC技术与Kafka集成为企业带来了数据管理的全新体验。它提供了高效、可靠的数据同步和实时处理,帮助企业实现数据驱动的成功。无论是数据同步、实时处理还是数据系统的解耦,CDC技术与Kafka集成为企业提供了强大而灵活的解决方案。
五、主流免费CDC工具介绍
介绍两款能够快速且免费实现CDC技术与Kafka集成的主流工具:Flink CDC和ETLCloud CDC。
测试前的环境准备:JDK8以上、Mysql数据库(开启BinLog日志)、kafka
六、Flink CDC安装使用步骤:
下载安装包
进入Flink官网,下载1.13.3版本安装包 flink-1.13.3-bin-scala_2.11.tgz。(Flink1.13.3支持flink cdc2.x版本,为兼容flink cdc)
解压
在服务器上创建安装目录/home/flink,将 flink 安装包放在该目录下,并执行解压命令,解压至当前目录。tar -zxvf flink-1.13.3-bin-scala_2.11.tgz
启动
进入解压后的flink/lib目录,上传mysql和sql-connector驱动包。

进入flink/bin目录,执行启动命令:./start-cluster.sh

进入Flink可视化界面查看http://ip:8081

测试
下面我们来新建一个maven工程做CDC数据监听的同步测试。
POM依赖
<dependency>
<groupId>com.ververicagroupId>
<artifactId>flink-connector-mysql-cdcartifactId>
<version>2.0.0version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>1.12.0version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_2.12artifactId>
<version>1.12.0version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-clients_2.12artifactId>
<version>1.12.0version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.49version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-planner-blink_2.12artifactId>
<version>1.12.0version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.75version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.11artifactId>
<version>1.12.0version>
dependency>
新建Flink_CDC2Kafka类
import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
public class Flink_CDC2Kafka {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1 设置 CK&状态后端
//略
//2.通过 FlinkCDC 构建 SourceFunction 并读取数据
DebeziumSourceFunction
.hostname("ip") //数据库IP
.port(3306) //数据库端口
.username("admin") //数据库用户名
.password("pass") //数据库密码
.databaseList("test") //这个注释,就是多库同步
.tableList("test.admin") //这个注释,就是多表同步
.deserializer(new CustomerDeserialization()) //这里需要自定义序列化格式
// .deserializer(new StringDebeziumDeserializationSchema()) //默认是这个序列化格式
.startupOptions(StartupOptions.latest())
.build();
DataStreamSource
//3.打印数据并将数据写入 Kafka
streamSource.print();
String sinkTopic = "test";
streamSource.addSink(getKafkaProducer("ip:9092",sinkTopic));
//4.启动任务
env.execute("FlinkCDC");
}
//kafka 生产者
public static FlinkKafkaProducer
return new FlinkKafkaProducer
new SimpleStringSchema());
}
}
自定义序列化类
import com.alibaba.fastjson.JSONObject;
import com.ververica.cdc.debezium.DebeziumDeserializationSchema;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import java.util.ArrayList;
import java.util.List;
public class CustomerDeserialization implements DebeziumDeserializationSchema
@Override
public void deserialize(SourceRecord sourceRecord, Collector
//1.创建 JSON 对象用于存储最终数据
JSONObject result = new JSONObject();
//2.获取库名&表名放入 source
String topic = sourceRecord.topic();
String[] fields = topic.split("\\.");
String database = fields[1];
String tableName = fields[2];
JSONObject source = new JSONObject();
source.put("database",database);
source.put("table",tableName);
Struct value = (Struct) sourceRecord.value();
//3.获取"before"数据
Struct before = value.getStruct("before");
JSONObject beforeJson = new JSONObject();
if (before != null) {
Schema beforeSchema = before.schema();
List
for (Field field : beforeFields) {
Object beforeValue = before.get(field);
beforeJson.put(field.name(), beforeValue);
}
}
//4.获取"after"数据
Struct after = value.getStruct("after");
JSONObject afterJson = new JSONObject();
if (after != null) {
Schema afterSchema = after.schema();
List
for (Field field : afterFields) {
Object afterValue = after.get(field);
afterJson.put(field.name(), afterValue);
}
}
//5.获取操作类型 CREATE UPDATE DELETE 进行符合 Debezium-op 的字母
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
String type = operation.toString().toLowerCase();
if ("insert".equals(type)) {
type = "c";
}
if ("update".equals(type)) {
type = "u";
}
if ("delete".equals(type)) {
type = "d";
}
if ("create".equals(type)) {
type = "c";
}
//6.将字段写入 JSON 对象
result.put("source", source);
result.put("before", beforeJson);
result.put("after", afterJson);
result.put("op", type);
//7.输出数据
collector.collect(result.toJSONString());
}
@Override
public TypeInformation
return BasicTypeInfo.STRING_TYPE_INFO;
}
}
开启CDC监听

Mysql中新增一条人员数据

控制台捕获到增量数据
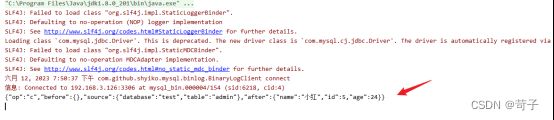
增量数据也成功推送到kafka中
至此通过Flink CDC监听数据库增量数据推送到kafka的过程已经完成,可以看到整个过程需要一些编码能力,对于业务人员的使用比较痛苦。
下面我们来介绍ETLCloud这款产品如何通过可视化配置,快速实现上述的场景内容。
七、ETL CDC安装使用步骤
下载安装包
ETLCloud提供了一键快捷部署包,只需运行启动脚本即可完成安装产品部署。部署包下载可以登录ETLCloud官网自行下载。
安装
官网下载linux一键部署包,把一键部署包放到一个目录下解压并进入该目录。
对脚本文件进行赋权
chmod +x restcloud_install.sh
执行脚本
./restcloud_install.sh

等待tomcat启动,当出现这个界面,则restcloud证明启动成功

数据源配置
新增MySql数据源信息

新增Kafka数据源信息

测试数据源

监听器配置
新增数据库监听器

监听器配置

接收端配置(数据传输类型选择kafka)

高级配置(默认参数)

启动监听

监听成功

测试
打开Navicat可视化工具新增并修改一条人员信息

实时数据中可以动态捕捉实时传输数据

Kafka中查看新增数据

Kafka中查看修改数据

八、写在最后
上面我们通过两个CDC工具均实现了实时数据同步到kafka的功能,但通过对比Flink CDC和ETLCloud CDC,可以看出ETLCloud CDC提供了可视化配置的方式,使配置过程更加简单快捷,不需要编码能力。而Flink CDC则需要进行编码,对于业务人员可能会有一定的学习成本。
无论选择哪种工具,都可以实现CDC技术与Kafka集成,实时捕获数据库的增量数据变化,提供了方便和高效的数据同步和传输方法。