OpenGauss操作 SQL语法详细总结:从入门到进阶
吐血总结3天3夜,全文6000余字,涵盖表操作、更新查询等基础操作,更包含连接查询、GROUP BY子句、聚集函数等进阶用法,如果有所帮助,点赞+收藏⭐持续更新,随时遗忘,随时查阅,提高学习效率!
一、高频操作
配置完OpenGauss,进入界面后,可以通过如下3条语句进入到数据库postgres:
su - omm —— 切换至omm操作系统用户环境
gs_om -t start —— 启动 gs_om -t status 检查
gsql -d postgres -p 26000 -r ——连接postgres数据库
注意如下语句皆要末尾带上英文分号(;)。
创建新用户—— create user 新用户名 with password '你的密码' ;
删除用户—— drop user 用户名 ;
创建数据库隶属某用户—— create database 数据库名 owner 用户名 ;
删除数据库—— drop database 数据库名 ;
切换数据库—— \c 数据库名 ;
退出数据库—— \q 数据库名 ;
创建模式—— create schema 模式名 ;
删除模式—— drop schema模式名 ;
创建表—— create table 表名(属性名 数据类型 约束条件,属性名 数据类型 约束条件, ......);
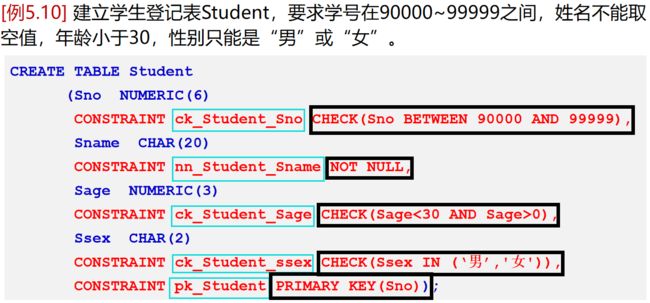
例:创建如下条件的Teacher表:

![]()
建表时创建约束——CREATE TABLE 表名(属性名 类型名 约束名,..........);
定义主码、外码和CHECK可用下图方式定义:

再举2个用CHECK约束的例子:
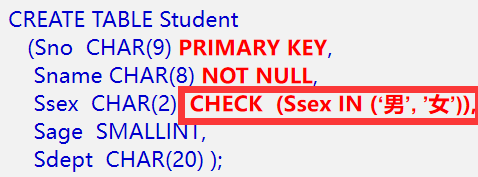

下图补充的是数据类型:

删除表—— drop table 表名;
删除某行数据—— delete from 表 where 条件;
(如:DELETE FROM SC WHERE Sno='10005';)
查询表数据—— select * from 表名;
查询表中特定字段数据—— select 字段名 from 表名; (ps:字段名可填多个)
查询全表结构—— \d+ 表名;
创建主码—— alter table 表名 add primary key(待定主码的属性名);
(如:将employees表的employee_id属性设为主码:ALTER TABLE employees ADD PRIMARY KEY(employee_id) )
删除主码—— alter table 表名 drop primary key(主码属性名);
创建外码—— alter table A表 add foreign key (A表外码属性名) references B表名;
![]()
大家可以好好通过上面的例子揣摩
删除外码—— alter table 表名 drop constraint 外码名
非空约束—— alter table 表名 modify 字段名 not null;
唯一性约束—— ALTER TABLE 表名 ADD UNIQUE (属性名);

(重点)完整性约束命名子句:作用是为每个约束赋予一个名字,方便后期的修改和删除:

下面举一个例子,蓝框内是约束名,黑框内是约束条件:
下图补充一个外码的约束命名语句:
![]()
修改表中完整性限制:ALTER TABLE 表名 drop/add CONSTRAINT 约束名

查询某表上的约束—— \d+ 表名 (如:\d+ order)
(常用)批量插入数据—— insert into 表名 values(数据组1),(数据组2), ......;
下面举个例子:
![]()
![]()
修改数据行—— update 表名 set 字段=表达式后 where 条件
(例:UPDATE Student SET Sage=22 WHERE sno="12314")
删除数据行—— delete from 表名 where 条件
(例: DELETE FROM project.S WHERE SNO='S1')
为某属性创建索引—— CREATE INDEX 索引名 ON 表名(属性名)
(example:CREATE INDEX idx_name ON customers(name))
删除索引—— DROP INDEX 索引名
创建视图—— create view 视图名 as select 字段名,字段名... from 表名 where 条件
(example:CREATE VIEW view AS SELECT SNO,PNO,QTY FROM SPJ WHERE JNO=(SELECT JNO FROM J WHERE JNAME='三星'));
删除视图—— drop view 视图名
修改视图元素—— update 视图名 set 待修改元素 where 条件
(example:UPDATE view SET sname='刘明' where Sno='201314';)
二、操作补充
1、数据库操作
修改数据库名—— ALTER DATABASE 旧数据库名 RENAME TO 新库名(ps:在postgres初始数据库下输入)(如:ALTER DATABASE hu RENAME TO hu1S)
查询角色—— SELECT * FROM PG_ROLES
查询所有已有的数据库—— \l
2、模式操作
创建模式—— CREATE SCHEMA 模式名 AUTHORIZATION 用户名
设置路径—— SET search_path TO 用户名
更改模式名—— ALTER SCHEMA 旧模式名 RENAME TO 新模式名;(在创建模式的数据库下输入)
3、表操作
查看表基本结构—— \d 表名
(如:\d order)
增加列(字段)—— ALTER TABLE 表名 ADD 列名 列类型
(如:ALTER TABLE locations ADD s_entrance DATE;)
删除列(字段)—— ALTER TABLE 表名 DROP 字段名;
(如:ALTER TABLE locations DROP s_entrance;)
特殊导入csv数据—— \copy 模式名.表名 FROM '/home/omm/文件名.csv'CSV
(如:\copy Sales.customers FROM '/home/omm/customers.csv'CSV )
正常导入csv数据—— \copy 模式名.表名 FROM '/home/omm/文件名.csv' WITH (delimiter',',IGNORE_EXTRA_DATA 'on');
(如 \copy Sales.countries FROM '/home/omm/countries.csv' WITH (delimiter',',IGNORE_EXTRA_DATA 'on'); )
4、索引
为某属性创建索引—— CREATE
(example:CREATE INDEX idx_name ON customers(name))(
更改索引名—— ALTER INDEX 旧索引名 RENAME TO 新索引名
删除索引—— DROP INDEX 索引名
5、数据查询

选择全部属性生成查询表—— SELECT * FROM 表名;
选择部分属性生成查询表—— SELECT
(SELECT JNAME,CITY FROM project.J;)(
改用别名输出列标题—— SELECT 原属性名 新属性名,.... FROM 表名;

其中2019-Sage是经过计算的值,可见所选的列可以是经过计算的值

选择符合条件的元组—— SELECT 属性 FROM 表名 WHERE 条件;
(example:SELECT name FROM Student WHERE Grade>90;)
选择范围内的元组—— SELECT 属性 FROM 表名 WHERE 属性名
(example:SELECT name FROM Student WHERE Grade BETWEEN 80 AND 90;)
选择集合类的元组—— SELECT 属性 FROM 表名 WHERE 属性名
(example:SELECT name,year FROM Student WHERE Sdept IN('CS','MA','IS'));
选择字符匹配的元组—— SELECT 属性 FROM 表名 WHERE 属性名


下划线_代表匹配单个字符,如果想查询待下划线_的内容,用换码字符:

涉及空值查询—— SELECT 属性 FROM 表名 WHERE 属性名 IS
多重条件查询—— SELECT 属性 FROM 表名 WHERE 属性名 AND 属性名 OR 属性名...;

排序查询—— SELECT 属性 FROM 表名 WHERE 条件 ORDER BY 属性名 DESC/ASC;
(example:SELECT * FROM Student WHERE Grade>90 ORDER BY Grade DESC);

(重点)聚集函数查询:

下图是2个简单的例子:


GROUP BY子句分组 ——细化聚集函数的作用对象,会对每一个分组分别统计个数:

上面的例子可以看到:共计有5门课,课程号是Cno,“GROUP BY Cno”说明是以课程号作为分组,分别统计选课的人数“COUNT(Sno)”输出,其中Sno是每位学生的学号。


特别要注意下面的陷阱:要先按照学号Sno进行分组,然后再对每名同学每门课的成绩求平均值,选择大于等于90分的输出。(有图是对所有成绩先取平均值,再对学号进行分组,是错误的)

等值连接查询——将两张表以某个属性值“拼接”在一起

自然连接—— 与等值连接不同的是,是以一个公共属性作为两张表拼接的公共属性。

自身连接—— 一张表与自身进行连接,需要用FIRST,SECOND之类的别名进行对应

外连接—— SELECT 表A.共同属性,属性..... FROM 表A 外连接类型 表B ON(连接条件)

关系到要将哪一侧的元组全部输出的

嵌套查询—— SELECT 属性A FROM 表A WHERE 属性B IN(SELECT 属性B FROM 表B WHERE 条件)

我的理解就是先从B表中,筛选出符合条件的属性B,然后再将属性B作为条件,作为从A表中筛选出属性A的条件。
要注意:子查询不能用ORDER BY子句,ORDER BY只能在主查询中使用。
只有当内层返回单值是才能使用比较运算符:

相关嵌套子查询——


带有ANY或ALL谓词的子查询——简而言之,ANY就是任意,ALL就是全部。如果比ANY还小,就是小于最大值,如果比ALL还小,就是小于最小值。如果比ANY还大,就是大于最小值,如果比ALL还大,就是大于最大值。
带有EXISTS谓词的子查询——


集合查询——

openGauss、oracle用到的差集关键词为MINUS,而不是EXCEPT


派生表查询——

5、创建视图
SELECT 待查字段,待查字段 FROM 视图名 WHERE 条件 ——查询视图
INSERT INTO 视图名 VALUES(字段,字段.....)——插入数据
(INSERT INTO IS_Student VALUES(‘201215129’,‘赵新’,20);)
6、更新查询
INSERT INTO 模式名.表名 VALUES(数据);
(example:INSERT INTO SPJ VALUES('S2','J6','P4',200);)
INSERT INTO 模式名.表名 VALUES(数据1,数据2,数据3.......);——批量插入
(example:INSERT INTO customer_t1(c_customer_sk, c_customer_id,c_first_name) VALUES (6885,'maps','Joes’), (4321, 'tpcds','Lily’),(9527,'world','James');)
——涉及到其它表更新的子查询
(example:UPDATE SC SET Grade=0 WHERE Sno IN (SELECT Sno FROM Student WHERE Sdept='CS');
——删除所有表内容
TRUNCATE TABLE table_name
8、数据库安全
ALTER USER jim CREATEROLE;————增加创建角色权限
ALTER ROLE 用户名 IDENTIFIED BY '新密码' REPLACE '旧密码';————修改密码
GRANT ALL PRIVILEGES TO 用户名————转移所有权限
GRANT USAGE ON SCHEMA 模式 TO 用户————转移模式的使用权限给用户
GRANT ALL PRIVILEGES ON 模式.表 TO 用户————转移表的所有权限给用户
GRANT select(字段名,字段名.......), ————转移查询权限
update(字段名)————转移更新权限
ON 模式.表名 TO 用户;
GRANT create,connect on database postgres TO joe
————把postgres的连接权限给joe同时把创建模式的权限也给予
WITH GRANT OPTION————有权将权限给其他用户
GRANT USAGE,CREATE ON SCHEMA 模式名 TO 角色名 ————把使用创建模式的权限给角色
GRANT 授权人用户 TO 被授权人用户 ————授权用户权限
WITH ADMIN OPTION; ————收回权限时不因权限的传播而失效
REVOKE 用户名A FROM 用户名B————从用户B中收回权限A
REVOKE ALL PRIVILEGES ON SCHEMA tpcds FROM 被收回方用户名——收回关于模式的权限
REVOKE USAGE,CREATE ON SCHEMA 模式名 FROM 用户名;
————从用户那里收回模式的使用和创建权
9、异常处理
主机名:ECS公网IP,用户名:如果是对ECS操作,使用root;
如果是对数据库操作,使用omm,或已创建的有相应权限的用户。
gs_om -t status --detail
CREATE TABLE project.J(JNO VARCHAR(10),JNAME VARCHAR(20),CITY VARCHAR(10));
ALTER DATABASE postgres SET session_timeout TO 0; ————将session超时置为