时间序列的季节性:3种模式及8种建模方法
分析和处理季节性是时间序列分析中的一个关键工作,在本文中我们将描述三种类型的季节性以及常见的8种建模方法。
什么是季节性?
季节性是构成时间序列的关键因素之一,是指在一段时间内以相似强度重复的系统运动。
季节变化可以由各种因素引起,例如天气、日历或经济条件。各种应用程序中都有这样的例子。由于假期和旅游的缘故,夏天的机票更贵。另一个例子是消费者支出,由于因为12月的假期而增加。
季节性是指某些时期的平均值与其他时期的平均值不同。这个问题导致该系列是非平稳的。这就是为什么在建立模型时分析季节性是很重要的。
3种模式
在时间序列中可以出现三种类型的季节模式。季节性可以是确定性的,也可以是随机的。在随机方面,季节模式可能是平稳的,也可能不是。
这些季节性并不是相互排斥的。时间序列可以同时具有确定性和随机季节性成分。
1、确定的季节性
具有确定性季节性的时间序列具有恒定的季节模式。它总是以一种可预测的方式出现,无论是在强度上还是在周期性上:
相似强度:在同一季节期间,季节+模式的水平保持不变;
不变周期性:波峰和波谷的位置不改变。也就是说季节模式每次重复之间的时间是恒定的。
比如说下面这个就是一个具有确定性季节性的合成月时间序列:
import numpy as np
period = 12
size = 120
beta1 = 0.3
beta2 = 0.6
sin1 = np.asarray([np.sin(2 * np.pi * i / 12) for i in np.arange(1, size + 1)])
cos1 = np.asarray([np.cos(2 * np.pi * i / 12) for i in np.arange(1, size + 1)])
xt = np.cumsum(np.random.normal(scale=0.1, size=size))
series_det = xt + beta1*sin1 + beta2*cos1 + np.random.normal(scale=0.1, size=size)

我们也可以用傅里叶级数来模拟季节性。傅里叶级数是不同周期的正弦和余弦波。如果季节性是确定性的,那么用傅里叶级数来描述是非常准确的。
2、随机平稳的季节性
beta1 = np.linspace(-.6, .3, num=size)
beta2 = np.linspace(.6, -.3, num=size)
sin1 = np.asarray([np.sin(2 * np.pi * i / 12) for i in np.arange(1, size + 1)])
cos1 = np.asarray([np.cos(2 * np.pi * i / 12) for i in np.arange(1, size + 1)])
xt = np.cumsum(np.random.normal(scale=0.1, size=size))
# synthetic series with stochastic seasonality
series_stoc = xt + beta1*sin1 + beta2*cos1 + np.random.normal(scale=0.1, size=size)
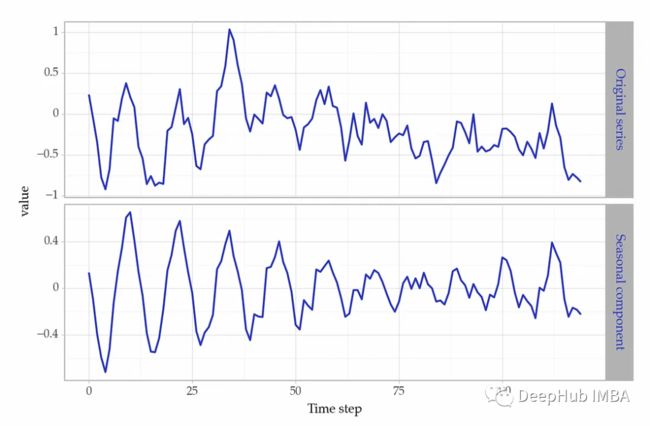
在连续的季节周期(如一年)中随机平稳的季节性演变。虽然强度难以预测,但周期性大致保持不变。
有了确定性的季节性,给定月份的预测不会随年份而改变。对于随机平稳季节性,最佳猜测取决于前一年同月的值。
3、随机非平稳季节性
季节模式会在几个季节期间发生显著变化,这种季节性的周期性也随着时间的推移而变化。这意味着波峰和波谷的位置不同。
这种季节性模式的例子出现在不同的领域。这些数据包括消费系列或工业生产数据。当时间序列具有综合季节性时,变化很难预测。
季节性时间序列的测试
可视化时间序列是一种检查季节模式的简单方法。但是可视化并不能系统的说明季节性的模式,所以就需要更系统的方法来描述时间序列的而季节性。
1、测量季节强度
我们可以根据以下方法量化季节模式的强度:
import pandas as pd
from statsmodels.tsa.api import STL
def seasonal_strength(series: pd.Series) -> float:
# time series decomposition
series_decomp = STL(series, period=period).fit()
# variance of residuals + seasonality
resid_seas_var = (series_decomp.resid + series_decomp.seasonal).var()
# variance of residuals
resid_var = series_decomp.resid.var()
# seasonal strength
result = 1 - (resid_var / resid_seas_var)
return result
这个函数估计季节性的强度,不管它是确定性的还是随机的。
# strong seasonality in the deterministic series
seasonal_strength(series_det)
# 0.93
# strong seasonality in the stochastic series
seasonal_strength(series_stoc)
# 0.91
如果该值高于0.64[2],则需要应用季节性差异过滤器。另一种检测季节性的方法是QS测试,它在季节性滞后时检查自相关性。
2、检测非平稳季节性
有一些统计检验是用来检验季节模式是否是非平稳的。
一个常见的例子是Canova-Hansen (CH)测试。其假设如下:
- H0(零假设):季节模式平稳(无季节单位根);
- H1:该系列包含一个季节性单位根
OCSB测试和HEGY测试是CH的两种替代方法。这些方法都可以在Python的pmdarima 库中找到。
from pmdarima.arima import nsdiffs
period = 12 # monthly data
nsdiffs(x=series_det, m=period, test='ch')
nsdiffs(x=series_det, m=period, test='ocsb')
nsdiffs(x=series_stoc, m=period, test='ch')
nsdiffs(x=series_stoc, m=period, test='ocsb')
函数nsdiffs返回使序列平稳所需的季节差步数。
3、相关性检测
还有其他专为季节数据设计的检测。例如,季节性肯德尔检验是一种非参数检验,用于检查季节性时间序列的单调趋势。
检测季节性模式
季节性指的是在一段时间内重复出现的模式。这是一个重要的变化来源,对建模很重要。

有很多种种处理季节性的方法,其中一些方法在建模之前去掉了季节成分。经季节调整的数据(时间序列减去季节成分)强调长期影响,如趋势或商业周期。而另外一些方法增加了额外的变量来捕捉季节性的周期性。
在讨论不同的方法之前,先创建一个时间序列并描述它的季节模式,我们还继续使用上面的代码
period = 12 # monthly series
size = 120
beta1 = np.linspace(-.6, .3, num=size)
beta2 = np.linspace(.6, -.3, num=size)
sin1 = np.asarray([np.sin(2 * np.pi * i / 12) for i in np.arange(1, size + 1)])
cos1 = np.asarray([np.cos(2 * np.pi * i / 12) for i in np.arange(1, size + 1)])
xt = np.cumsum(np.random.normal(scale=0.1, size=size))
yt = xt + beta1 * sin1 + beta2 * cos1 + np.random.normal(scale=0.1, size=size)
yt = pd.Series(yt)

然后通过强度来描述季节模式:
seasonal_strength(yt, period=12)
# 0.90
结果为0.90,表明季节性确实很强。该时间序列的自相关图如下图所示:

再使用我们上面介绍的Canova-Hansen检验来查看季节性单位根:
from pmdarima.arima import nsdiffs
nsdiffs(x=yt, m=period, test='ch')
# 0
结果为0,表示不存在季节单位根。也就是说季节模式是平稳的。
那么,我们该如何应对像这样的季节性模式呢?
季节性建模
1、虚拟变量
季节性虚拟变量是一组二元变量。它们表示一个观测值是否属于一个给定的时期(例如一月)。
下面是一个如何创建这些变量的例子:
from sktime.transformations.series.date import DateTimeFeatures
from sklearn.preprocessing import OneHotEncoder
monthly_feats = DateTimeFeatures(ts_freq='M',
keep_original_columns=False,
feature_scope='efficient')
datetime_feats = monthly_feats.fit_transform(yt)
datetime_feats = datetime_feats.drop('year', axis=1)
encoder = OneHotEncoder(drop='first', sparse=False)
encoded_feats = encoder.fit_transform(datetime_feats)
encoded_feats_df = pd.DataFrame(encoded_feats,
columns=encoder.get_feature_names_out(),
dtype=int)
这段代码产生如下数据。

在每个观察中获得有关季度和月份的信息(左侧表)。该信息存储在datetime_feats对象中。然后使用one-hot编码来创建虚拟变量(右侧表)。
如果季节性是确定的,那么季节虚拟变量是非常有效。因为确定的季节性种季节模式是固定的,也就是强度和周期性基本不变。并且我们还可以通过检验季节虚拟变量的系数来分析季节效应及其变化,这有利于模型的可解释性。
但是季节性虚拟变量的缺点也很明显,它假设不同的时期是独立的。比如1月份的观测结果与12月份的观测结果相关。虚拟变量对这种相关性视而不见。所以如果季节模式发生变化,虚拟变量就会产生很多问题。
2、傅里叶级数
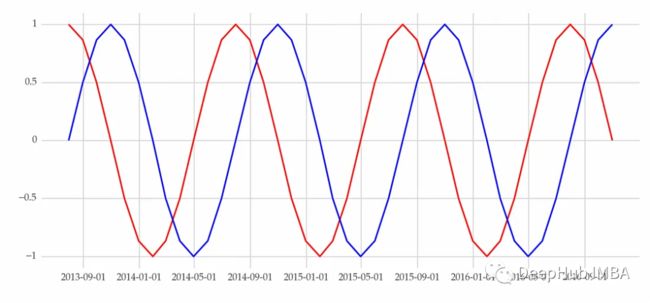
傅里叶级数是基于正弦和余弦波的周期性和确定性的变量。与季节性虚拟变量相反,这些三角函数将季节性建模为周期性模式,并且这种结构更能反映现实。
sktime中包含了很好的方法:
from sktime.transformations.series.fourier import FourierFeatures
fourier = FourierFeatures(sp_list=[12],
fourier_terms_list=[4],
keep_original_columns=False)
fourier_feats = fourier.fit_transform(yt)
这里需要指定两个主要参数:
- sp_list:将季节期间作为一个列表(例如,12个月的数据)
- fourier_terms_list:项的个数,指要包含的正弦和余弦级数的个数。这些都会影响到表示的平滑度。
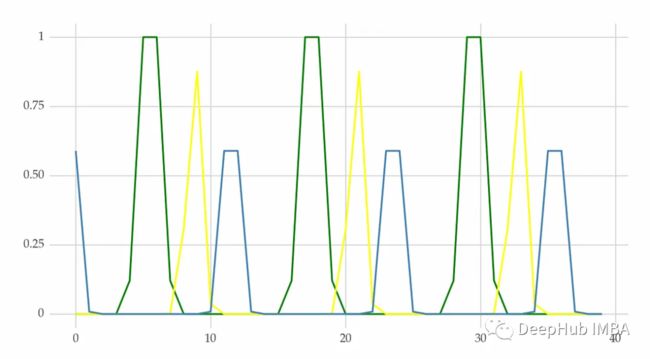
傅里叶级数是可以添加到模型中的解释变量。并且可以将这些特性与滞后特性结合起来。
3、径向基函数
径向基函数(RBF)是傅里叶级数的替代方法。它他用过创建重复的钟形曲线来模拟重复的图案。
在scikit-lego包中有一个RepeatingBasisFunction方法:
from sklego.preprocessing import RepeatingBasisFunction
rbf_encoder = RepeatingBasisFunction(n_periods=4,
column='month_of_year',
input_range=(1, 12),
remainder='drop',
width=0.25)
rbf_features = rbf_encoder.fit_transform(datetime_feats)
rbf_features_df = pd.DataFrame(rbf_features,
columns=[f'RBF{i}'
for i in range(rbf_features.shape[1])])
该方法最重要的三个参数如下:
- n_periods:要包含的基函数的个数
- input_range:列的输入范围。例如,在上面的例子中,我们使用(1,12),这是月份的范围;
- width:径向基函数的宽度,主要的作用是控制其平滑度
与傅里叶级数一样,RBF变量可以用作模型中的解释变量。
4、季节性自回归
自回归是大多数预测模型的基础。这个想法是使用最近的过去观察(滞后)来预测未来的值。这个概念可以扩展到季节性模型。季节性自回归模型包括同一季节的过去值作为预测因子。
SARIMA是一种流行的方法,它应用了这个想法:
import pmdarima as pm
model = pm.auto_arima(yt, m=12, trace=True)
model.summary()
# Best model: ARIMA(0,1,0)(1,0,0)[12]
利用季节滞后作为解释变量是模拟季节性的有效方法。但是在使用这种方法时,应该处理季节性单位根。因为非平稳的数据会产生很多问题。
5、添加额外变量
季节性虚拟变量或傅立叶级数等方法都可以捕捉到周期性模式。但是这些方法都是替代性的方法。
我们也可以通过添加额外变量的方式对季节性进行建模,例如温度或每个月的工作日数等外生变量来模拟季节性。

6、季节性差分
通过在建模之前从数据中删除季节性来处理季节性。这种方法叫做季节差分。
季节差异是取同一季节连续观测值之间的差异的过程。这种操作对于去除季节性单位根部特别有用。
可以使用diff方法进行季节差异:
from sklearn.model_selection import train_test_split
from sktime.forecasting.compose import make_reduction
from sklearn.linear_model import RidgeCV
train, test = train_test_split(yt, test_size=12, shuffle=False)
train_sdiff = train.diff(periods=12)[12:]
forecaster = make_reduction(estimator=RidgeCV(),
strategy='recursive',
window_length=3)
forecaster.fit(train_sdiff)
diff_pred = forecaster.predict(fh=list(range(1, 13)))
我们在差分序列上建立了Ridge回归模型。通过还原差值运算,可以得到原始尺度上的预报。
7、时间序列分解
还可以使用时间序列分解方法(如STL)去除季节性。
差分和分解的区别是什么?
差分和分解都用于从时间序列中去除季节性。但是转换后的数据的建模方式不同。
当应用差分时,模型使用差分数据。所以需要还原差分操作以获得原始尺度上的预测。
而使用基于分解的方法,需要两组预测。一个是季节性部分,另一个是季节性调整后的数据。最后的预测是各部分预测的总和。
下面是一个基于分解的方法如何工作的例子:
from statsmodels.tsa.api import STL
from sktime.forecasting.naive import NaiveForecaster
# fitting the seasonal decomposition method
series_decomp = STL(yt, period=period).fit()
# adjusting the data
seas_adj = yt - series_decomp.seasonal
# forecasting the non-seasonal part
forecaster = make_reduction(estimator=RidgeCV(),
strategy='recursive',
window_length=3)
forecaster.fit(seas_adj)
seas_adj_pred = forecaster.predict(fh=list(range(1, 13)))
# forecasting the seasonal part
seas_forecaster = NaiveForecaster(strategy='last', sp=12)
seas_forecaster.fit(series_decomp.seasonal)
seas_preds = seas_forecaster.predict(fh=list(range(1, 13)))
# combining the forecasts
preds = seas_adj_pred + seas_preds
在这个例子中,我们建立了一个Ridge 回归模型来预测经季节调整后的数据。然后将两个预测加在一起。
8、动态线性模型(DLM)
回归模型的参数通常是静态的。它们不随时间变化,或者是时不变的。DLM是线性回归的一种特殊情况。其主要特点是参数随时间而变化,而不是静态的。
dlm假定季节性时间序列的结构随季节而变化。因此合理的方法是建立具有时变参数的模型。随季节变化的参数。
参考文献[4]中的书的第15章提供了这种方法的一个简洁的R示例。他们使用时变的MARSS(多元自回归状态空间)方法来模拟季节性变化。
总结
时间序列建模并不是一项简单的任务,它需要考虑多个因素和技术。季节性的存在可以对时间序列数据的分析和预测产生重要影响。识别和理解季节性模式有助于揭示数据的周期性变化、制定季节性调整策略以及进行更准确的预测。时间序列建模往往需要结合经验和领域知识,同时灵活运用不同的技术和方法,以获得准确、可靠的模型和预测结果。
作者:Vitor Cerqueira
https://avoid.overfit.cn/post/89fc450f115643ad8ef53cd31712ce68
引用:
[1] Canova, F. and Hansen, Bruce E. (1995) “Are seasonal patterns constant over time? A test for seasonal stability”. Journal of Business & Economic Statistics, 13(3), pp. 237–252
[2] Wang, X, Smith, KA, Hyndman, RJ (2006) “Characteristic-based clustering for time series data”, Data Mining and Knowledge Discovery, 13(3), 335–364.
[3] Holmes, Elizabeth E., Mark D. Scheuerell, and E. J. Ward. “Applied time series analysis for fisheries and environmental data.” NOAA Fisheries, Northwest Fisheries Science Center, Seattle, WA (2020).
[4] Holmes, Elizabeth E., Mark D. Scheuerell, and E. J. Ward. “Applied time series analysis for fisheries and environmental data.” NOAA Fisheries, Northwest Fisheries Science Center, Seattle, WA (2020).