ToT: 利用大语言模型解决需要深思熟虑的问题(下)
ToT
- 摘要
- 介绍
- 利用大语言模型进行有意识的问题解决
-
- 1. 思维分解
- 2. 思维产生 G(p,s,k)
- 3. 状态评估V(p,S)
- 4. 搜索算法
- 实验
-
- 24游戏
-
- 1). 任务设置
- 2). 基准
- 3). ToT设置
- 4).结果
- 5). 错误分析
- 创意写作
-
- 1). 任务设置
- 2).基准
- 3).ToT设置
- 4).结果
- 交叉词
- 相关工作
-
- 规划和决策
- 自我反省
- 程序引导的LLM生成
- 经典搜索方法
- 讨论
- 总结
摘要
介绍
利用大语言模型进行有意识的问题解决
1. 思维分解
2. 思维产生 G(p,s,k)
3. 状态评估V(p,S)
4. 搜索算法
实验
24游戏
一个算数推理,目标是使用4个数字和基本算数运算符得到24。
1). 任务设置
从4nums.com中收集数据,该网站有1362个游戏,按人类解决时间从易到难排序,并索引为901-1000的相对困难的游戏子集进行测试。 对于每项任务,如果它是一个等于24的有效式子并且每项任务只使用一次输入数,我们就认为输出是成功的。 报告了100场比赛的成功率作为衡量标准。
2). 基准
我们使用了一个带有五个上下文示例的标准IO提示。
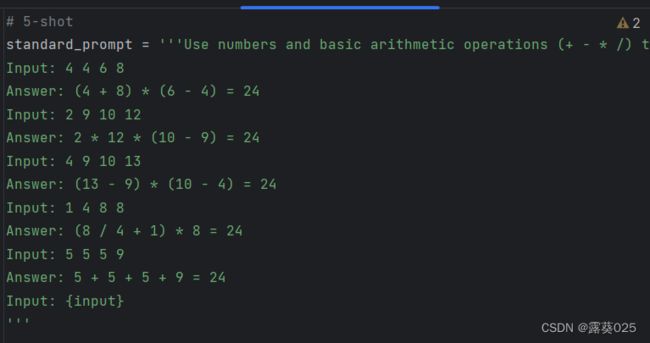
对于CoT提示,我们用3个中间方程来扩充每个输入-输出对,每个式子对剩余的两个数进行运算。

对于这个游戏,我们采集了100次IO提示和CoT提示的平均性能。我们还考虑了CoT自一致基线。在每次迭代中,LM都以所有先前的历史为条件,以“反思你的错误,并在输出不正确的情况下生成一个精确的答案”
3). ToT设置
为了把24游戏构建成TOT,自然而然就要将思维分解成三个步骤,每个都是中间的等式。在每棵树的节点,我们精准计算“left”数字,并提示LM提出一些可能的下一步措施。所有三个思维步骤都使用相同的“建议提示”,尽管它只有一个带有4个输入数字的例子。我们在TOT中执行了BFS,其中在每一步我们都保持b=5个最佳候选。为了在TOT上执行有意BFS,我们提示LM去评估每一个候选思维(评出sure/maybe/impossible)以达到24,。其目的是促使产生正确的部分解,消除基于“太大太小”常识的不可能的部分解,并保持其余的“可能”。对每个想法的值进行三次采样。
4).结果
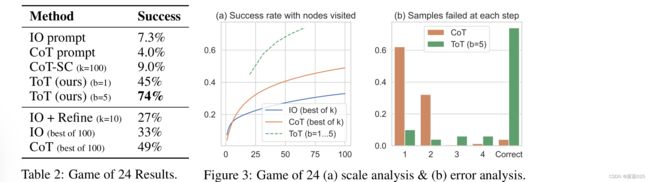
5). 错误分析
图3b细分了CoT和ToT样本失败的步骤,即在CoT中的想法或所有b在ToT的想法中,无效或不可能达到24。值得注意的是,大约60%的Col样本在生成第一步或等效的第三个单词(例如“4+9°”)后已经失败。这突出了直接从左到右解码的问题。
创意写作
创造性写作的任务:其中输入4个随机句子,输出应该是连贯的文章,由4个句子分别组成的段落。这个任务是开放性和探索性的,挑战创造思维和高层规划。
1). 任务设置
2).基准
3).ToT设置
建立了一个高度为2的ToT(即只有一个中间步骤)——LM首先产生k=5个计划并投出最好的一个,然后基于最好的计划中产生k=5个文章。这里的极限宽度b=1,因为每一步只保留一个选择。一个简单的零样本投票提示用于在两个步骤中抽取5张选票。
4).结果
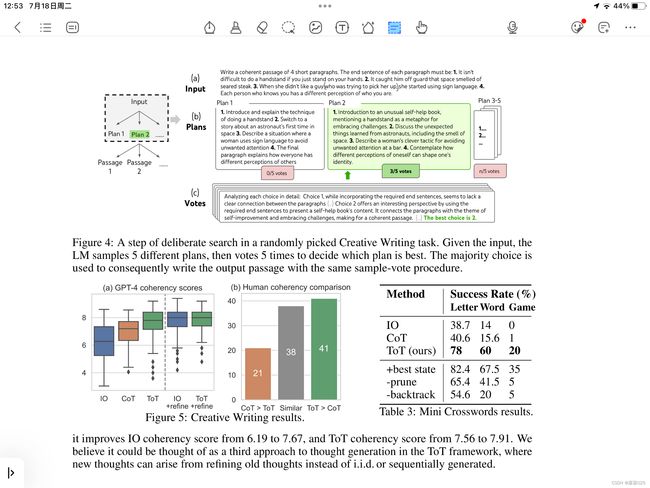
交叉词
相关工作
规划和决策
聪明的规划和决策对于实现预定的目标来说是至关重要的。它们在大量的知识和人类经验被训练出来,LM已经吸收了丰富的常识,这使得有可能根据问题设置和环境状态提出合理的计划。
TOT方法拓展了现有的规划公式,在每个解决问题的步骤的同时,考虑多个潜在可行计划,并继续进行最有可能的计划。
思维抽样和值反馈有机结合成规划和决策机制,使能够有效地搜索问题解决树。另一方面,传统的决策过程往往需要训练专门的奖励和策略模型来强化学习,而我们使用LM本身来为决策提供价值估计。
自我反省
使用LLM来评估生存能力或其自身的预测正则成为解决问题中越来越重要的程序。
引入了“自我反省”机制。在该机制中,LMs向其一代候选人提供反馈。
有的通过注入反馈消息(由LM自身根据其代码执行结果生成)来提高LM的代码生成的准确性。
类似的,还有引入了“评论家”或对“动作和状态”的审查步骤,以决定在解决计算机操作任务时要采取的下一步行动。
另一项与我们非常相关的是“自我价值引导解码”。自评估解码也遵循树搜索过程,从随机波束搜索解码中采样树叶,然后由LLM本身通过精心准备的自评估提示进行评估。
程序引导的LLM生成
程序引导LIM生成。我们的建议也与最近的进步有关,即用象征性的程序指导来组织LM的行为。例如在算法搜索过程中嵌入LM,以帮助逐步解决问题回答等问题,其中搜索树由可能提供答案的相关段落扩展。然而,这种方法与我们的不同之处在于,树是通过采样外部段落而不是LM自己的想法来扩展的,并且没有反思或投票步骤。另一种方法,LLM+P,更进一步,将实际规划过程委托给经典规划师。
经典搜索方法
最后但同样重要的是,我们的方法可以被视为解决问题的经典搜索方法的现代再现。例如,它可以被认为是一种启发式搜索算法,如,其中每个搜索节点的启发式由LM的自我评估提供。
讨论
总结
由于语言模型在推理过程中仍然局限于标记级别、从左到右做出决策的过程,有许多缺陷。
为了克服这种缺陷,本文从“双过程模式”研究入手,猜想1模式可能受益于2模式的规划过程:
- 对当前选择进行维护和探索不同的选择,而非只考虑一个
- 评估这个选择当前的状态,并积极前瞻或回溯,以做出更全局性的决策
从该过程获得灵感,将问题解决描述成组合问题空间(树)进行搜索。
其中每个思想都是一个连贯的语言序列,作为解决问题的中间步骤。树的节点代表一个思维状态或想法,边代表不同思维状态之间的关系和转换。
ToT的一个具体实例化设计回答四个问题:
- 如何将中间过程分解成思维步骤
- 如何在每个状态中产生潜在的思维
- 如何启发式的评估状态
- 使用什么搜索算法
第一个问题:
ToT利用了问题属性去设计和分解中间思维步骤。
一个想法可以是几个单词、一行方程公式或一整段写作计划。
第二个问题:
提供两种策略:
1. 从CoT提示中抽取独立同分布的思维样本
2. 使用“建议提示”按顺序提出想法,即在思维空间中提出一个思考路径或想法的提示
第三个问题:
使用LM来有意识的对不同的思维状态进行推理和思考。
要么独立评估每一个状态,要么采用跨状态投票的方式
第四个问题:
BFS、DFS
接着进行了三个实验,实验从任务设置、基准(IO提示、CoT提示、SC-CoT提示)、ToT设置、结果以及错误分析这几个模块展开,最终证明ToT较之前的方法表现更为优秀 。