Redis核心入门知识简记
什么是redis
答: 从以下4点进行以下介绍:
- 基于键值对的
NoSql数据库,支持stirng、hash、list、set、zset、bitmaps、HyperLogLog、GEO等数据结构极其算法。 - 读写性能非常好。
- 有将数据存到快照或者日志上的机制,便于数据恢复。
- 提供键过期、发布订阅、事务、流水线、lua脚本等附加功能。
redis有那些特性
- 读写速度据统计可达
10w/s。 - 支持列表、哈希、集合、有序集合等数据结构的操作和算法。
- 功能丰富,支持键值过期、发布订阅、
lua脚本创造新的Redis命令、客户端支持流水线操作,将一系列命令传给redis,避免多次网络IO。 - 简单稳定。
- 支持多种语言的客户端。
- 有
RDB和AOF两种持久化策略。 - 支持主从复制。
- 支持高可用和分布式。
redis快的原因是什么?(重点)
Redis是单线程的,表面资源竞争时的消耗。Redis底层对底层数据结构进行了优化,例如字符类型底层使用的是sds操作更加快速。- 基于
非阻塞式IO多路复用。
补充: 关于IO多路复用可以参考笔者这篇文章
https://www.sharkchili.com/pages/529382/#i-o-%E5%A4%9A%E8%B7%AF%E5%A4%8D%E7%94%A8%E6%A8%A1%E5%9E%8B
Redis有哪些使用场景知道吗?(面试题热身常用)
答: 大抵是以下几处会用到吧:
- 缓存
- 排行榜系统
- 计数器应用
- 社交网络点赞等功能
- 消息队列(不常用)
平时那些地方会用到redis
答: 就我工作来说,大概是以下几个地方吧:
- 缓存: 例如流程引擎获取回报数据较慢时,对串行业务图进行修改,第一搞轮询获取回报结果缓存到内存中,后续流程并行获取,从而解决系统某些流程慢的问题。
- 权限校验: 我们的系统某些地方需要时不时的进行权限校验,而这些数据不太经常发生变化,对于这种
"热点数据",我会将其放到缓存中,时效设置为8h(系统使用者工作时长)。 - 分布式锁: 某些业务派单的功能,业务员因为业绩原因会抢单,所以我们需要使用分布式锁进行流程把控,在我负责的分布式锁功能开发中,设计者为了保证系统宕机分布式锁能够及时释放,所以对锁有设置时效,由于欠缺考虑,出现业务员受理业务过程中锁时效,进而其他业务员看到这笔订单进而导致互斥失败问题,对此我使用了续命线程解决问题的经验。
- 乐观锁。
关于分布式锁,可以参考笔者这篇文章:
基于Redis实现分布式锁
有哪些地方不建议使用redis?
答: emmm,尽量别把内存打满吧,否则麻烦就很多,整体来说使用原则大概有下面几点:
- 几亿用户行为的数据不建议使用
redis进行维护管理。 - 不经常被使用的冷数据不建议使用
redis管理。
Redis6.0使用多线程是怎么回事?
Redis6.0的多线程是用多线程来处理数据的读写和协议解析,但是Redis执行命令还是单线程的。这样做的⽬的是因为Redis的性能瓶颈在于⽹络IO⽽⾮CPU,使⽤多线程能提升IO读写的效率,从⽽整体提⾼Redis的性能。
如何安装使用redis
答: 好的,那我们就从头开始讲讲这方面的实践吧:
前置步骤,安装C 语言的编译环境(如果服务器有这个过程的同学可忽略)
yum install centos-release-scl scl-utils-build
yum install -y devtoolset-8-toolchain
scl enable devtoolset-8 bash
完成之后设置gcc版本
如果下面这段话有输出则说明安装成功了。
gcc --version
下载redis-6.2.1.tar.gz放/opt目录
存放目录位置随意,读者也可以遵循Linux文件存放规范将其放到usr目录下。
解压redis
redis放到文件夹之后,我们就可以进行解压安装了。
tar -zxvf redis-6.2.1.tar.gz
解压完成后进入目录:cd redis-6.2.1
键入make 执行编译,完成后执行make install
注意:如果没有准备好C语言编译环境,make 会报错—Jemalloc/jemalloc.h:没有那个文件,可以运行make distclean,再次运行make即可解决问题
自此,redis安装已经全部完成,redis会被默认安装在/usr/local/bin目录,所以为了方便后续各种操作,我们可以运行如下命令,创建一个redis配置目录方便后续各种实验操作
# 创建配置文件实验文件夹
mkdir myredis
进入redis解压目录
cd /opt/redis-6.2.1/
复制配置文件到新文件夹
cp redis.conf /myredis/
# 进入redis命令目录
cd /usr/local/bin/
Redis使用案例能不能也给我说说
答: 好的,我们先从不同的启动方式说起吧:
前台启动
先来讲讲前台启动吧,这种方式一旦你退出终端或者按住ctrl+c进程就直接结束了。
redis-server /myredis/redis.conf
后台启动(推荐)
要想实现后台启动,我们就必须修改redis配置
vim /myredis/redis.conf
按/daemonize找到daemonize,将此参数设置为yes,如下图所示
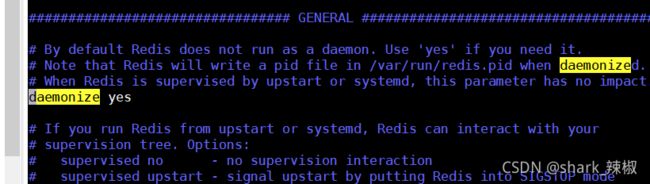
启动
# 启动redis
/usr/local/bin/redis-server /myredis/redis.conf
# 检查redis是否启动
ps -ef|grep redis
完成我们启动redis客户端进行连接,输入ping,如果得到pong响应则说明redis服务端启动成功了。
/usr/local/bin/redis-cli
若输出PONG,则说明redis客户端已经与服务端连通。
如何关闭redis服务端
答: 友好一点就是下面两种方式,平时我比较粗暴,直接kill命令干掉。
- 客户端运行
shutdown /usr/local/bin/redis-cli -p 6379 shutdown
redis有哪些常见操作
答: 整体来说下面这些命令都是挺经常用到的:
查看所有键值
127.0.0.1:6379> keys *
(empty list or set)
添加或者删除键值
# 添加字符串
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> set java jedis
OK
127.0.0.1:6379> set python redis-py
OK
# 添加一个key名为mylist的键,存储一堆元素a b c d e f g
127.0.0.1:6379> RPUSH mylist a b c d e f g
(integer) 7
# 使用keys * ,查看我们刚刚添加的key
127.0.0.1:6379> KEYS *
1) "python"
2) "java"
3) "hello"
查看当前键的数
127.0.0.1:6379> DBSIZE
(integer) 3
查看key是否存在
# 存在返回1 不存在返回0
127.0.0.1:6379> EXISTS java
(integer) 1
设置键过期
# 添加一个键hello 设置10秒过期
127.0.0.1:6379> set hello world
OK
# 查看是否存在
127.0.0.1:6379> EXPIRE hello 10
(integer) 1
# 我们也可以用tts判断是否存在,若过期则返回-2
127.0.0.1:6379> ttl hello
(integer) -2
查看键值对的数据类型
127.0.0.1:6379> type mylist
list
redis字符串类型的常见操作指令有哪些?
答: 整体来说增删改查指令如下:
设置值
赋值指令如下所示,[]为可选项
set key value [ex value 秒级过期时间] [px value 设置当前键值对的毫秒级过期时间] [nx 若键值存在才能赋值] [xx 若键值存在才能赋值]
示例
设置一个key为str,value为hello的字符串
127.0.0.1:6379> set str hello
OK
127.0.0.1:6379>
设置一个10s过期的字符串str2,值为str2
127.0.0.1:6379> set str2 str2 ex 10
OK
# 10s内值还在
127.0.0.1:6379> get str2
"str2"
# 10s后键值对消失
127.0.0.1:6379> get str2
(nil)
127.0.0.1:6379>
setnx(常用于乐观锁)、setxx、setex
setnx和set的nx选项类似,值不存在时才能建立键值对
setnx key value
示例
# 判断hello是否存在
127.0.0.1:6379> EXISTS hello
(integer) 0
# 设置hello
127.0.0.1:6379> set hello world
OK
# 如果hello不存在 则设置一个key为hello value为h的键值对
127.0.0.1:6379> SETNX hello h
(integer) 0
# 发现值没变还是原本set指令的
127.0.0.1:6379> get hello
"world"
# h不存在
127.0.0.1:6379> EXISTS h
(integer) 0
# 使用setnx赋值,在使用get指令查看,发现存在
127.0.0.1:6379> SETNX h hello
(integer) 1
127.0.0.1:6379> get h
"hello"
127.0.0.1:6379>
setxx相对set指令的xx选项,这里就不多赘述了
setex相当于set指令的ex选项
# 设置一个10s过期的键为key 值为value的键值对
127.0.0.1:6379> SETEX key 10 value
OK
127.0.0.1:6379> get key
"value"
# 10s后过期
127.0.0.1:6379> get key
(nil)
字符串值的获取
get key
批量设置值和获取值
# 批量设置
mset key value [key value] [key value] [key value]
# 批量获取
mget key1 key2 ....
示例
127.0.0.1:6379> MSET a 1 b 2 c 3
OK
127.0.0.1:6379> MGET a b c
1) "1"
2) "2"
3) "3"
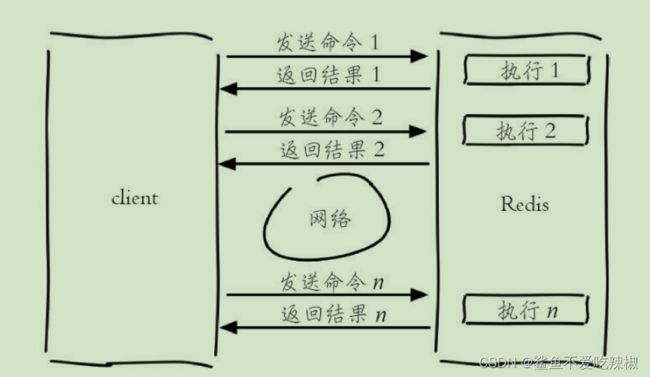
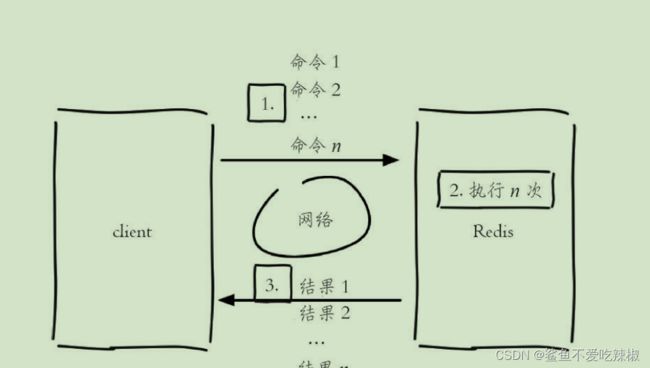
注意:如果我们某个业务需要获取redis中大量的key值,建议使用mget,原因:
使用set获取1000个key: 1000个网络io时间+1000个指令执行时间
使用mget获取1000个key:1个网络io时间+1000个指令执行时间
get指令请求模型
mget指令请求模型
字符串数字类型计数自增相关
自增指令,若值不存在,则创建并初始值为1,若存在且为整数则自增,若存在且为字符文字则报错。
因为redis是单线程的,所以计数指令无需考虑线程安全问题,无需使用CAS等手段来修改值而是顺序执行自增,所以性能相当优秀。
incr key
示例
127.0.0.1:6379> INCR k
(integer) 1
127.0.0.1:6379> INCR k
(integer) 2
127.0.0.1:6379> set str str
OK
127.0.0.1:6379> incr str
(error) ERR value is not an integer or out of range
127.0.0.1:6379>
其他计数指令
# 自减
decr key
# 自增自己指定的值
incrby key increment
# 自减指定的值
decrby key decrement
# 自增小数值
incrbyfloat key increment
字符串追加指令
追加值
append key value
示例
# 对key为hello的值增加一个world字符串
127.0.0.1:6379> set hello hello
OK
127.0.0.1:6379> APPEND hello world
(integer) 10
127.0.0.1:6379> get hello
"helloworld"
127.0.0.1:6379>
获取字符串长度
strlen key
示例
127.0.0.1:6379> strlen hello
(integer) 10
127.0.0.1:6379>
修改value并返回修改前的值
getset key value
示例
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> GETSET hello redis
"world"
127.0.0.1:6379>
获取当前字符串指定返回内的值
语法
GETRANGE key start end
示例
127.0.0.1:6379> set str 0123456789
OK
127.0.0.1:6379> GETRANGE str 0 2
"012"
字符串各个操作的时间复杂度
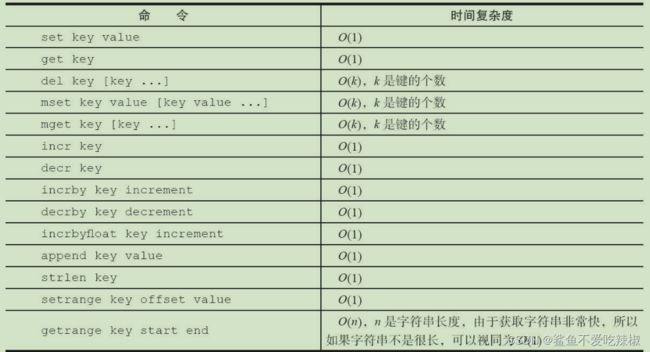
Redis字符类型各种有哪些使用场景呢?
用户信息缓存
如下所示,可将常见的数据库数据存到redis中提高访问数据,建议使用的key为表名:对象名:id,例如userInfo:user:1
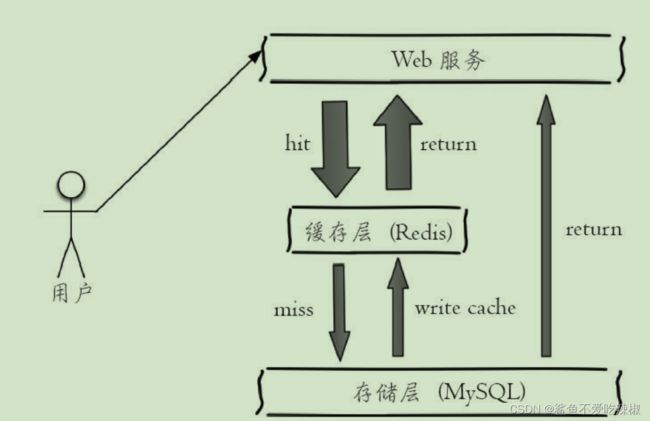
伪代码示例
UserInfo getUserInfo(long id){
userRedisKey = "user:info:" + id
value = redis.get(userRedisKey);
UserInfo userInfo;
if (value != null) {
userInfo = deserialize(value);
} else {
userInfo = mysql.get(id);
if (userInfo != null)
redis.setex(userRedisKey, 3600, serialize(userInfo));
}
return userInfo;
}
视频播放量计数
long incrVideoCounter(long id) {
key = "video:playCount:" + id;
return redis.incr(key);
}
分布式共享session
为了保证用户在集群场景下能够公用一个会话session,我们会另起一台服务器搭建redis服务保存会话session,避免用户因为负载均衡在各个服务器之间时重复登录。
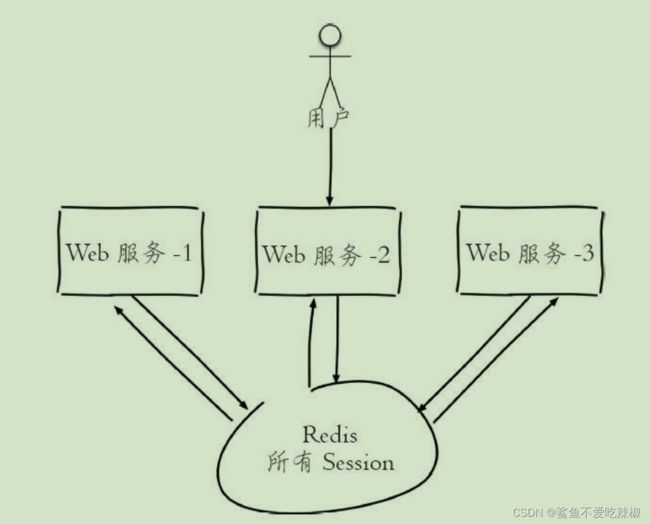
短信限速
避免单用户一分钟不能超过5次访问
phoneNum = "138xxxxxxxx";
key = "shortMsg:limit:" + phoneNum;
// SET key value EX 60 NX
isExists = redis.set(key,1,"EX 60","NX");
if(isExists != null || redis.incr(key) <=5){
// 通过
}else{
// 限速
}
哈希类型的常见操作命令是什么?
答: 存储键值对的数据结构,也叫映射,字典。逻辑结构如下图所示:
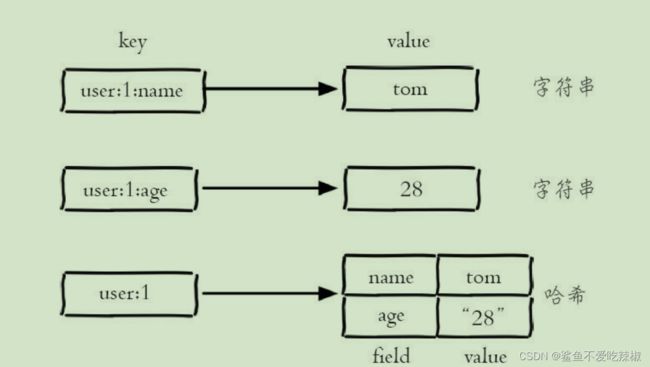
设置值和取值
语法,如下所示,fileid就是哈希的键,value就是值。
# 设置值
HSET key field value
# 获取值
HGET key field
示例
127.0.0.1:6379> HSET hashmap key1 value1 key2 value2
(integer) 2
127.0.0.1:6379> HGET hashmap key1
"value1"
127.0.0.1:6379>
删除哈希一个键
语法
HDEL key field
格式
# 删除hashmap的key1
127.0.0.1:6379> HDEL hashmap key1
(integer) 1
127.0.0.1:6379>
计算redis中哈希类型的数据的个数
语法
HLEN key
示例
127.0.0.1:6379> HLEN hashmap
(integer) 1
127.0.0.1:6379>
批量设置哈希的值和批量获取哈希的值
语法
HMSET key field value [field value] [field value]
HMGET key field [field] [field] [field]
示例
127.0.0.1:6379> HMSET user:1 name xiaoming age 18 city fujian
OK
127.0.0.1:6379> HMGET user:1 name age city
1) "xiaoming"
2) "18"
3) "fujian"
127.0.0.1:6379>
判断键值对是否存在
127.0.0.1:6379> HEXISTS key field
示例
127.0.0.1:6379> HEXISTS user:1 name
(integer) 1
127.0.0.1:6379>
获取所有key、获取所有value、获取所有的key-value
语法
# 获取所有key
HKEYS key
# 获取所有value
HVALS key
# 获取所有key-value
HGETALL key
示例
127.0.0.1:6379> HKEYS user:1
1) "name"
2) "age"
3) "city"
127.0.0.1:6379> HVALS user:1
1) "xiaoming"
2) "18"
3) "fujian"
127.0.0.1:6379> HGETALL user:1
1) "name"
2) "xiaoming"
3) "age"
4) "18"
5) "city"
6) "fujian"
127.0.0.1:6379>
建议: 若哈希中存在多个键值对且我们需要一次性获取,建议使用hscan而不是hmget,避免造成redis阻塞
# 使用hscan从0位置获取所有键值对
127.0.0.1:6379> HSCAN user:1 0
1) "0"
2) 1) "name"
2) "xiaoming"
3) "age"
4) "18"
5) "city"
6) "fujian"
127.0.0.1:6379>
自增哈希数据类型value的值
和incr类似,只不过增长的是field的值
hincrby key field
hincrbyfloat key field
计算field的长度
语法
hstrlen key field
示例
获取user:1 的name的长度
127.0.0.1:6379> HSTRLEN user:1 name
(integer) 8
127.0.0.1:6379>
哈希各个命令的时间复杂度

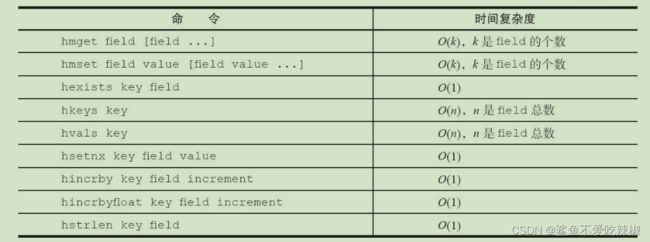
哈希类型的使用场景有哪些呢?
如果我们要缓存某行用户信息,使用哈希非常合适不过
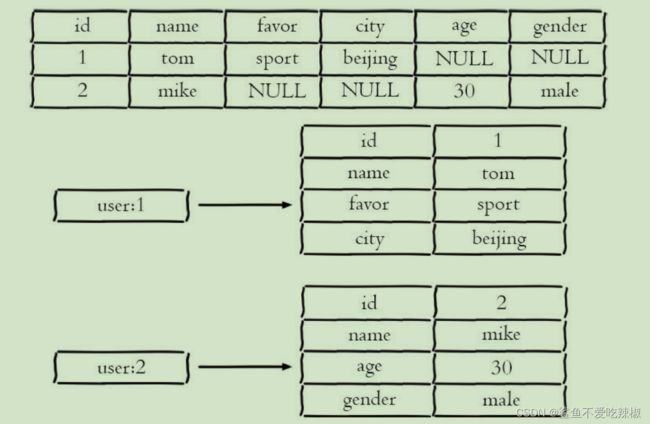
原因如下:
1. 相较于字符串(占用过多的键),哈希内聚更好更易于维护大量的用户信息
2. 如果使用字符串进行序列化存储,就会造成网络io时序列化和反序列化的开销
3. 操作简单,修改用户字段更加方便
需要注意:哈希存储相对二维表更加稀疏,如上图,二维表中null的数据,在哈希表中key是完全不存在的用户使用时需要考虑到这一点。
什么是列表类型,它有什么特点
答: 列表的概念和Java的List是差不多的,都是线性结构,允许重复元素,可以充当队列和栈。
redis列表的常见操作有哪些呢?
答: 无非也是那些增删改查吧:
添加
从右边插入,语法:
RPUSH key value [value]
示例
# 右边一次插入a b c
127.0.0.1:6379> RPUSH list a b c
(integer) 3
# 查看list的元素
127.0.0.1:6379> LRANGE list 0 -1
1) "a"
2) "b"
3) "c"
127.0.0.1:6379>
从左边插入元素 lpush
LPUSH key value [value...]
# 从左边依次插入
127.0.0.1:6379> LPUSH arr a b c
(integer) 3
# 查看最终的元素值
127.0.0.1:6379> LRANGE arr 0 -1
1) "c"
2) "b"
3) "a"
127.0.0.1:6379>
向元素前或者后添加元素
linsert key before|after pivot value
示例:向a后面添加一个元素a+
127.0.0.1:6379> LRANGE list 0 -1
1) "a"
2) "b"
3) "c"
127.0.0.1:6379> LINSERT list after a a+
(integer) 4
127.0.0.1:6379> LRANGE list 0 -1
1) "a"
2) "a+"
3) "b"
4) "c"
127.0.0.1:6379>
查询操作
查找指定范围的元素
lrange key start end
示例
# 查看list的所有元素
127.0.0.1:6379> LRANGE list 0 -1
1) "a"
2) "a+"
3) "b"
4) "c"
# 查看一个不存在的key的元素
127.0.0.1:6379> LRANGE key 1 2
(empty array)
# 查看list 2-3的元素
127.0.0.1:6379> LRANGE list 1 2
1) "a+"
2) "b"
127.0.0.1:6379>
获取指定索引的元素
lindex key index
示例:查看key为list第0个元素
127.0.0.1:6379> LRANGE list 0 -1
1) "a"
2) "a+"
3) "b"
4) "c"
127.0.0.1:6379> LINDEX list 0
"a"
127.0.0.1:6379>
获取列表长度
llen key
示例
127.0.0.1:6379> LRANGE list 0 -1
1) "a"
2) "a+"
3) "b"
4) "c"
127.0.0.1:6379> LLEN list
(integer) 4
127.0.0.1:6379>
从列表中弹出元素
从列表左侧弹出元素
lpop key
示例
127.0.0.1:6379> LRANGE list 0 -1
1) "a"
2) "a+"
3) "b"
4) "c"
127.0.0.1:6379> LPOP list
"a"
127.0.0.1:6379> LRANGE list 0 -1
1) "a+"
2) "b"
3) "c"
127.0.0.1:6379>
同理右侧为rpop,不多赘述
删除元素
lrem key count value
count的大小有以下几种情况
1. 大于0,从左到右删除count个元素
2. 小于0,从右到左删除count个元素
3. =0 删除所有元素
示例:从左到右删除一个为a的元素
127.0.0.1:6379> LRANGE list 0 -1
1) "a+"
2) "b"
3) "c"
127.0.0.1:6379> LREM list 1 b
(integer) 1
127.0.0.1:6379> LRANGE list 0 -1
1) "a+"
2) "c"
127.0.0.1:6379>
修剪列表至指定索引范围
ltrim key start end
示例,将列表修剪为只有2 15索引范围内的元素
127.0.0.1:6379> LRANGE list 0 -1
1) "a+"
2) "z"
3) "a"
4) "b"
5) "c"
6) "d"
7) "e"
8) "f"
9) "g"
10) "h"
11) "i"
12) "j"
13) "k"
14) "l"
15) "m"
16) "n"
127.0.0.1:6379> LTRIM list 2 15
OK
127.0.0.1:6379> LRANGE list 0 -1
1) "a"
2) "b"
3) "c"
4) "d"
5) "e"
6) "f"
7) "g"
8) "h"
9) "i"
10) "j"
11) "k"
12) "l"
13) "m"
14) "n"
127.0.0.1:6379>
修改列表内的某些元素
lset key index newValue
阻塞弹出列表元素操作
blpop key [key ...] timeout
brpop key [key ...] timeout
brpop 示例,当timeout大于0时,若有元素立即返回,若没有则等到对应时间为止
若timeout设置为0,则无限等待,如下所示,笔者使用另一个客户端push一个元素进来,这个阻塞就会立刻将这个元素弹出。
127.0.0.1:6379> BRPOP arr 3
1) "arr"
2) "a"
127.0.0.1:6379> BRPOP arr 3
1) "arr"
2) "b"
127.0.0.1:6379> BRPOP arr 3
1) "arr"
2) "c"
127.0.0.1:6379> BRPOP arr 3
(nil)
(3.04s)
127.0.0.1:6379> BRPOP arr 3
(nil)
(3.07s)
127.0.0.1:6379> BRPOP arr 0
1) "arr"
2) "a"
(43.69s)
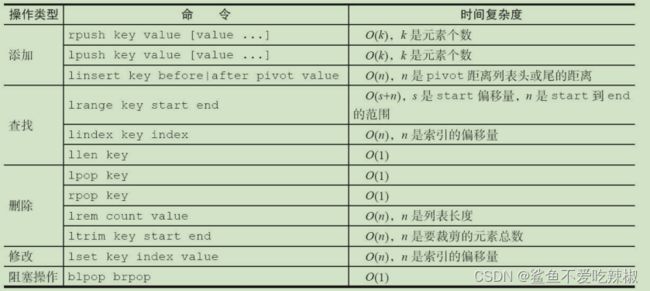
列表各个操作的时间复杂度
列表常见的使用场景有哪些呢?
答: Redis的lpush+brpop命令组合即可实现阻塞队列,如下图,每个消费者只需要关注自己感兴趣的专题即可,作为生产者只需不断使lpush添加专题即可。

关于列表更多用法可以参见以下口诀
1. lpush+lpop=Stack(栈)
2. lpush+rpop=Queue(队列)
3. lpsh+ltrim=Capped Collection(有限集合)
4. lpush+brpop=Message Queue(消息队列)
集合类型的特点和常见命令是什么?
答: 我们先来说说它的特点吧:
- 最多可存储2^32-1个元素
- 集合内部元素不重复
而命令大概有下面这些:
添加元素
注意集合中的元素是不重复的
sadd key element [element ...]
示例,可以看到第2次添加的元素并没有成功
127.0.0.1:6379> SADD set a b c
(integer) 3
127.0.0.1:6379> SADD set a b
(integer) 0
127.0.0.1:6379>
删除元素
srem key element [element ...]
计算集合大小
注意,这个计算的时间复杂度为O(1),因为获得的这个集合的大小并不是计算来的,而是通过redis维护的一个内部变量得来的。
scard key
判断元素是否在集合中
sismember key element
示例
127.0.0.1:6379> SISMEMBER set a
(integer) 1
127.0.0.1:6379> SISMEMBER set ac
(integer) 0
127.0.0.1:6379>
随机获取集合内的元素
srandmember key [count]
示例
127.0.0.1:6379> SRANDMEMBER set 1
1) "a"
127.0.0.1:6379> SRANDMEMBER set 1
1) "c"
127.0.0.1:6379>
随机弹出一个元素
与srandmember 差不多,只不过该操作会将元素输出并将集合中的这个元素删除
spop key
示例
127.0.0.1:6379> SPOP set
"c"
127.0.0.1:6379> SPOP set
"a"
127.0.0.1:6379> SPOP set
"b"
127.0.0.1:6379> SPOP set
(nil)
127.0.0.1:6379> SPOP set
(nil)
127.0.0.1:6379> SPOP set
(nil)
127.0.0.1:6379> SPOP set
(nil)
127.0.0.1:6379> SPOP set
获取所有元素
smembers key
获取两个集合之间的交集
语法如下,它的作用是取操作集合中都有元素
sinter key [key ...]
示例,可以看出set1和set2的交集为a
127.0.0.1:6379> SADD set1 a b c d
(integer) 4
127.0.0.1:6379> SADD set2 a e f g h
(integer) 5
127.0.0.1:6379> SINTER set1 set2
1) "a"
127.0.0.1:6379>
求集合中的并集
suinon key [key ...]
求集合中的差集
sdiff key [key ...]
示例,注意这个差集指的是第一个集合有,其他集合没有的元素
127.0.0.1:6379> SDIFF set1 set2
1) "b"
2) "d"
3) "c"
将交集、并集、差集结果保存
# 获取交集结果并保存
sinterstore destination key [key ...]
# 获取并集结果并
suionstore destination key [key ...]
# 获取差集结果并保存
sdiffstore destination key [key ...]
示例:将并集的结果保存
127.0.0.1:6379> SADD set1 a b c d
(integer) 4
127.0.0.1:6379> SADD set2 a e f g h
(integer) 5
127.0.0.1:6379> SINTERstore set3 set1 set2
(integer) 1
127.0.0.1:6379> SMEMBERS set3
1) "a"
127.0.0.1:6379>
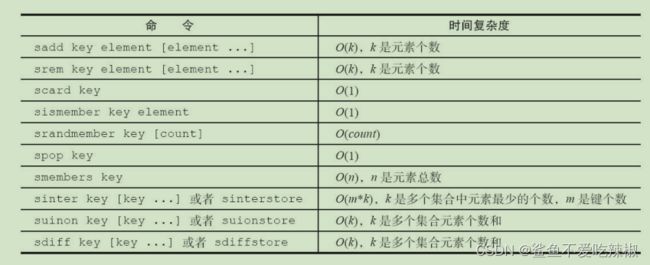
集合的各个操作的时间复杂度
使用场景
- sadd=Tagging(标签,例如交友网站个人标签)
- spop/srandmember=Random item(生成随机数,比如抽奖)
- sadd+sinter=Social Graph(社交需求,与附近的人爱好匹配)
有序集合是什么?如何使用?
答: 和集合差不多的东西:
- 相较于集合,增加一个
score属性,使得整体有序。 - 集合元素不可重复,但是
score可以重复。

添加元素的命令
命令如下所示,可以看到赋值格式需要value以及value的score这样的添加操作
zadd key score member [score member ...]
示例
127.0.0.1:6379> zadd zset 1 tom 2 jack 3 lucy
(integer) 3
127.0.0.1:6379>
可选项
1. nx:member必须不存在,才可以设置成功,用于添加。
2. xx:member必须存在,才可以设置成功,用于更新。
3. ch:返回此次操作后,有序集合元素和分数发生变化的个数
4. incr:对score做增加,相当于后面介绍的zincrby。
示例:如果tom存在,给tom自增。
127.0.0.1:6379> zadd zset xx incr 1 tom
"2"
相比于集合,有序集合增加了排序的操作,添加成员的时间复杂度由原来的O(1)变为O(logn)
计算指定key的有序集合的大小
于scard一样,时间复杂度也是O(1)
指令
zcard key
示例
127.0.0.1:6379> ZCARD zset
(integer) 3
127.0.0.1:6379>
查看有序集合中某个成员的分数
指令
zscore key member
示例
127.0.0.1:6379> zscore zset tom
"3"
127.0.0.1:6379> zscore zset jack
"2"
127.0.0.1:6379> zscore zset xiaoming
(nil)
127.0.0.1:6379>
获取有序集合中某个成员的排名
命令
# 升序排名
zrank key member
# 降序排名
zrevrank key member
示例
127.0.0.1:6379> ZRANK zset tom
(integer) 2
127.0.0.1:6379> ZrevRANK zset tom
(integer) 0
127.0.0.1:6379>
删除key中的指定成员
命令
zrem key member [member ...]
示例
127.0.0.1:6379> ZREM zset tom jack
(integer) 2
127.0.0.1:6379>
给成员增加分数
指令
zincrby key increment member
示例
127.0.0.1:6379> ZINCRBY zset 100 tom
"100"
127.0.0.1:6379> ZINCRBY zset 100 tom
"200"
127.0.0.1:6379>
获取指定排名范围内的成员以及score
指令
zrange key start end [withscores]
zrevrange key start end [withscores]
示例
127.0.0.1:6379> ZRANGE zset 0 -1 withscores
1) "lucy"
2) "3"
3) "tom"
4) "200"
127.0.0.1:6379>
返回指定分数范围的成员
指令
zrangebyscore key min max [withscores] [limit offset count]
zrevrangebyscore key max min [withscores] [limit offset count]
示例
127.0.0.1:6379> ZRANGEBYSCORE zset 0 300 withscores
1) "lucy"
2) "3"
3) "tom"
4) "200"
获取10到无限大的成员
127.0.0.1:6379> ZRANGEBYSCORE zset (10 +inf withscores
1) "liu"
2) "11"
3) "tom"
4) "200"
127.0.0.1:6379>
获取指定分数范围内的用户
指令
zcount key min max
示例
127.0.0.1:6379> ZCOUNT zset 0 10
(integer) 2
127.0.0.1:6379>
删除指定排名内的用户
指令
zremrangebyrank key start end
示例:删除前3名成员
127.0.0.1:6379> ZREMRANGEBYRANK zset 0 2
(integer) 3
127.0.0.1:6379>
删除指定分数范围内的用户
指令
zremrangebyscore key min max
示例
127.0.0.1:6379> ZREMRANGEBYSCORE zset (250 +inf
(integer) 1
127.0.0.1:6379>
有序集合有哪些使用场景呢?
答: 常用于点赞、播放量等排行榜
如下就模拟了点赞排行榜的操作
# 小明获得10个赞
127.0.0.1:6379> zadd user:ranking:20220810 10 xiaoming
(integer) 1
# 小王获得11个赞
127.0.0.1:6379> zadd user:ranking:20220810 11 xiaowang
(integer) 1
# 小刘获得8个赞
127.0.0.1:6379> zadd user:ranking:20220810 8 xiaoliu
(integer) 1
# 小刘的赞+1
127.0.0.1:6379> zincrby user:ranking:20220810 1 xiaoliu
"9"
# 查看排名前3
127.0.0.1:6379> zrevrange user:ranking:20220810 0 2
1) "xiaowang"
2) "xiaoming"
3) "xiaoliu"
# 小刘被取消一个赞
127.0.0.1:6379> zincrby user:ranking:20220810 -1 xiaoliu
"8"
Bitmaps类型是什么
bitmaps本不是一种数据结构,它只是基于字符串创建的一种可以进行位运算的的字符串。- 与字符串不同的是他的操作方式比较特殊,我们可以把它们当作一个只能存储0、1的数组,而数组中的每一个位置,我们可以通过偏移量(这个偏移量我认为可以当作索引)来设置0或者1。如下图:

Bitmaps常见操作示例
设置值
setbit key offset value
例如我想在user:20220812这个key的第15位设置1
127.0.0.1:6379> SETBIT user:20220812 15 1
(integer) 0
获取值
gitbit key offse
实例:获取user:20220822偏移量为15的值
127.0.0.1:6379> getbit user:20220812 15
(integer) 1
127.0.0.1:6379>
获取bitmaps对应key的value为1的总数
bitcount key [start][end]
示例:
127.0.0.1:6379> BITCOUNT user:20220812 0 10
(integer) 3
127.0.0.1:6379> BITCOUNT user:20220812 1 3
(integer) 1
bitmaps的位运算
bitop op destkey key[key....]
bitop是一个复合操作,它可以做多个Bitmaps的and(交集)、or(并集)、not(非)、xor(异或)操作并将结果保存在destkey中。
使用示例
# k1的 1 2 3设置为1
127.0.0.1:6379> SETBIT k1 1 1
(integer) 0
127.0.0.1:6379> SETBIT k1 2 1
(integer) 0
127.0.0.1:6379> SETBIT k1 3 1
(integer) 0
# k2的1 3 5设置为1
127.0.0.1:6379> SETBIT k2 1 1
(integer) 0
127.0.0.1:6379> SETBIT k2 3 1
(integer) 0
127.0.0.1:6379> SETBIT k2 5 1
(integer) 0
# 两个bitmaps的与运算
127.0.0.1:6379> BITOP and and_result k1 k2
(integer) 1
# 因为两个bitmaps1 3位置都为1,结果与运算结果就为1
127.0.0.1:6379> BITCOUNT and_result
(integer) 2
127.0.0.1:6379>

bitmaps的使用场景
答: 统计用户活跃度等,例如我们用bitmaps同理的用户id为1000的用户昨天和今天的登录情况。当我们需要统计本月的活跃度时,就可以使用bitmaps的and运算计算机用户活跃天数。

bitmaps有哪些使用使用注意事项知道吗?
答: 相较于set,bitmaps存储同样的用户量所占用的内存少非常多,但这并不意味着bitmaps是万金油。
bitmaps进行set操作时,假如偏移量过大有可能造成redis阻塞,所以我们常会建议用户id尽可能通过计算减少偏移量范围,也正因为如此,有些用户数随随便便上百万的网站若存在大量僵尸用户的情况下,我们还是建议使用set,毕竟一堆没有用的位存储着0且还要为着偶尔一些百万id的用户设置1是非常不值当的行为。

HyperLogLog类型是什么?
答: HyperLogLog不是新的数据结构,而是一种基数算法,它可以实现使用极小的内存完成基数的统计。
什么是基数呢,例如我们有数字1、3、3、5、5、7、7,那么基数就是1、3、5、7。
HyperLogLog添加的添加操作
pfadd key element [element … ]
示例
# 添加多个
127.0.0.1:6379> PFADD course java python
(integer) 1
# 添加一个
127.0.0.1:6379> PFADD course c++
(integer) 1
# 添加一个重复的,发现添加失败
127.0.0.1:6379> PFADD course c++
(integer) 0
127.0.0.1:6379>
计算总数
pfcount key [key … ]
示例
127.0.0.1:6379> PFCOUNT course
(integer) 3
127.0.0.1:6379>
- 合并
pfmerge destkey sourcekey [sourcekey ...]
示例,我们将上文的course和下面创建的course2合并
# course总数为3
127.0.0.1:6379> PFCOUNT course
(integer) 3
# course2为1
127.0.0.1:6379> PFADD course2 .net
(integer) 1
# 两者value不重复 合并到course就为4
127.0.0.1:6379> PFMERGE course course2
OK
127.0.0.1:6379> PFCOUNT course
(integer) 4
# 合并到result,因为此时course和course都有重复元素.net,所以最终合并结果也是为4
127.0.0.1:6379> PFmerge result course course2
OK
127.0.0.1:6379> PFCOUNT result
(integer) 4
127.0.0.1:6379>
HyperLogLog使用场景知道和注意事项有哪些呢?
答: 计算每个月用户系统访问量,通过将ip不断存到该集合之后进行去重统计。
而注意事项嘛,大概如下面所示:
从下图可以看出与set相比HyperLogLog占用内存会节省非常多,但是HyperLogLog会存在一定误差率,据redis官方统计误差率为0.81%,若对统计的数据没有非常高的精确度,使用该类型非常合适。

关于计算距离相关的Geospatial了解过嘛?
答: Redis 3.2 中增加了对GEO类型的支持。GEO,Geographic,地理信息的缩写。该类型,就是元素的2维坐标,在地图上就是经纬度。redis基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度Hash等常见操作。
添加某个地区坐标
geoadd key longitude latitude member [longitude latitude member ...]
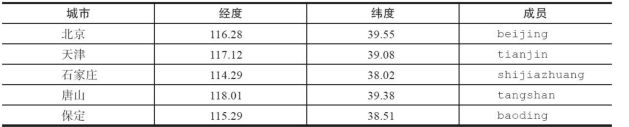
# 注意不可重复添加,重复添加会返回0
127.0.0.1:6379> geoadd cities:locations 116.28 39.55 beijing
(integer) 1
获取地理位置
geopos key member [member ...]
示例
127.0.0.1:6379> GEOPOS cities:locations beijing
1) 1) "116.28000229597091675"
2) "39.5500007245470826"
计算距离
geodist key member1 member2 [unit]
unit:
m(meters)代表米。
km(kilometers)代表公里。
mi(miles)代表英里。
ft(feet)代表尺。
示例
127.0.0.1:6379> GEODIST cities:locations beijing tianjin
"89206.0576"
127.0.0.1:6379> GEODIST cities:locations beijing tianjin km
"89.2061"
获取指定范围内的地区
georadius key longitude latitude radiusm|km|ft|mi [withcoord] [withdist]
[withhash] [COUNT count] [asc|desc] [store key] [storedist key]
georadiusbymember key member radiusm|km|ft|mi [withcoord] [withdist]
[withhash] [COUNT count] [asc|desc] [store key] [storedist key]
示例:100 300这个坐标5000km范围内的地区
127.0.0.1:6379> GEORADIUS cities:locations 100 30 5000 km
1) "beijing"
2) "tianjin"
127.0.0.1:6379>
获取指定位置的geohash
geohash key member [member ...]
示例
127.0.0.1:6379> GEOHASH cities:locations beijing
1) "wx48ypbe2q0"
127.0.0.1:6379>
GEO使用注意事项
答: GEO的数据类型为zset,所以我们通过geohash可以得到上述的值,redis会将这些地理信息存放在zset中。
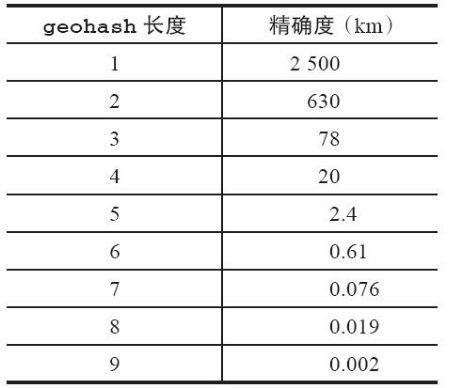
需要我们了解的ghash值越相似说明这两个位置距离越近,而且geohash的长度越长则精确度越高,地理位置就越准确。
redis也正是通过有序集合zset实现了GEO若干指令。
参考文献
Redis开发与运维
面渣逆袭(Redis面试题八股文)必看