【C++】STL | 模拟实现简易string
目录
1. 框架搭建
2. 迭代器的实现
3. string的拷贝构造和赋值(深拷贝)
拷贝构造
赋值构造
4. string的增删查改
reserve 接口
resize 接口
push_back 接口
append 接口
operator+=() 实现
insert 接口
erase 接口
find 接口
substr 接口
clear 接口
流插入和流提取
5. 用于比较的操作符重载函数
operator<
operator==
其它复用
6. 源码分享
写在最后:
1. 框架搭建
首先啊,我们需要搭建好一个框架,
然后在往里面填充内容。
那搭建框架主要包括这几个点:
1. 基本的默认成员函数
2. 必须的成员变量
3. 常用的简单接口(先让代码跑起来)
来看代码:
#pragma once
#include
#include
#include
#include
using namespace std;
namespace xl {
class string {
private:
char* _str;
size_t _size;
size_t _capacity;
public:
string(const char* str = "")
: _size(strlen(str))
, _capacity(_size)
{
_str = new char[_capacity + 1];
strcpy(_str, str);
}
~string()
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
public:
char& operator[](size_t pos) {
assert(pos < _size);
return _str[pos];
}
char& operator[](size_t pos) const {
assert(pos < _size);
return _str[pos];
}
const char* c_str() const {
return _str;
}
size_t size() const {
return _size;
}
};
} 实现功能包括:
1. 构造和析构函数
2. 基本的 [ ] 访问
3. 可供转换类型的 c_str
4. 以及容量相关的 size
我们就能先跑起来一段遍历:
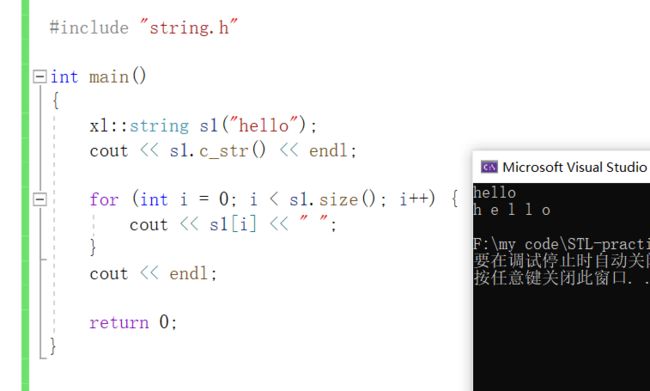
#include "string.h"
int main()
{
xl::string s1("hello");
cout << s1.c_str() << endl;
for (int i = 0; i < s1.size(); i++) {
cout << s1[i] << " ";
}
cout << endl;
return 0;
}输出:
2. 迭代器的实现
迭代器可能是指针,也可能不是,
不过在string里面,迭代器就是指针。
我们把迭代器实现到类里面,因为标准库中的迭代器,就存在类内,
我们直接通过类域就能访问到。
来看代码:
public:
typedef char* iterator;
iterator begin() {
return _str;
}
iterator end() {
return _str + _size;
}这样我们就能直接跑起来:
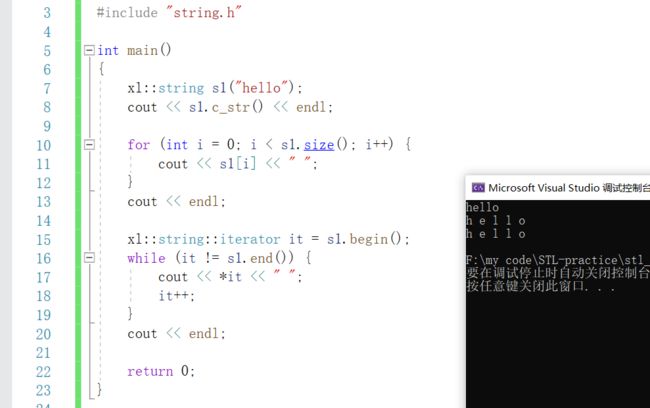
#include "string.h"
int main()
{
xl::string s1("hello");
cout << s1.c_str() << endl;
for (int i = 0; i < s1.size(); i++) {
cout << s1[i] << " ";
}
cout << endl;
xl::string::iterator it = s1.begin();
while (it != s1.end()) {
cout << *it << " ";
it++;
}
cout << endl;
return 0;
}输出:
但是啊,这样只支持了普通对象的迭代器,
还有const对象,所以我们要再实现一份:
public:
typedef char* iterator;
typedef const char* const_iterator;
iterator begin() {
return _str;
}
iterator end() {
return _str + _size;
}
const_iterator begin() const {
return _str;
}
const_iterator end() const {
return _str + _size;
}我们可以观察一下,
使用 const 迭代器确实是禁止访问了:
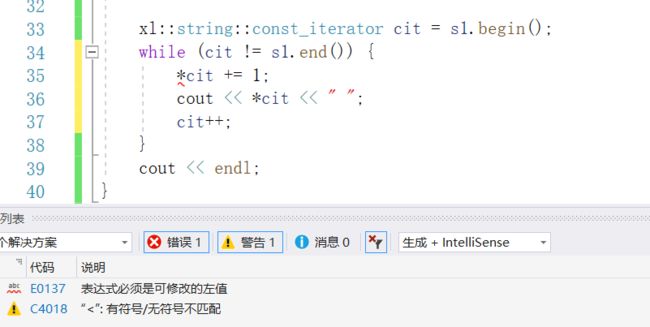
而使用普通迭代器是可以修改指向的值的:
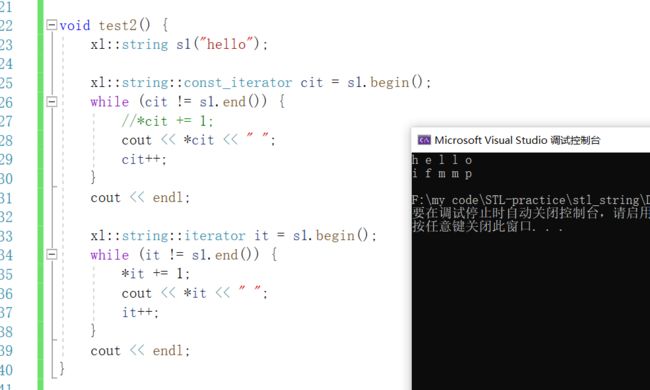
void test2() {
xl::string s1("hello");
xl::string::const_iterator cit = s1.begin();
while (cit != s1.end()) {
//*cit += 1;
cout << *cit << " ";
cit++;
}
cout << endl;
xl::string::iterator it = s1.begin();
while (it != s1.end()) {
*it += 1;
cout << *it << " ";
it++;
}
cout << endl;
}输出:
3. string的拷贝构造和赋值(深拷贝)
拷贝构造
需要新开一块空间:
string(const string& s) {
_str = new char[s._capacity + 1];
memcpy(_str, s._str, s.size() + 1);
_size = s._size;
_capacity = s._capacity;
}赋值构造
我们就直接采取删除旧空间,开辟新空间,拷贝数据的策略:
string& operator=(const string& s) {
if (this != &s) {
char* tmp = new char[s._capacity + 1];
memcpy(tmp, s._str, s._size + 1);
delete[] _str;
_str = tmp;
}
return *this;
}上面的这种中规中矩的方法,我们称之为传统写法,
那么有传统写法,当然还有现代写法,来看这种写法:
void swap(string& tmp) {
::swap(_str, tmp._str);
::swap(_size, tmp._size);
::swap(_capacity, tmp._capacity);
}
// 现代写法
string& operator=(string tmp) {
swap(tmp);
return *this;
}我们实现了一个string类内的一个swap,通过拷贝构造形成的 tmp 帮我们打工,
然后我们再通过 swap 白嫖 tmp 的内容即可。
我个人认为这种方法其实本质上就是对拷贝构造的复用。
实际上,拷贝构造也可以用现代写法:
string(const string& s)
: _str(nullptr)
, _size(0)
, _capacity(0)
{
string tmp(s._str);
swap(tmp);
}发现没有,拷贝构造的现代写法本质也是一个复用,
他复用的就是我们实现的构造函数。
4. string的增删查改
在实现那些花里胡哨的接口之前啊,
先把扩容的问题搞定再说:
reserve 接口
根据给的 n 的大小直接扩容即可:
void reserve(size_t n) {
if (n > _capacity) {
char* tmp = new char[n + 1];
memcpy(tmp, _str, _size + 1);
delete[] _str;
_str = tmp;
_capacity = n;
}
}resize 接口
还有一种扩容方法就是resize,不过string一般很少用resize,
来看实现:
void resize(size_t n, char ch = '\0') {
if (n < _size) {
_size = n;
_str[_size] = '\0';
}
else {
reserve(n);
for (size_t i = _size; i < n; i++) {
_str[i] = ch;
}
_size = n;
_str[_size] = '\0';
}
}push_back 接口
string的 push_back 就是尾插一个元素,
采取的是二倍扩容的机制(这个看个人喜好,也有1.5倍扩容的)
void push_back(char ch) {
if (_size == _capacity) {
// 2倍扩容
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size] = ch;
_size++;
_str[_size] = '\0';
}append 接口
append 是尾插一段字符串,
扩容机制我使用的是按需扩容。
void append(const char* str) {
size_t len = strlen(str);
if (_size + len > _capacity) {
// 至少扩容到 _size + len
reserve(_size + len);
}
memcpy(_str + _size, str, len + 1);
_size += len;
}当然,我们其实更喜欢使用 +=:
operator+=() 实现
当然,这个函数我们就直接复用前面实现的push_back和append就行:
string& operator+=(char ch) {
push_back(ch);
return *this;
}
string& operator+=(const char* str) {
append(str);
return *this;
}这用起来当然是爽多了:
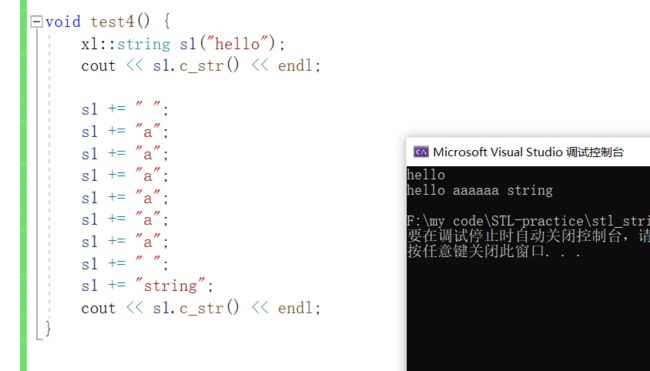
void test4() {
xl::string s1("hello");
cout << s1.c_str() << endl;
s1 += " ";
s1 += "a";
s1 += "a";
s1 += "a";
s1 += "a";
s1 += "a";
s1 += "a";
s1 += " ";
s1 += "string";
cout << s1.c_str() << endl;
}输出:
insert 接口
实际上STL的string 实现了很多比较冗余的重载,
作为学习,我们就只实现最核心的调用方法。
insert我们实现两种重载:
void insert(size_t pos, size_t n, char ch) {
}
void insert(size_t pos, const char* str) {
}先来实现第一种,插入一种字符:
void insert(size_t pos, size_t n, char ch) {
assert(pos <= _size);
if (_size + n > _capacity) {
// 至少扩容到_size + n
reserve(_size + n);
}
// 挪动数据
size_t end = _size;
while (end >= pos && end != npos) {
_str[end + n] = _str[end];
end--;
}
// 填值
for (size_t i = 0; i < n; i++) _str[pos + i] = ch;
_size += n;
}第二种,插入一个字符串:
实现方法都是相似的:
void insert(size_t pos, const char* str) {
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity) {
// 至少扩容到_size + len
reserve(_size + len);
}
// 挪动数据
size_t end = _size;
while (end >= pos && end != npos) {
_str[end + len] = _str[end];
end--;
}
// 填值
for (size_t i = 0; i < len; i++) _str[pos + i] = str[i];
_size += len;
}我们来测试一下:
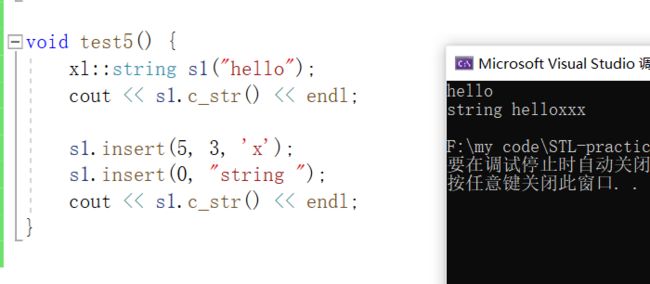
void test5() {
xl::string s1("hello");
cout << s1.c_str() << endl;
s1.insert(5, 3, 'x');
s1.insert(0, "string ");
cout << s1.c_str() << endl;
}输出:
erase 接口
如果删除的字符超过了有的字符,或者是没有说明删除的字符数,就全部删完:
void erase(size_t pos, size_t len = npos) {
assert(pos <= _size);
if (len == npos || pos + len >= _size) {
_size = pos;
_str[pos] = '\0';
}
else {
size_t end = pos + len;
while (end <= _size) {
_str[pos++] = _str[end++];
}
_size -= len;
}
}我们可以测试一下:
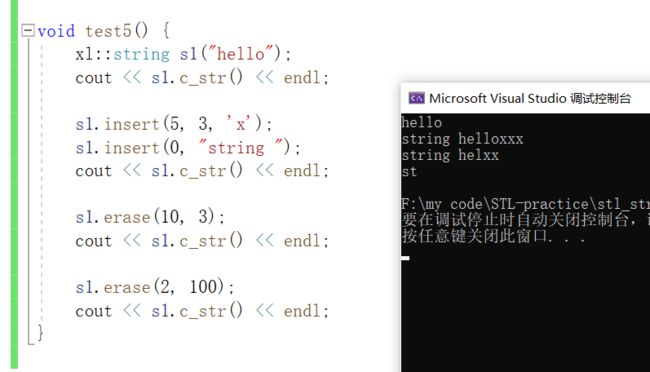
void test5() {
xl::string s1("hello");
cout << s1.c_str() << endl;
s1.insert(5, 3, 'x');
s1.insert(0, "string ");
cout << s1.c_str() << endl;
s1.erase(10, 3);
cout << s1.c_str() << endl;
s1.erase(2, 100);
cout << s1.c_str() << endl;
}
输出:
find 接口
如果是单个字符,直接找就行了:
size_t find(char ch, size_t pos = 0) {
for (size_t i = pos; i < _size; i++) {
if (_str[i] == ch) return i;
}
return npos;
}字符串的话我们用strstr暴力匹配就行:
size_t find(const char* str, size_t pos = 0) {
const char* ptr = strstr(_str + pos, str);
if (ptr) return ptr - _str;
else return npos;
}substr 接口
截取字符串的操作:
string substr(size_t pos = 0, size_t len = npos) {
assert(pos <= _size);
size_t n = len + pos;
if (len == npos || pos + len > _size) {
n = _size;
}
string tmp;
tmp.reserve(n);
for (size_t i = pos; i < n; i++) {
tmp += _str[i];
}
return tmp;
}来测试一下:
void test6() {
xl::string s1("hello string");
cout << s1.c_str() << endl;
size_t pos = s1.find('s');
cout << s1.substr(pos, 3).c_str() << endl;
pos = s1.find('s');
cout << s1.substr(pos, 100).c_str() << endl;
}
输出:

clear 接口
顺便实现一下:
void clear() {
_str[0] = '\0';
_size = 0;
}流插入和流提取
这个我们需要实现在类外,因为操作符的顺序要求,
先来看流插入:
ostream& operator<<(ostream& out, const string& s) {
for (auto e : s) cout << e;
return out;
}再来看流提取:
istream& operator>>(istream& in, string& s) {
s.clear();
char ch = in.get();
while (ch != ' ' && ch != '\n') {
s += ch;
ch = in.get();
}
return in;
}
测试时间~
void test7() {
string s1;
cin >> s1;
cout << s1 << endl;
}输出:

5. 用于比较的操作符重载函数
我们还是一样的操作,先实现两个,在复用到全部:
operator<
我们用库函数memcmp实现:
bool operator<(const string& s) {
int ret = memcmp(_str, s._str, _size < s._size ? _size : s._size);
return ret == 0 ? _size < s._size : ret < 0;
}operator==
bool operator==(const string& s) {
return memcmp(_str, s._str, _size < s._size ? _size : s._size) == 0;
}
其它复用
bool operator<=(const string& s) {
return *this < s || *this == s;
}
bool operator>(const string& s) {
return !(*this <= s);
}
bool operator>=(const string& s) {
return !(*this < s);
}
bool operator!=(const string& s) {
return !(*this == s);
}6. 源码分享
#pragma once
#include
#include
#include
#include
using namespace std;
namespace xl {
class string {
private:
char* _str;
size_t _size;
size_t _capacity;
const static size_t npos = -1; // 可以这样用,但不建议,违背了C++的语法准则(建议声明和定义分离)
public:
string(const char* str = "")
: _size(strlen(str))
, _capacity(_size)
{
_str = new char[_capacity + 1];
memcpy(_str, str, _size + 1);
}
传统写法
//string(const string& s) {
// _str = new char[s._capacity + 1];
// memcpy(_str, s._str, s._size + 1);
// _size = s._size;
// _capacity = s._capacity;
//}
// 现代写法
string(const string& s)
: _str(nullptr)
, _size(0)
, _capacity(0)
{
string tmp(s._str);
swap(tmp);
}
传统写法
//string& operator=(const string& s) {
// if (this != &s) {
// char* tmp = new char[s._capacity + 1];
// memcpy(tmp, s._str, s._size + 1);
// delete[] _str;
// _str = tmp;
// }
// return *this;
//}
void swap(string& tmp) {
::swap(_str, tmp._str);
::swap(_size, tmp._size);
::swap(_capacity, tmp._capacity);
}
// 现代写法
string& operator=(string tmp) {
swap(tmp);
return *this;
}
~string()
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
public:
typedef char* iterator;
typedef const char* const_iterator;
iterator begin() {
return _str;
}
iterator end() {
return _str + _size;
}
const_iterator begin() const {
return _str;
}
const_iterator end() const {
return _str + _size;
}
public:
void reserve(size_t n) {
if (n > _capacity) {
char* tmp = new char[n + 1];
memcpy(tmp, _str, _size + 1);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
void resize(size_t n, char ch = '\0') {
if (n < _size) {
_size = n;
_str[_size] = '\0';
}
else {
reserve(n);
for (size_t i = _size; i < n; i++) {
_str[i] = ch;
}
_size = n;
_str[_size] = '\0';
}
}
void push_back(char ch) {
if (_size == _capacity) {
// 2倍扩容
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size] = ch;
_size++;
_str[_size] = '\0';
}
void append(const char* str) {
size_t len = strlen(str);
if (_size + len > _capacity) {
// 至少扩容到 _size + len
reserve(_size + len);
}
memcpy(_str + _size, str, len + 1);
_size += len;
}
string& operator+=(char ch) {
push_back(ch);
return *this;
}
string& operator+=(const char* str) {
append(str);
return *this;
}
void insert(size_t pos, size_t n, char ch) {
assert(pos <= _size);
if (_size + n > _capacity) {
// 至少扩容到_size + n
reserve(_size + n);
}
// 挪动数据
size_t end = _size;
while (end >= pos && end != npos) {
_str[end + n] = _str[end];
end--;
}
// 填值
for (size_t i = 0; i < n; i++) _str[pos + i] = ch;
_size += n;
}
void insert(size_t pos, const char* str) {
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity) {
// 至少扩容到_size + len
reserve(_size + len);
}
// 挪动数据
size_t end = _size;
while (end >= pos && end != npos) {
_str[end + len] = _str[end];
end--;
}
// 填值
for (size_t i = 0; i < len; i++) _str[pos + i] = str[i];
_size += len;
}
void erase(size_t pos, size_t len = npos) {
assert(pos <= _size);
if (len == npos || pos + len >= _size) {
_size = pos;
_str[pos] = '\0';
}
else {
size_t end = pos + len;
while (end <= _size) {
_str[pos++] = _str[end++];
}
_size -= len;
}
}
size_t find(char ch, size_t pos = 0) {
for (size_t i = pos; i < _size; i++) {
if (_str[i] == ch) return i;
}
return npos;
}
size_t find(const char* str, size_t pos = 0) {
const char* ptr = strstr(_str + pos, str);
if (ptr) return ptr - _str;
else return npos;
}
string substr(size_t pos = 0, size_t len = npos) {
assert(pos <= _size);
size_t n = len + pos;
if (len == npos || pos + len > _size) {
n = _size;
}
string tmp;
tmp.reserve(n);
for (size_t i = pos; i < n; i++) {
tmp += _str[i];
}
return tmp;
}
public:
char& operator[](size_t pos) {
assert(pos < _size);
return _str[pos];
}
char& operator[](size_t pos) const {
assert(pos < _size);
return _str[pos];
}
bool operator<(const string& s) {
int ret = memcmp(_str, s._str, _size < s._size ? _size : s._size);
return ret == 0 ? _size < s._size : ret < 0;
}
bool operator==(const string& s) {
return _size == s._size && memcmp(_str, s._str, _size) == 0;
}
bool operator<=(const string& s) {
return *this < s || *this == s;
}
bool operator>(const string& s) {
return !(*this <= s);
}
bool operator>=(const string& s) {
return !(*this < s);
}
bool operator!=(const string& s) {
return !(*this == s);
}
const char* c_str() const {
return _str;
}
size_t size() const {
return _size;
}
void clear() {
_str[0] = '\0';
_size = 0;
}
};
ostream& operator<<(ostream& out, const string& s) {
for (auto e : s) cout << e;
return out;
}
istream& operator>>(istream& in, string& s) {
s.clear();
char ch = in.get();
while (ch != ' ' && ch != '\n') {
s += ch;
ch = in.get();
}
return in;
}
} 写在最后:
以上就是本篇文章的内容了,感谢你的阅读。
如果感到有所收获的话可以给博主点一个赞哦。
如果文章内容有遗漏或者错误的地方欢迎私信博主或者在评论区指出~