Spark(31):Spark性能调优之算子调优
目录
0. 相关文章链接
1. mapPartitions
2. foreachPartition优化数据库操作
3. filter与coalesce的配合使用
4. repartition解决SparkSQL低并行度问题
5. reduceByKey预聚合
0. 相关文章链接
Spark文章汇总
1. mapPartitions
普通的 map 算子对 RDD 中的每一个元素进行操作,而 mapPartitions 算子对 RDD 中每一个分区进行操作。如果是普通的 map 算子,假设一个 partition 有 1 万条数据,那么 map 算子中的function 要执行 1 万次,也就是对每个元素进行操作。

如果是 mapPartition 算子,由于一个 task 处理一个 RDD 的 partition,那么一个 task 只会执行一次 function,function 一次接收所有的 partition 数据,效率比较高。

比如,当要把 RDD 中的所有数据通过 JDBC 写入数据,如果使用 map 算子,那么需要对 RDD 中的每一个元素都创建一个数据库连接,这样对资源的消耗很大,如果使用 mapPartitions 算子,那么针对一个分区的数据,只需要建立一个数据库连接。
mapPartitions 算子也存在一些缺点:对于普通的 map 操作,一次处理一条数据,如果在处理了 2000 条数据后内存不足,那么可以将已经处理完的 2000 条数据从内存中垃圾回收掉;但是如果使用 mapPartitions 算子,但数据量非常大时,function 一次处理一个分区的数据,如果一旦内存不足,此时无法回收内存,就可能会 OOM,即内存溢出。
因此,mapPartitions 算子适用于数据量不是特别大的时候,此时使用 mapPartitions 算子对性能的提升效果还是不错的。(当数据量很大的时候,一旦使用 mapPartitions 算子,就会直接 OOM) 。在项目中,应该首先估算一下 RDD 的数据量、每个 partition 的数据量,以及分配给每个 Executor 的内存资源,如果资源允许,可以考虑使用 mapPartitions 算子代替 map。
2. foreachPartition优化数据库操作
在生产环境中,通常使用 foreachPartition 算子来完成数据库的写入,通过 foreachPartition 算子的特性,可以优化写数据库的性能。 如果使用 foreach 算子完成数据库的操作,由于 foreach 算子是遍历 RDD 的每条数据,因此,每条数据都会建立一个数据库连接,这是对资源的极大浪费,因此,对于写数据库操作,我们应当使用 foreachPartition 算子。
与 mapPartitions 算子非常相似,foreachPartition 是将 RDD 的每个分区作为遍历对象,一次处理一个分区的数据,也就是说,如果涉及数据库的相关操作,一个分区的数据只需要创建一次数据库连接,如图所示:

使用了 foreachPartition 算子后,可以获得以下的性能提升:
- 对于我们写的 function 函数,一次处理一整个分区的数据;
- 对于一个分区内的数据,创建唯一的数据库连接;
- 只需要向数据库发送一次 SQL 语句和多组参数;
在生产环境中,全部都会使用 foreachPartition 算子完成数据库操作。foreachPartition 算子存在一个问题,与 mapPartitions 算子类似,如果一个分区的数据量特别大,可能会造成 OOM,即内存溢出。
3. filter与coalesce的配合使用
在 Spark 任务中我们经常会使用 filter 算子完成 RDD 中数据的过滤,在任务初始阶段,从各个分区中加载到的数据量是相近的,但是一旦进过 filter 过滤后,每个分区的数据量有可能会存在较大差异,如图所示:

- 每个 partition 的数据量变小了,如果还按照之前与 partition 相等的 task 个数去处理当前数据,有点浪费 task 的计算资源;
- 每个 partition 的数据量不一样,会导致后面的每个 task 处理每个 partition 数据的时候,每个 task 要处理的数据量不同,这很有可能导致数据倾斜问题。
如上图所示,第二个分区的数据过滤后只剩100条,而第三个分区的数据过滤后剩下800条,在相同的处理逻辑下,第二个分区对应的 task 处理的数据量与第三个分区对应的 task 处理的数据量差距达到了 8 倍,这也会导致运行速度可能存在数倍的差距,这也就是数据倾斜问题。
针对上述的两个问题,我们分别进行分析:
- 针对第一个问题,既然分区的数据量变小了,我们希望可以对分区数据进行重新分配,比如将原来 4 个分区的数据转化到 2 个分区中,这样只需要用后面的两个 task 进行处理即可,避免了资源的浪费。
- 针对第二个问题,解决方法和第一个问题的解决方法非常相似,对分区数据重新分配,让每个 partition 中的数据量差不多,这就避免了数据倾斜问题。
那么具体应该如何实现上面的解决思路?我们需要 coalesce 算子。 repartition 与 coalesce 都可以用来进行重分区,其中 repartition 只是 coalesce 接口中 shuffle 为 true 的简易实现,coalesce 默认情况下不进行 shuffle,但是可以通过参数进行设置。
假设我们希望将原本的分区个数 A 通过重新分区变为 B,那么有以下几种情况:
- A > B(多数分区合并为少数分区)
- A 与 B 相差值不大 :此时使用 coalesce 即可,无需 shuffle 过程。
- A 与 B 相差值很大 :此时可以使用 coalesce 并且不启用 shuffle 过程,但是会导致合并过程性能低下,所以推荐设置 coalesce 的第二个参数为 true,即启动 shuffle 过程。
- A < B(少数分区分解为多数分区)
- 此时使用 repartition 即可,如果使用 coalesce 需要将 shuffle 设置为 true,否则 coalesce 无效。我们可以在 filter 操作之后,使用 coalesce 算子针对每个 partition 的数据量各不相同的情况,压缩 partition 的数量,而且让每个 partition 的数据量尽量均匀紧凑,以便于后面的 task 进行计算操作,在某种程度上能够在一定程度上提升性能。
注意:local 模式是进程内模拟集群运行,已经对并行度和分区数量有了一定的内部优化,因此不用去设置并行度和分区数量。
4. repartition解决SparkSQL低并行度问题
在SparkConf中设置的并行度对于Spark SQL 是不生效的,用户设置的并行度只对于 Spark SQL 以外的所有 Spark 的 stage 生效。 Spark SQL 的并行度不允许用户自己指定,Spark SQL 自己会默认根据 hive 表对应的HDFS 文件的 split 个数自动设置 Spark SQL 所在的那个 stage 的并行度,用户自己通 spark.default.parallelism 参数指定的并行度,只会在没 Spark SQL 的 stage 中生效。
由于 Spark SQL 所在 stage 的并行度无法手动设置,如果数据量较大,并且此 stage 中后续的 transformation 操作有着复杂的业务逻辑,而 Spark SQL 自动设置的 task 数量很少,这就意味着每个 task 要处理为数不少的数据量,然后还要执行非常复杂的处理逻辑,这就可能表现为第一个有 Spark SQL 的 stage 速度很慢,而后续的没有 Spark SQL 的 stage 运行速度非常快。 为了解决 Spark SQL 无法设置并行度和 task 数量的问题,我们可以使用 repartition 算子。
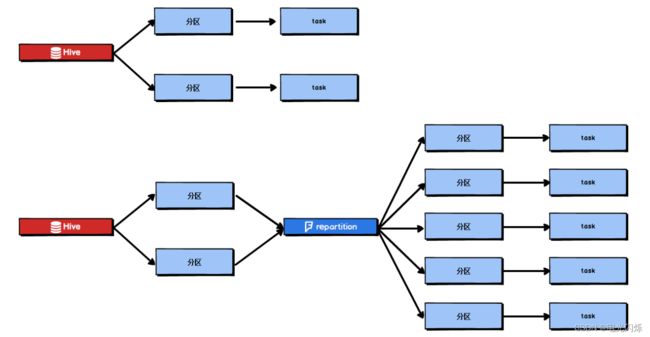
Spark SQL 这一步的并行度和 task 数量肯定是没有办法去改变了,但是,对于 Spark SQL 查询出来的 RDD,立即使用 repartition 算子,去重新进行分区,这样可以重新分区为多个partition,从 repartition 之后的 RDD 操作,由于不再设计 Spark SQL,因此 stage 的并行度就会等于你手动设置的值,这样就避免了 Spark SQL 所在的 stage 只能用少量的 task 去处理大量数据并执行复杂的算法逻辑。
5. reduceByKey预聚合
reduceByKey 相较于普通的 shuffle 操作一个显著的特点就是会进行 map 端的本地聚合,map 端会先对本地的数据进行 combine 操作,然后将数据写入给下个 stage 的每个 task 创建的文件中,也就是在 map 端,对每一个 key 对应的 value,执行 reduceByKey 算子函数。
reduceByKey 算子的执行过程如图所示:
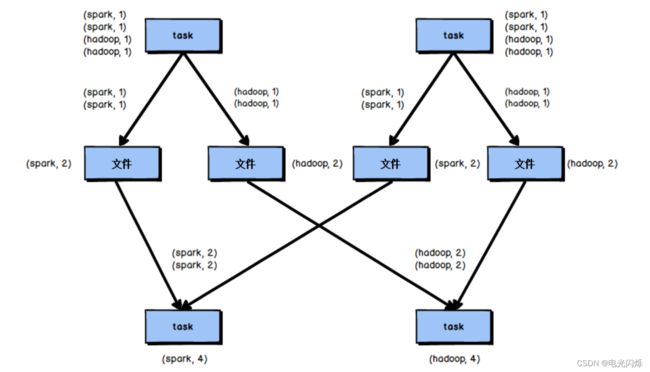
使用 reduceByKey 对性能的提升如下:
- 本地聚合后,在 map 端的数据量变少,减少了磁盘 IO,也减少了对磁盘空间的占用;
- 本地聚合后,下一个 stage 拉取的数据量变少,减少了网络传输的数据量;
- 本地聚合后,在 reduce 端进行数据缓存的内存占用减少;
- 本地聚合后,在 reduce 端进行聚合的数据量减少。
基于 reduceByKey 的本地聚合特征,我们应该考虑使用 reduceByKey 代替其他的 shuffle 算子,例如 groupByKey。reduceByKey 与 groupByKey 的运行原理如图所示:

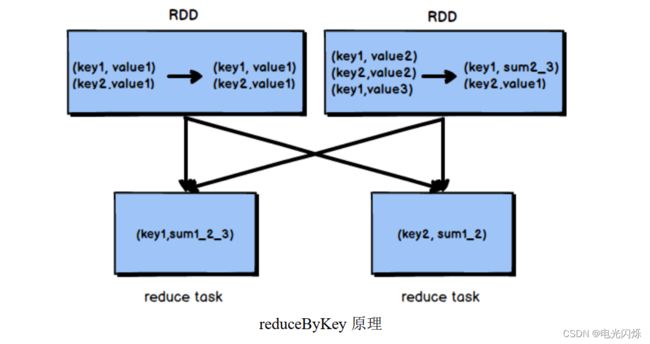
根据上图可知,groupByKey 不会进行 map 端的聚合,而是将所有 map 端的数据 shuffle 到 reduce 端,然后在 reduce 端进行数据的聚合操作。由于 reduceByKey 有 map 端聚合的特性,使得网络传输的数据量减小,因此效率要明显高于 groupByKey。
注:其他Spark相关系列文章链接由此进 -> Spark文章汇总