【算法基础】2.2 字典树/前缀树 Trie
文章目录
- 知识点
-
- cpp结构体模板
- 模板例题
-
- 835. Trie字符串统计❤️❤️❤️❤️❤️(重要!模板!)
- 143. 最大异或对(Trie树的应用)
- 相关题目练习
-
- 208. 实现 Trie (前缀树)
- 1804. 实现 Trie (前缀树) II
- 参考资料
知识点
用于高效地存储和查找字符串集合的数据结构——Trie树。
https://oi-wiki.org/string/trie/
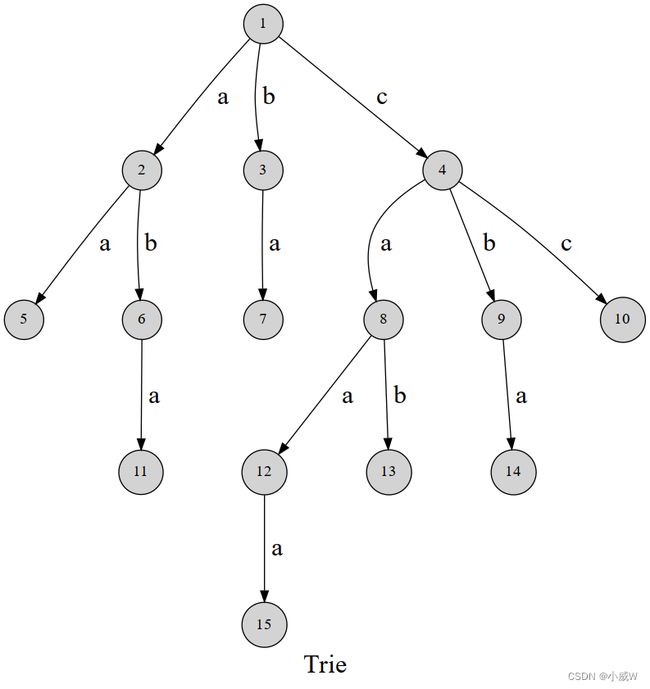
可以发现,这棵字典树用边来代表字母,而从根结点到树上某一结点的路径就代表了一个字符串。举个例子, 1 → 4 → 8 → 12 1\to4\to 8\to 12 1→4→8→12 表示的就是字符串 caa。
这类题目,字母的种类不会很多。
cpp结构体模板
struct trie {
int nex[100000][26], cnt;
bool exist[100000]; // 该结点结尾的字符串是否存在
void insert(char *s, int l) { // 插入字符串
int p = 0;
for (int i = 0; i < l; i++) {
int c = s[i] - 'a';
if (!nex[p][c]) nex[p][c] = ++cnt; // 如果没有,就添加结点
p = nex[p][c];
}
exist[p] = 1;
}
bool find(char *s, int l) { // 查找字符串
int p = 0;
for (int i = 0; i < l; i++) {
int c = s[i] - 'a';
if (!nex[p][c]) return 0;
p = nex[p][c];
}
return exist[p];
}
};
模板例题
835. Trie字符串统计❤️❤️❤️❤️❤️(重要!模板!)
https://www.acwing.com/activity/content/problem/content/883/

代码模板在于 insert 和 query 这两个方法的写法。
除此之外要理解数组 son、 cnt 和变量 idx 的含义。(含义已经写在代码注释里了)
son[][] 的第一维是可能出现的字符**数量**的最大值;第二维是可能出现的字符**种类**的最大值。
cnt[] 的大小是可能出现的字符数量的最大值,也就是记录每个节点作为了几次字符串的末尾。
idx 记录出现了几个新的节点。
import java.io.BufferedInputStream;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.*;
public class Main {
static final int N = 100010; // 所有输入的字符串总长度不超过 10^5
static int[][] son;
static int[] cnt;
static int idx; // idx递增作为节点的序号
static {
son = new int[N][26]; // 记录各个节点的儿子
cnt = new int[N]; // 记录各个节点作为结尾的次数
}
public static void main(String[] args) throws IOException {
Scanner sin = new Scanner(new BufferedInputStream(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
int n = sin.nextInt();
while (n-- > 0) {
char op = sin.next().charAt(0);
String s = sin.next();
if (op == 'I') {
insert(s.toCharArray());
} else {
System.out.println(query(s.toCharArray()));
}
}
bw.flush();
}
// 插入一个字符串
static void insert(char[] str) {
int p = 0;
for (int i = 0; i < str.length; ++i) { // 枚举每个字符
int u = str[i] - 'a';
if (son[p][u] == 0) son[p][u] = ++idx; // 如果当前层不存在u的话,新建一个节点
p = son[p][u];
}
cnt[p]++; // 作为结尾的情况+1
}
static int query(char[] str) {
int p = 0;
for (int i = 0; i < str.length; ++i) {
int u = str[i] - 'a';
if (son[p][u] == 0) return 0;
p = son[p][u];
}
return cnt[p];
}
}
143. 最大异或对(Trie树的应用)
https://www.acwing.com/problem/content/145/
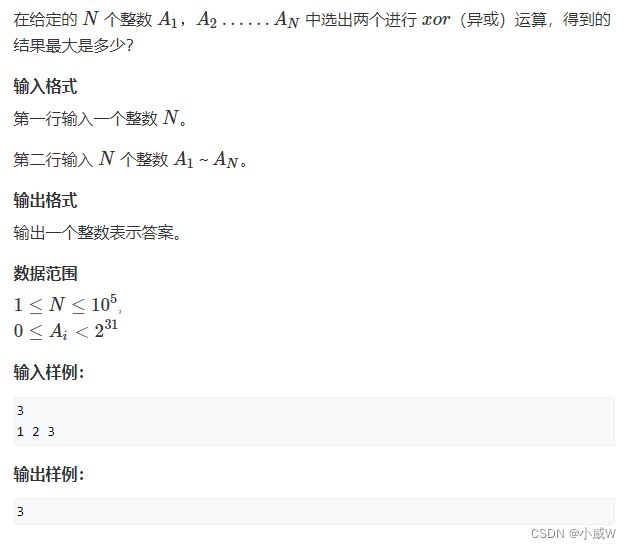
异或运算:相同得 0 ,不同得 1。(俗称不进位加法)
从高位开始比较。
检查到有反的,就可以 += 1 << i;
import java.util.Scanner;
public class Main {
final static int M = 31 * 100010; // M 是 Trie树中最多可能的节点数量
static int[][] son = new int[M][2];
static int idx = 0;
public static void main(String[] args){
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt(), ans = 0;
for (int i = 0; i < n; ++i) {
int a = scanner.nextInt();
ans = Math.max(find(a), ans);
insert(a);
}
System.out.println(ans);
}
// 从高位到低位插入
public static void insert(int x) {
int p = 0;
for (int i = 30; i >= 0; --i) {
int u = x >> i & 1;
if (son[p][u] == 0) son[p][u] = ++idx;
p = son[p][u];
}
}
public static int find(int x) {
int p = 0, res = 0;
for (int i = 30; i >= 0; --i) {
int u = x >> i & 1; // 获得当前位
if (son[p][u ^ 1] != 0) { // 检查当前位有没有取反的
res += 1 << i;
p = son[p][u ^ 1];
} else p = son[p][u];
}
return res;
}
}
相关题目练习
208. 实现 Trie (前缀树)
https://leetcode.cn/problems/implement-trie-prefix-tree/
提示:
1 <= word.length, prefix.length <= 2000
word 和 prefix 仅由小写英文字母组成
insert、search 和 startsWith 调用次数 总计 不超过 3 * 10^4 次
一道练习Trie树模板的题目。
class Trie {
final int N = 200001 + 1;
int[][] son = new int[N][26];
int[] cnt = new int[N];
int idx = 0;
public Trie() {
}
public void insert(String word) {
int p = 0;
for (char ch: word.toCharArray()) {
int u = ch - 'a';
if (son[p][u] == 0) son[p][u] = ++idx;
p = son[p][u];
}
++cnt[p];
}
public boolean search(String word) {
int p = 0;
for (char ch: word.toCharArray()) {
int u = ch - 'a';
if (son[p][u] == 0) return false;
p = son[p][u];
}
return cnt[p] > 0;
}
public boolean startsWith(String prefix) {
int p = 0;
for (char ch: prefix.toCharArray()) {
int u = ch - 'a';
if (son[p][u] == 0) return false;
p = son[p][u];
}
return true;
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/
1804. 实现 Trie (前缀树) II
1804. 实现 Trie (前缀树) II
提示:
1 <= word.length, prefix.length <= 2000
word 和 prefix 只包含小写英文字母。
insert、 countWordsEqualTo、 countWordsStartingWith 和 erase 总共调用最多 3 * 10^4 次。
保证每次调用 erase 时,字符串 word 总是存在于前缀树中。
相比上一题,多开一个数组 cnt2 记录一下各个节点被经过了多少次就好了。
class Trie {
int[][] son = new int[30000][26];
int[] cnt = new int[30000], cnt2 = new int[30000];
int idx = 0;
public Trie() {
}
public void insert(String word) {
int p = 0;
for (char ch: word.toCharArray()) {
int u = ch - 'a';
if (son[p][u] == 0) son[p][u] = ++idx;
p = son[p][u];
cnt2[p]++;
}
cnt[p]++;
}
public int countWordsEqualTo(String word) {
int p = getP(word);
return cnt[p];
}
public int countWordsStartingWith(String prefix) {
int p = getP(prefix);
return cnt2[p];
}
public void erase(String word) {
int p = 0;
for (char ch: word.toCharArray()) {
int u = ch - 'a';
p = son[p][u];
cnt2[p]--;
}
cnt[p]--;
}
public int getP(String s) {
int p = 0;
for (char ch: s.toCharArray()) {
int u = ch - 'a';
if (son[p][u] != 0) p = son[p][u];
else return 0;
}
return p;
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* int param_2 = obj.countWordsEqualTo(word);
* int param_3 = obj.countWordsStartingWith(prefix);
* obj.erase(word);
*/
参考资料
https://oi-wiki.org/string/trie/