使用Docker Swarm部署RabbitMQ+HAProxy高可用集群(三节点-镜像模式)
1. 部署规划
当前规划中,只启动一个HAProxy服务,主要用来做RabbitMQ节点的负载均衡和代理,但是HAProxy可能会出现单点故障,后续需要启动多个HAProxy节点,然后结合Keepalived来进行 设置虚拟IP 做故障转移
| 节点名称 | 节点主机名 | IP地址 | 角色 | 运行服务 |
|---|---|---|---|---|
| cluster01 | cluster01 | 192.168.12.48 | Docker Swarm Manager & Node | HAProxy & RabbitMQ-Node01 |
| cluster01 | cluster02 | 192.168.12.49 | Docker Swarm Manager & Node | RabbitMQ-Node02 |
| cluster01 | cluster03 | 192.168.12.50 | Docker Swarm Manager & Node | RabbitMQ-Node02 |
下面部署文档中,需要执行的指令所在节点,将会说明在以上规划的某个节点执行,均已节点名称代替。
2. 安装Docker和Docker Swarm
安装Docker和Docker Swarm。Docker是用于构建、发布和运行容器化应用程序的开源工具,而Docker Swarm是Docker的一种编排和集群管理方式,用于实现容器化应用程序的高可用性和负载均衡。
需要多节点,那么在多个节点上安装Docker和Docker Swarm
可以通过以下命令来安装Docker和Docker Swarm
- 在
cluster01、cluster02、cluster03节点执行
# 安装Docker
$ curl -sSL https://get.docker.com/ | sh
# 启动Docker
$ systemctl start docker
# 安装Docker Swarm
$ docker pull swarm:latest
3. 创建Docker Swarm集群
创建Docker Swarm集群。Docker Swarm集群由一组Docker主机组成,其中有一台主机作为管理节点,其它主机作为工作节点。
3.1. 创建Docker Swarm集群
如果配置多节点,需要在多个节点创建Docker Swarm集群
在
cluster01节点执行
# 创建Docker Swarm管理节点
$ docker swarm init \
--advertise-addr=192.168.12.48
- 执行输出如下:

注意:三个节点我们都规划成了manager管理节点并且充当node节点,也会为了访问单点故障,所以下面执行的指令,我们将不通过已经指令执行,我们通过获取manager的加入指令来操作
在
cluster01节点执行
$ docker swarm join-token manager
# 将指令的输出结果复制,将作为后续其他cluster02、cluster03的加入操作指令

3.2. 将工作节点加入Docker Swarm集群
复制上面通过docker swarm join-token manager管理节点的初始化输出指令
在
cluster02、cluster03节点执行
# 创建Docker Swarm其他管理节点
$ docker swarm join \
--token=TOKEN MANAGER_IP:2377
3.3. 查看集群运行状态
# 查询Docker Swarm集群的状态
$ docker node ls
- 以下输出则表示Docker Swarm 3个节点均已成功加入集群,三个管理节点,其中
cluster01为主节点

4. 创建共享数据持久化卷
共享存储卷,可以使用外部NFS做为共享卷来存储服务的持久化数据,也是可以Docker Swarm的本地volume卷来存储数据,这里两种方式都有具体操作,但是建议使用本地volume来存储。
下面所有步骤关于共享卷的使用,本文档选择本地Volume的方式,其他方式可以自行配置即可。
4.1. 创建共享存储卷 - local
Docker Swarm 的共享存储卷功能会自动在集群中的多个节点之间分布共享存储卷的数据,并保证数据的一致性和可用性。它内部使用了分布式文件系统来存储数据,并提供一个统一的接口,让容器可以访问存储卷中的数据。
具体来说,Docker Swarm 会在集群中的每个节点上创建一个存储卷的副本,并使用复制策略来保证每个副本中的数据都是一致的。这样,当容器在某个节点上进行写操作时,Docker Swarm 会自动将写操作同步到其它节点的副本中,保证数据的一致性。同时,Docker Swarm 还会监控每个存储卷的状态,如果某个存储卷的副本出现故障,Docker Swarm 会自动在其它节点上创建新的副本,以保证存储卷的可用性。
总之,Docker Swarm 的共享存储卷功能可以方便地解决容器之间共享数据的问题,并保证数据的安全性和可用性。
4.1.1. 使用 Docker 命令行工具创建共享存储卷 - RabbitMQ
在
cluster01、cluster02、cluster03节点执行
# 初始化一个本地目录做数据共享
$ mkdir -p /data/rabbitmq-data
# 执行挂载挂载映射指令
$ docker volume create --driver local \
--opt type=none \
--opt device=/data/rabbitmq-data \
--opt o=bind \
cluster<01、02、03>-rabbitmq-data
上面的命令将创建一个名为 cluster<01、02、03>-rabbitmq-data 的共享存储卷,并将它挂载到本地主机的 /data/rabbitmq-data 目录
这里要注意,cluster<01、02、03>-rabbitmq-data 中的<01、02、03> 为节点的名称,为了方便管理查看,可以自行替换
5. 创建节点间通信共享overlay网络
5.1. 创建服务共享网络
这里的 rabbitmq_network 为三个节点直接共享所使用的网络名称,分别为三个服务创建单独通信的网络,后续将会使用这个网络节点之间的网络通信,名称可以自定义,但后续在创建服务时需要查询使用
在
cluster01节点执行
- 创建rabbitmq服务使用网络
$ docker network create -d overlay --attachable rabbitmq_network
6. 创建RabbitMQ服务
6.1. 拉取RabbitMQ镜像
在
cluster01、cluster02、cluster03节点执行
$ docker pull rabbitmq:3.11-management
6.2. 创建RabbitMQ服务
6.2.1. 在cluster01节点创建RabbitMQ服务
使用 docker run 命令来创建一个运行 RabbitMQ 的服务,是否配置参数如下:
| 配置参数 | 配置值 | 解析 |
|---|---|---|
| –name | rabbitmq-node01 | 指定容器服务启动的名称 |
| –hostname | rabbitmq-node01 | 指定服务的主机名称 |
| -v | cluster01-rabbitmq-data:/var/lib/rabbitmq | 指定本地映射目录,将cluster01-rabbitmq-data的本地volume卷映射到容器内部/var/lib/rabbitmq目录作为数据存储目录使用【cluster01-rabbitmq-data就是上面给rabbitmq所创建的卷名称】 |
| -p | 5672:5672 | 指定服务映射端口,表示宿主机端口:内部容器服务端口,这里是宿主机5672映射到容器的5672端口,此端口为RabbitMQ的对外服务连接端口 |
| -p | 15672:15672 | 指定服务映射端口,表示宿主机端口:内部容器服务端口,这里是宿主机15672映射到容器的15672端口,此端口为RabbitMQ管理控制台访问端口 |
| -e RABBITMQ_DEFAULT_USER | admin | 指定RabbitMQ服务启动后所创建的默认用户 |
| -e RABBITMQ_DEFAULT_PASS | admin | 指定RabbitMQ服务启动后所创建的默认用户的默认密码 |
| -e RABBITMQ_ERLANG_COOKIE | rabbitmqcookie | 指定集群节点间通信认证密钥,同属于一个集群,需要所有服务器启动时配置值都保持一致才可以正常加入到一个集群 |
| –network | rabbitmq_network | 指定容器服务所使用的网络【rabbitmq_network就是上面给rabbitmq通信所创建的网络】 |
在
cluster01节点执行
$ docker run -d \
--hostname rabbitmq-node01 \
--name rabbitmq-node01 \
-e RABBITMQ_ERLANG_COOKIE="rabbitcookie" \
-e RABBITMQ_DEFAULT_USER="admin" \
-e RABBITMQ_DEFAULT_PASS="admin" \
-v cluster01-rabbitmq-data:/var/lib/rabbitmq \
-p 5672:5672 \
-p 15672:15672 \
--net=rabbitmq_network \
rabbitmq:3.11-management
- 查看服务信息
通过指令查看rabbitmq-node01的容器服务是否正常启动
# 查看rabbitmq-node01服务的所有配置信息
$ docker inspect rabbitmq-node01
可以通过以上指令来查询rabbitmq-node01的所分配的rabbitmq_network内网地址及其他相关信息
- 确认rabbitmq服务正常启动
通过浏览器访问cluster01节点15672端口查看服务状态

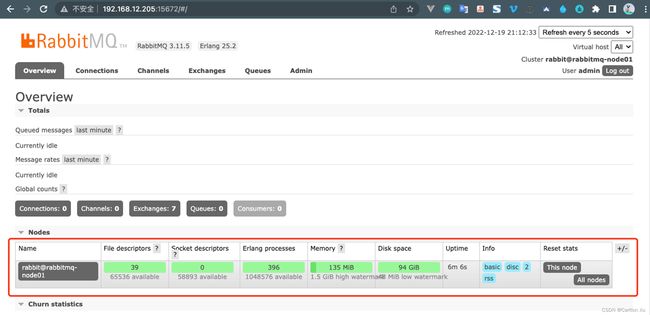
通过RabbitMQ管理页面查看,可以确认rabbitmq-node01节点一服务启动正常
6.2.2. 在cluster02节点创建RabbitMQ服务
使用 docker run 命令来创建一个运行 RabbitMQ 的服务,是否配置参数如下:
| 配置参数 | 配置值 | 解析 |
|---|---|---|
| –name | rabbitmq-node02 | 指定容器服务启动的名称 |
| –hostname | rabbitmq-node02 | 指定服务的主机名称 |
| -v | cluster02-rabbitmq-data:/var/lib/rabbitmq | 指定本地映射目录,将cluster02-rabbitmq-data的本地volume卷映射到容器内部/var/lib/rabbitmq目录作为数据存储目录使用【cluster01-rabbitmq-data就是上面给rabbitmq所创建的卷名称】 |
| -p | 5672:5672 | 指定服务映射端口,表示宿主机端口:内部容器服务端口,这里是宿主机5672映射到容器的5672端口,此端口为RabbitMQ的对外服务连接端口 |
| -p | 15672:15672 | 指定服务映射端口,表示宿主机端口:内部容器服务端口,这里是宿主机15672映射到容器的15672端口,此端口为RabbitMQ管理控制台访问端口 |
| -e RABBITMQ_ERLANG_COOKIE | rabbitmqcookie | 指定集群节点间通信认证密钥,同属于一个集群,需要所有服务器启动时配置值都保持一致才可以正常加入到一个集群 |
| –network | rabbitmq_network | 指定容器服务所使用的网络【rabbitmq_network就是上面给rabbitmq通信所创建的网络】 |
在
cluster02节点执行
$ docker run -d \
--hostname rabbitmq-node02 \
--name rabbitmq-node02 \
-e RABBITMQ_ERLANG_COOKIE="rabbitcookie" \
-v cluster02-rabbitmq-data:/var/lib/rabbitmq \
-p 5672:5672 \
-p 15672:15672 \
--net=rabbitmq_network \
rabbitmq:3.11-management
- 查看服务信息
通过指令查看rabbitmq-node02的容器服务是否正常启动
# 查看rabbitmq-node02服务的所有配置信息
$ docker inspect rabbitmq-node02
可以通过以上指令来查询rabbitmq-node02的所分配的rabbitmq_network内网地址及其他相关信息
确认RabbitMQ服务正常启动
6.2.3. 在cluster03节点创建RabbitMQ服务
使用 docker run 命令来创建一个运行 RabbitMQ 的服务,是否配置参数如下:
| 配置参数 | 配置值 | 解析 |
|---|---|---|
| –name | rabbitmq-node03 | 指定容器服务启动的名称 |
| –hostname | rabbitmq-node03 | 指定服务的主机名称 |
| -v | cluster03-rabbitmq-data:/var/lib/rabbitmq | 指定本地映射目录,将cluster03-rabbitmq-data的本地volume卷映射到容器内部/var/lib/rabbitmq目录作为数据存储目录使用【cluster01-rabbitmq-data就是上面给rabbitmq所创建的卷名称】 |
| -p | 5672:5672 | 指定服务映射端口,表示宿主机端口:内部容器服务端口,这里是宿主机5672映射到容器的5672端口,此端口为RabbitMQ的对外服务连接端口 |
| -p | 15672:15672 | 指定服务映射端口,表示宿主机端口:内部容器服务端口,这里是宿主机15672映射到容器的15672端口,此端口为RabbitMQ管理控制台访问端口 |
| -e RABBITMQ_ERLANG_COOKIE | rabbitmqcookie | 指定集群节点间通信认证密钥,同属于一个集群,需要所有服务器启动时配置值都保持一致才可以正常加入到一个集群 |
| –network | rabbitmq_network | 指定容器服务所使用的网络【rabbitmq_network就是上面给rabbitmq通信所创建的网络】 |
在
cluster02节点执行
$ docker run -d \
--hostname rabbitmq-node03 \
--name rabbitmq-node03 \
-e RABBITMQ_ERLANG_COOKIE="rabbitcookie" \
-v cluster03-rabbitmq-data:/var/lib/rabbitmq \
-p 5672:5672 \
-p 15672:15672 \
--net=rabbitmq_network \
rabbitmq:3.11-management
- 查看服务信息
通过指令查看rabbitmq-node03的容器服务是否正常启动
# 查看rabbitmq-node03服务的所有配置信息
$ docker inspect rabbitmq-node03
可以通过以上指令来查询rabbitmq-node03的所分配的rabbitmq_network内网地址及其他相关信息
确认RabbitMQ服务正常启动
7. 加入RabbitMQ集群
内存节点和磁盘节点的选择:
每个RabbitMQ节点,要么是内存节点,要么是磁盘节点。
内存节点:将所有的队列、交换器、绑定、用户等元数据定义都存储在内存中;
磁盘节点:将元数据存储在磁盘中。
单节点系统只允许磁盘类型的节点,否则当节点重启以后,所有的配置信息都会丢失。
如果采用集群的方式,可以选择至少配置一个节点为磁盘节点,其余部分配置为内存节点,这样可以获得更快的响应。所以本集群中配置节点1为磁盘节点,cluster02和cluster03为内存节点。
集群中的第一个节点将初始元数据代入集群中,并且无须被告知加入。而第2个和之后加入的节点将加入它并获取它的元数据。要加入节点,需要进入Docker容器,重启RabbitMQ。
7.1. 在cluster01节点执行初始化
在
cluster01节点执行
$ docker exec -ti rabbitmq-node01 bash
$ rabbitmqctl stop_app
$ rabbitmqctl reset
$ rabbitmqctl start_app
7.2. 在cluster02节点执行加入操作
在
cluster02节点执行
$ docker exec -ti rabbitmq-node02 bash
$ rabbitmqctl stop_app
$ rabbitmqctl reset
$ rabbitmqctl join_cluster --ram rabbit@rabbitmq-node01
$ rabbitmqctl start_app
7.3. 在cluster03节点执行加入操作
在
cluster03节点执行
$ docker exec -ti rabbitmq-node03 bash
$ rabbitmqctl stop_app
$ rabbitmqctl reset
$ rabbitmqctl join_cluster --ram rabbit@rabbitmq-node01
$ rabbitmqctl start_app
8. 配置RabbitMQ镜像队列
- 配置镜像队列
镜像队列工作原理:在非镜像队列的集群中,消息会路由到指定的队列。当配置为镜像队列之后,消息除了按照路由规则投递到相应的队列外,还会投递到镜像队列的拷贝。也可以想象在镜像队列中隐藏着一个fanout交换器,将消息发送到镜像的队列的拷贝。
进入任意一个RabbitMQ节点,执行如下命令:
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
可以设置镜像队列,"^"表示匹配所有队列,即所有队列在各个节点上都会有备份。在集群中,只需要在一个节点上设置镜像队列,设置操作会同步到其他节点。
查看集群的状态:
rabbitmqctl cluster_status
9. 检查RabbitMQ集群状态
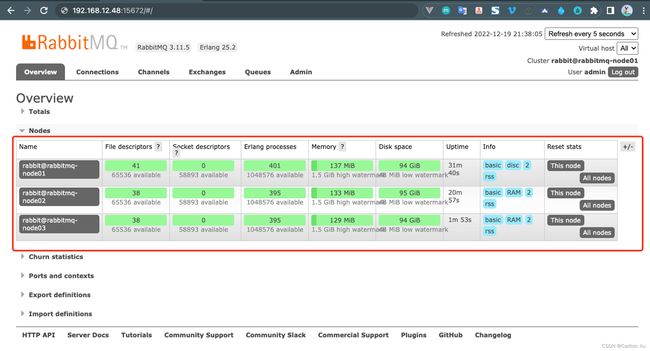
完成以上cluster01、cluster02、cluster03三个节点的RabbitMQ服务的启动和集群的配置。
所有节点设置完成之后,在浏览器访问cluster01、cluster02和cluster03中任意一个节点的15672端口,都会看到RabbitMQ集群已经创建成功。
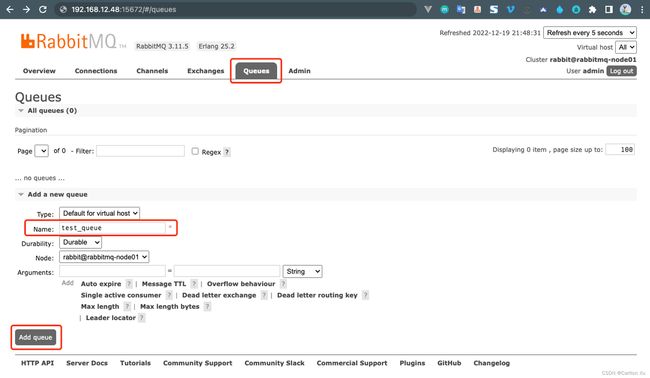
- 新建立一个队列服务,查看是否已经为镜像队列模式
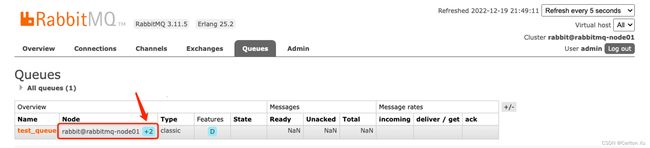
如图所示则表示集群已经开启了镜像队列模式,所有的对接消息将在其他节点都存在一份,访问任何一个节点都可以,而且他们直接数据都是同步的。
10. 配置HAProxy服务
三个节点的RabbitMQ服务集群正常之后,已经完成高可用配置,但是在使用过程中,不能让使用RabbitMQ的程序连接三个地址,所以我们还需要一个代理服务器,来配置代理转发做到负载均衡,在使用中客户端只需要连接代理服务器的地址,由代理服务器根据策略来负责分发到后台的三个节点进行数据库的访问,而且可以持续监测后台三个RabbitMQ服务的状态,如果某一个节点挂掉之后,自动负载到其他可用节点。上线之后重新加入到集群,并持续监听,来实现负载均衡高可用。
做代理服务可以有多种选,例如:HAProxy、Nginx都可以实现,这里我们选择HAProxy来实现代理服务,其他配置实现可以自定查阅相关资料来配置。
10.1. 拉取HAProxy镜像
这里我们选择最新的HAProxy的镜像,版本为2.7.0 ,其他版本可以通过访问 https://haproxy.org 来获取
具体版本:HAProxy version 2.7.0-437fd28 2022/12/01
在
cluster01节点执行
目前只在一个节点HAProxy服务,会存在一个单点故障的问题,由于所有客户端都会通过HAProxy来转发到后端服务,所以后续将结合Keepalived来实现高可用。
$ docker pull haproxy:latest
10.2. 配置HAProxy配置文件
HAProxy镜像服务内部没有配置文件,需要在容器启动之前将haproxy.cfg配置文件按照需要配置完成,再启动服务时映射到容器内部使用
在
cluster01节点执行
10.2.1. 创建一个宿主机映射配置文件目录
$ mkdir -p /data/haproxy
10.2.2. 编写HAProxy配置文件
配置文件中,需要修改的内容主要是 listen proxy-rabbitmq 段,这里需要将RabbitMQ的三个节点的RabbitMQ地址进行配置,具体IP地址为容器的内部地址,可以在每个节点通过**docker inspect rabbitmq-node<01/02/03>**来获取,IP地址获取后配置到文件中即可,其他haproxy的配置参数,也可以根据具体环境来进行配置。
这里配置的负载模式为:roundrobin,轮训算法,可以根据实际环境自行配置其他模式即可
在
cluster01节点执行
$ vim /data/haproxy/haproxy.cfg
# ---- 配置文件内容如下 ----
global
#日志文件,使用rsyslog服务中local5日志设备(/var/log/local5),等级info
log 127.0.0.1 local5 info
#守护进程运行
daemon
defaults
log global
mode http
#日志格式
option httplog
#日志中不记录负载均衡的心跳检测记录
option dontlognull
#连接超时(毫秒)
timeout connect 5000
#客户端超时(毫秒)
timeout client 50000
#服务器超时(毫秒)
timeout server 50000
#监控界面
listen admin_stats
#监控界面的访问的IP和端口
bind 0.0.0.0:8888
#访问协议
mode http
#URI相对地址
stats uri /dbs
#统计报告格式
stats realm Global\ statistics
#登陆帐户信息, 用于web浏览器的访问用户名密码
stats auth admin:root123.
#数据库负载均衡
listen proxy-rabbitmq
#访问的IP和端口
bind 0.0.0.0:5672
#网络协议
mode tcp
#负载均衡算法(轮询算法)
#轮询算法:roundrobin
#权重算法:static-rr
#最少连接算法:leastconn
#请求源IP算法:source
balance roundrobin
#日志格式
option tcplog
#inter 每隔五秒对mq集群做健康检查,2次正确证明服务器可用,2次失败证明服务器不可用,并且配置主备机制
#weight 表示权重都为1,三个节点平均分配资源
#maxconn 2000,每个节点最大连接2000
server RabbitMQ-Node01 10.0.13.23:5672 check weight 1 maxconn 2000 inter 5000 rise 2 fall 2
server RabbitMQ-Node02 10.0.13.26:5672 check weight 1 maxconn 2000 inter 5000 rise 2 fall 2
server RabbitMQ-Node03 10.0.13.6:5672 check weight 1 maxconn 2000 inter 5000 rise 2 fall 2
#使用keepalive检测死链
option tcpka
10.3. 创建HAProxy服务
使用 docker run 命令来创建一个运行 HAProxy 的服务,是否配置参数如下:
| 配置参数 | 配置值 | 解析 |
|---|---|---|
| -p | 4001:8888 | 指定服务映射端口,表示宿主机端口:内部容器服务端口,这里是宿主机4001映射到容器的8888端口,这个端口后续用来访问haproxy服务的浏览器可视化监控页面 |
| -p | 4002:5672 | 指定服务映射端口,表示宿主机端口:内部容器服务端口,这里是宿主机4002映射到容器的5672端口,这个端口主要对外客户端访问外部端口,通过这个端口转发至容器内部来访问后端的3个RabbitMQ集群。 |
| -v | /data/haproxy:/usr/local/etc/haproxy | 指定本地映射目录,将/data/haproxy的本地目录映射到容器内部/usr/local/etc/haproxy目录作为haproxy的配置文件目录使用 |
| –name | haproxy | 指定容器服务启动的名称 |
| –network | rabbitmq_network | 指定容器服务所使用的网络【rabbitmq_network就是上面给rabbitmq通信所创建的网络】 |
在
cluster01节点执行
$ docker run -d \
-p 4001:8888 \
-p 4002:5672 \
-v /data/haproxy:/usr/local/etc/haproxy \
--name=haproxy \
--net=rabbitmq_network \
--privileged \
haproxy:latest
这里如何HAProxy服务分别转发两个不同网络的服务,那么启动HAProxy容器时,需要给HAProxy服务附加多个网络,由于在直接使用docker run指令是只能指定一个网络,所以可以再绑定一个网络之后启动后,再通过docker network connect <网络> <哪个服务>来进行附加。如果使用了docker-compose.yaml方式,则可以直接为容器服务指定多个网络。
11. 测试HAProxy服务功能
HAProxy服务启动后,可以通过访问cluster01节点宿主机的http://:4001/dbs来访问HAProxy服务的浏览器可视化监控页面来查看后端RabbitMQ服务的监测及数据转发负责情况,通过页面可以看到目前后端的节点数量以及状态是否正常等相关信息。

12. 配置其他应用程序访问RabbitMQ服务
截止到当前,RabbitMQ+HAProxy实现的高可用负载集群就配置完成,那么内部及外部其他应用客户端可以访问HAProxy服务的对外地址及端口来访问后端的RabbitMQ服务。
外部服务访问地址:192.168.12.48 4002 端口,即可访问到数据库,后面就由HAProxy来根据配置的轮训算法来转发到后端的三台RabbitMQ服务 (192.168.12.48 为cluster01节点宿主机的IP地址)