如何使用Dom4J解析XML文档
文章目录
- XML解析的方式
- 使用Dom4J解析XML文档
- Dom4J结合XPath解析XML
最近在手写MyBatis的源码,在写到XMLConfigBuilder的时候,其中要解析xml文件构建Configuration。在MyBatis的早期版本中使用了DOM4J来解析配置文件和映射文件。但是从3.x版本开始,MyBatis已经切换到使用XPath解析器(XPathParser,其底层依赖的JAXP),不再使用重量级的DOM4J。
XML解析的方式
XML常见的两种解析方式:
-
DOM: 要求解析器将整个XML文件全部加载到内存中,生成一个Document对象- 优点:元素和元素之间保留结构、关系,可以针对元素进行增删查改操作
- 缺点:如果XML文件过大,可能会导致内存溢出
-
SAX:是一种速度更快,更加高效的解析方式。它是逐行扫描,边扫描边解析,并且以事件驱动的方式来进行具体的解析,每解析一行都会触发一个事件- 优点: 不会出现内存溢出的问题,可以处理大文件
- 缺点:只能读,不能写
概念辨析:
- 解析器就是根据不同的解析方式提供具体的实现。
- 为了方便开发人员来解析XML,有一些方便操作的类库。例如Dom4j其中就包含了很多解析器。
使用Dom4J解析XML文档
依赖:
<dependency>
<groupId>org.dom4jgroupId>
<artifactId>dom4jartifactId>
<version>2.1.3version>
dependency>
使用方法:
- 创建解析器对象
- 使用解析器对象读取XML文档生成Document对象
- 根据Document对象获取XML的元素(标签)
常用的方法:

我们来看一段代码:
xml文件
<contactList>
<contact id="1" vip="true">
<name> 张三 name>
<gender>女gender>
<email>[email protected]email>
contact>
<contact id="2" vip="false">
<name>李四name>
<gender>男gender>
<email>[email protected]email>
contact>
<contact id="3" vip="false">
<name>王五name>
<gender>男gender>
<email>[email protected]email>
contact>
<user>
user>
contactList>
测试代码:
public class Dom4jParseTest {
public static void main(String[] args) throws FileNotFoundException, DocumentException {
InputStream xmlFile = Dom4jParseTest.class.getClassLoader().getResourceAsStream("Contacts.xml");
//创建解析器对象
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(xmlFile);
// 获取根元素对象
Element root = document.getRootElement();
//获取根元素名字
System.out.println("root.getName() ---> " + root.getName());
// 4、拿根元素下的全部子元素对象(一级)
// List sonEles = root.elements();
List<Element> sonEles = root.elements("contact");
for (Element sonEle : sonEles) {
System.out.println("sonEle.getName() ---> " + sonEle.getName());
}
// 拿某个子元素
Element userEle = root.element("user");
System.out.println("userEle.getName() ---> " + userEle.getName());
// 默认提取第一个子元素对象 (Java语言。)
Element contact = root.element("contact");
// 获取子元素文本
System.out.println("contact.elementText('name') ---> " + contact.elementText("name"));
// 去掉前后空格
System.out.println("contact.elementTextTrim('name') ---> " + contact.elementTextTrim("name"));
// 获取当前元素下的子元素对象
Element email = contact.element("email");
System.out.println("email.getText() ---> " + email.getText());
// 去掉前后空格
System.out.println("email.getTextTrim() ---> " + email.getTextTrim());
// 根据元素获取属性值
Attribute idAttr = contact.attribute("id");
System.out.println(idAttr.getName() + "-->" + idAttr.getValue());
// 直接提取属性值
System.out.println("contact.attributeValue('id') ---> " + contact.attributeValue("id"));
System.out.println("contact.attributeValue('vip') ---> " + contact.attributeValue("vip"));
}
}
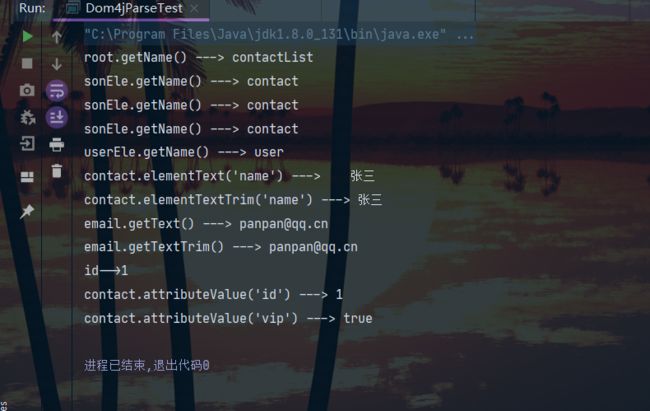
结果:
Dom4J结合XPath解析XML
XPath使用路径表达式来定位XML文档中的元素节点或属性节点
依赖:
<dependency>
<groupId>jaxengroupId>
<artifactId>jaxenartifactId>
<version>1.1.6version>
dependency>
常见的方法:

解释一下这里的Node:
在dom4j中,Node是通用的节点抽象,他有几个具体的实现类:
- Element - 代表具体的XML元素
- Attribute - 表示元素的属性
- Text - 表示文本信息
- CDATA - 表示CDATA块
- Entity - 表示实体
- Comment - 表示注释
- Document - 表示整个文档
我们举几个例子:
-
Element - 代表一个XML元素
<student> <name>Tomname> student>上例中,
-
Attribute - 元素的属性
<student gender="male"> <name>Tomname> student>上例中,gender="male"可以表示为一个Attribute节点。
-
Text - 元素中的文本内容
<name>Tomname> -
CDATA - CDATA块内容
<desc>desc>上例中的
可以表示为一个CDATA节点。 -
Comment - 注释内容
上述注释可以表示为一个Comment节点。
-
Document - 代表整个XML文档
表达式:
-
绝对路径:
/根元素/子元素/孙元素。采用绝对路径获取从根节点开始逐层的查找节点列表并返回信息。从根元素开始,一级一级向下查找,不能跨级。 -
相对路径:
./子元素/孙元素。先得到当前节点,再采用相对路径获取下一级节点的子节点并返回信息。从当前元素开始,一级一级向下查找,不能跨级。 -
全文检索:直接全文搜索所有的指定元素并返回

-
属性查找:在全文中搜索属性,或者带属性的元素

接下来我们还是看一段代码:
xml文件:
<contactList>
<contact id="1" vip="true">
<name> 潘金莲 name>
<gender>女gender>
<email>[email protected]email>
contact>
<contact id="2" vip="false">
<name>武松name>
<gender>男gender>
<email>[email protected]email>
contact>
<contact id="3" vip="false">
<name>武大狼name>
<gender>男gender>
<email>[email protected]email>
contact>
<user>
<contact>
<info>
<name id="888">我是西门庆name>
info>
contact>
user>
contactList>
测试绝对路径:
/**
1.绝对路径: /根元素/子元素/子子元素。
*/
@Test
public void parse01() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document = saxReader.read(Dom4jWithXPath.class.getClassLoader().getResourceAsStream("xpathtest.xml"));
// c、检索全部的名称
List<Node> nameNodes = document.selectNodes("/contactList/contact/name");
for (Node nameNode : nameNodes) {
Element nameEle = (Element) nameNode;
System.out.println(nameEle.getTextTrim());
}
}

测试相对路径:
/**
2.相对路径: ./子元素/子元素。 (.代表了当前元素)
*/
@Test
public void parse02() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(Dom4jWithXPath.class.getClassLoader().getResourceAsStream("xpathtest.xml"));
Element root = document.getRootElement();
// c、检索全部的名称
List<Node> nameNodes = root.selectNodes("./contact/name");
for (Node nameNode : nameNodes) {
Element nameEle = (Element) nameNode;
System.out.println(nameEle.getTextTrim());
}
}
结果和上面一样
测试全文搜索:
/**
3.全文搜索:
//元素 在全文找这个元素
//元素1/元素2 在全文找元素1下面的一级元素2
//元素1//元素2 在全文找元素1下面的全部元素2
*/
@Test
public void parse03() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(Dom4jWithXPath.class.getClassLoader().getResourceAsStream("xpathtest.xml"));
// c、检索数据
//List nameNodes = document.selectNodes("//name");
// List nameNodes = document.selectNodes("//contact/name");
List<Node> nameNodes = document.selectNodes("//contact//name");
for (Node nameNode : nameNodes) {
Element nameEle = (Element) nameNode;
System.out.println(nameEle.getTextTrim());
}
}

测试属性查找:
/**
4.属性查找。
//@属性名称 在全文检索属性对象。
//元素[@属性名称] 在全文检索包含该属性的元素对象。
//元素[@属性名称=值] 在全文检索包含该属性的元素且属性值为该值的元素对象。
*/
@Test
public void parse04() throws Exception {
// a、创建解析器对象
SAXReader saxReader = new SAXReader();
// b、把XML加载成Document文档对象
Document document =
saxReader.read(Dom4jWithXPath.class.getClassLoader().getResourceAsStream("xpathtest.xml"));
// c、检索数据
List<Node> nodes = document.selectNodes("//@id");
for (Node node : nodes) {
Attribute attr = (Attribute) node;
System.out.println(attr.getName() + "===>" + attr.getValue());
}
// 查询name元素(包含id属性的)
// Node node = document.selectSingleNode("//name[@id]");
Node node = document.selectSingleNode("//name[@id=888]");
Element ele = (Element) node;
System.out.println(ele.getTextTrim());
}
