【数据结构】图解八大排序(下)
文章目录
- 一、前言
- 二、快速排序
-
- 1. hoare 版
- 2. 挖坑法
- 3. 前后指针法
- 4. 快排的非递归实现
- 5. 时空复杂度分析
- 三、归并排序
-
- 1. 递归实现
- 2. 非递归实现
- 四、计数排序
一、前言
在上一篇文章中,我们已经学习了五种排序算法,还没看过的小伙伴可以去看一下:传送门
今天要讲的是八大排序中剩下的三种,这三种排序算法用的是非常多的,需要好好掌握。
下面介绍的排序算法均以排升序为例。
二、快速排序
快排的思想是分治,就是选定一个基准值,使这个值的左边都小于等于它,右边都大于等于它,然后递归处理左右子区间。
因此快排的关键就在于如何选定基准值和如何实现划分左右区间。
关于前者,我们可以选左端点,也可以选右端点,也可以选中点,还可以随机选。我们不妨先以左端点为基准值,来继续下面的分析。
关于后者,其实有很多种方法可以实现划分,这里只讲几种比较经典的。
1. hoare 版
hoare是快排的发明者,我们先来学习他的划分方法。
给几分钟认真观察下面的动图。
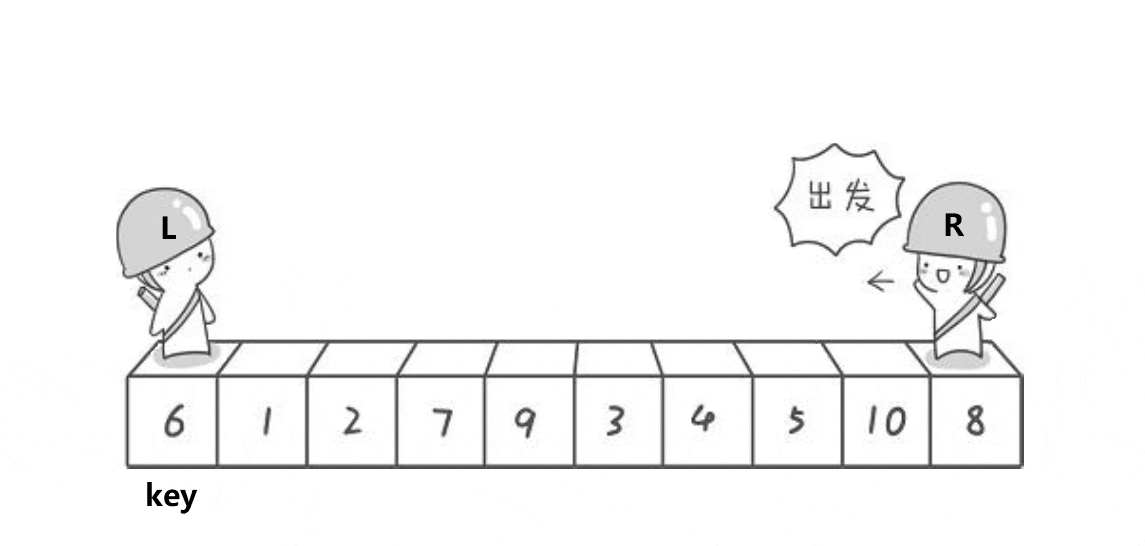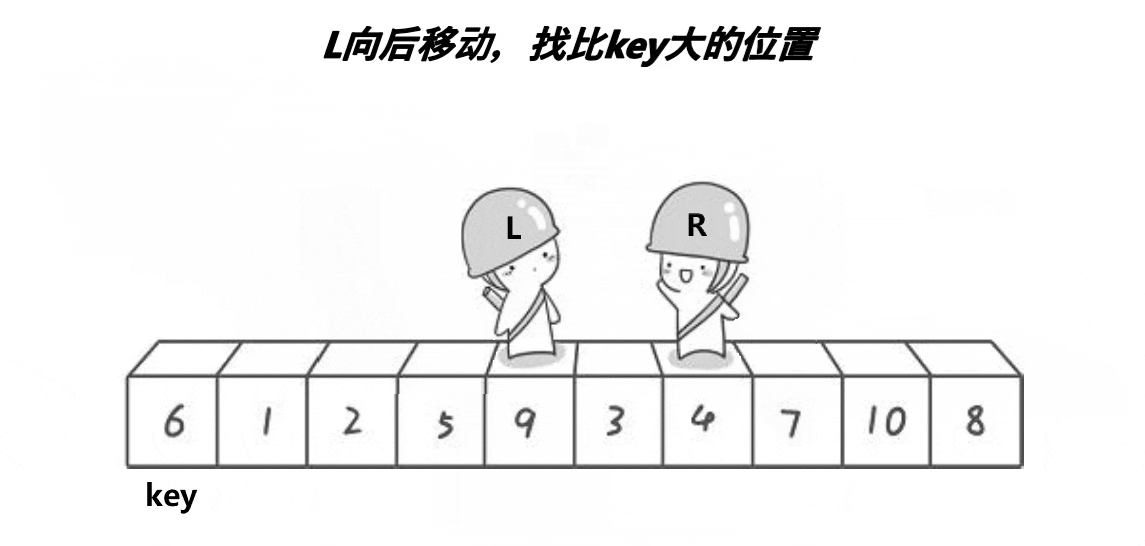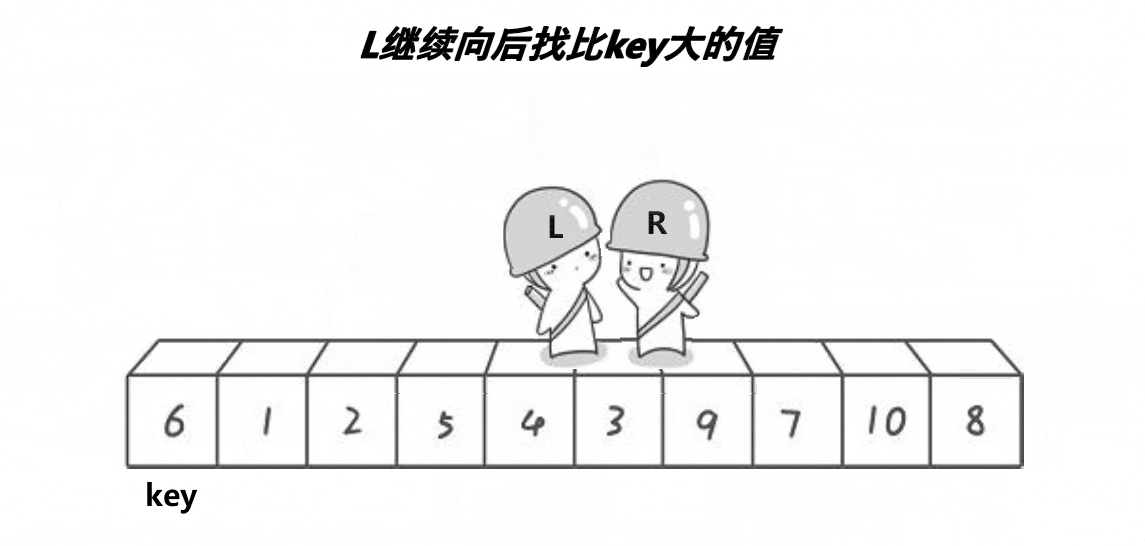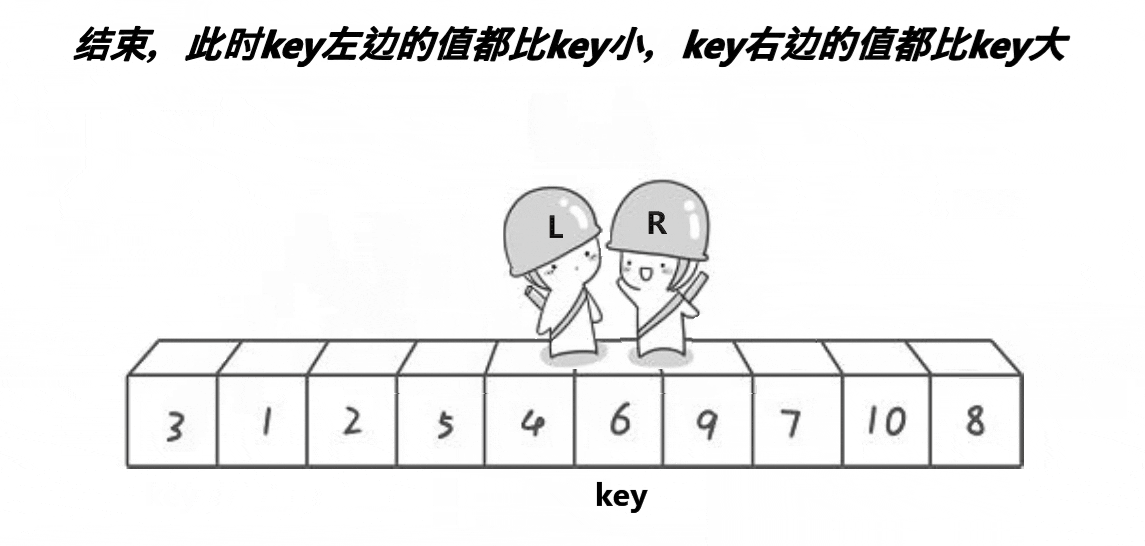
以排升序为例,我们要使左边都小于等于key,右边都大于等于key,就可以利用左右双指针来维护这段区间,右指针找小,左指针找大,找到后交换,再继续找,直至左右指针相遇为止。最后把key与相遇处的值交换即可。
先来解释下为什么选左端点为基准值的时候,要右指针先走。
先说结论,这样做是为了保证最后左右指针相遇处的值比key小,从而保证key与相遇位置的值交换后,左边都小于key,右边都大于key。同理如果以右端点为基准值,就要左指针先走。
再来解释下为什么会这样。左右指针相遇无非两种情况,要么左遇右,要么右遇左。
如果左遇右,因为右指针先走,所以右指针先停。由于右指针是找小,所以右指针停的位置的值比key小,所以相遇处的值就比key小。
如果右遇左,也就是说右指针还没停,因为右指针是先走的,一种情况是左指针根本没动过,还停留在左端点;另一种情况是左指针动过,但是上一轮左右指针指向的值交换后,左指针位置的值就比key小了。所以上述两种情况都能保证key与左右指针相遇处的值交换后,左边都小于key,右边都大于key。
来看看代码怎么写。
void QuickSort1(int a[], int l, int r)
{
if (l >= r) return;
int keyi = l;//左端为key,右端先走
int i = l, j = r;//保存一下左右指针的初始位置
while (l < r)
{
while (l < r && a[r] >= a[keyi]) r--;//右边找小
while (l < r && a[l] <= a[keyi]) l++;//左边找大
swap(&a[l], &a[r]);
}
swap(&a[keyi], &a[l]);
keyi = l;
QuickSort1(a, i, keyi - 1);
QuickSort1(a, keyi + 1, j);
}
第一趟结束后,因为key的左边都小于等于它,右边都大于等于它,所以key已经在最终排好序的位置上了。故只需递归[l, keyi - 1]和[keyi + 1, r]即可。
2. 挖坑法
这种方法比较好理解,直接上动图和代码。
void QuickSort2(int a[], int l, int r)
{
if (l >= r) return;
int key = a[l];
int hole = l;
int i = l, j = r;
while (l < r)
{
while (l < r && a[r] >= key) r--;
a[hole] = a[r];
hole = r;
while (l < r && a[l] <= key) l++;
a[hole] = a[l];
hole = l;
}
a[hole] = key;
QuickSort2(a, i, hole - 1);
QuickSort2(a, hole + 1, j);
}
3. 前后指针法
void QuickSort3(int a[], int l, int r)
{
if (l >= r) return;
int keyi = l;
int prev = l, cur = l + 1;
while (cur <= r)
{
if (a[cur] < a[keyi])
swap(&a[++prev], &a[cur]);
cur++;
}
swap(&a[prev], &a[keyi]);
QuickSort3(a, l, prev - 1);
QuickSort3(a, prev + 1, r);
}
以上三种方法效率并无差异,只是实现划分的思想不同,挑一种自己好理解的掌握就行。个人比较喜欢 hoare 版的快排。
4. 快排的非递归实现
众所周知,函数栈帧是建立在栈空间上的,而栈空间的大小是有限的,如果递归过深可能会导致栈溢出。因此算法的非递归实现具有很重要的意义。
我们可以利用数据结构中的栈来模拟递归的过程。
void QuickSortNonR(int a[], int l, int r)
{
ST st;
STInit(&st);
STPush(&st, r);
STPush(&st, l);
while (!STEmpty(&st))
{
l = STTop(&st);
STPop(&st);
r = STTop(&st);
STPop(&st);
//这里是hoare版的划分思想
int keyi = l;
int i = l, j = r;
while (i < j)
{
while (i < j && a[j] >= a[keyi]) j--;
while (i < j && a[i] <= a[keyi]) i++;
swap(&a[i], &a[j]);
}
swap(&a[keyi], &a[i]);
keyi = i;
//如果区间长度==2
//它的两个子区间长度就分别为1和0,故不用继续递归
if (r - keyi > 2)//r - (keyi + 1) + 1
{
STPush(&st, r);
STPush(&st, keyi + 1);
}
if (keyi - l > 2)//(keyi - 1) - l + 1
{
STPush(&st, keyi - 1);
STPush(&st, l);
}
}
STDestroy(&st);
}
由于 C 语言的特性,我们只能自己实现栈这个数据结构,具体可以看我这篇文章:【数据结构】栈和队列
另外,快排的非递归还可以用队列实现,有兴趣的可以自己尝试。
提示:栈模拟的是dfs,队列模拟的是bfs。
5. 时空复杂度分析
快排的平均时间复杂度是O(NlogN),数组有序的情况下会退化成O(N^2)。
空间复杂度是O(logN)。
快排是不稳定的排序算法。
三、归并排序
归并排序的思想是分治,就是先递归到最后一层,此时每个子区间都只有一个数,即每个子区间都有序,每两个子区间再合并成一个有序区间,最后扫尾。
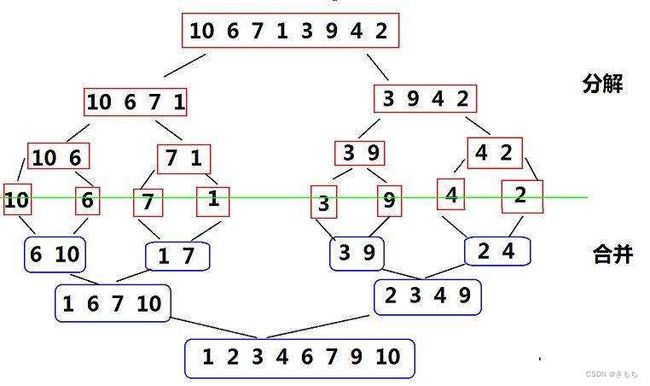
完成这个过程需要一个辅助数组,另外要开辟logN层栈帧,故空间复杂度为O(N)。
归并排序的时间复杂度是O(NlogN)。
归并排序是稳定的排序算法。
来看看代码怎么写。
1. 递归实现
void _MergeSort(int a[], int l, int r, int* tmp)
{
if (l >= r) return;
int mid = l + r >> 1;
_MergeSort(a, l, mid, tmp);
_MergeSort(a, mid + 1, r, tmp);
int i = l, j = mid + 1, k = l;
while (i <= mid && j <= r)
{
if (a[i] <= a[j]) tmp[k++] = a[i++];
else tmp[k++] = a[j++];
}
while (i <= mid) tmp[k++] = a[i++];
while (j <= r) tmp[k++] = a[j++];
for (int i = l; i <= r; i++) a[i] = tmp[i];
}
void MergeSort(int a[], int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
_MergeSort(a, 0, n - 1, tmp);
free(tmp);
}
2. 非递归实现
void MergeSortNonR(int a[], int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
int gap = 1;
while (gap < n)
{
int j = 0;
for (int i = 0; i < n; i += 2 * gap)
{
// 每组的合并数据
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
if (end1 >= n || begin2 >= n)
{
break;
}
// 修正
if (end2 >= n)
{
end2 = n - 1;
}
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
// 归并一组,拷贝一组
memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));
}
gap *= 2;
}
free(tmp);
}
归并排序的缺点在于O(N)的空间复杂度和拷贝数组的消耗。
因此归并排序的思想更多的是用于外部排序。
四、计数排序
计数排序的思想是相对映射。
直接来看代码怎么实现。
void CountSort(int a[], int n)
{
int min = 0, max = 0;
for (int i = 0; i < n; i++)
{
if (a[i] < min) min = a[i];
if (a[i] > max) max = a[i];
}
int range = max - min + 1;
int* count = (int*)calloc(range, sizeof(int));
for (int i = 0; i < n; i++)
{
int idx = a[i] - min;
count[idx]++;
}
for (int i = 0, j = 0; i < range; i++)
{
while (count[i]--)
{
a[j++] = i + min;
}
}
free(count);
}
时间复杂度 O(N + range)
空间复杂度 O(range)
缺陷:只适用于数据范围较为集中的数组,且只能用于整型,因为计数排序是用计数数组的下标来相对映射原数组的值的。