TRT3-trt-basic - 5.1 封装插件
之前TRTbasic4是新增插件,这次我们看看不新增插件,仅凭封装可不可以达到一样的功能
 首先可以看到这次的g.op不再是MYSELU了,而是plugin,那为什么.cu还能识别出来呢?
首先可以看到这次的g.op不再是MYSELU了,而是plugin,那为什么.cu还能识别出来呢?
是因为在这里做了一个通用的plugin

DEFINE_BUILTIN_OP_IMPORTER(Plugin)
{
std::vector inputTensors;
std::vector weights;
for(int i = 0; i < inputs.size(); ++i){
auto& item = inputs.at(i);
if(item.is_tensor()){
nvinfer1::ITensor* input = &convertToTensor(item, ctx);
inputTensors.push_back(input);
}else{
weights.push_back(item.weights());
}
}
OnnxAttrs attrs(node, ctx);
auto name = attrs.get("name", "");
auto info = attrs.get("info", "");
// Create plugin from registry
auto registry = getPluginRegistry();
auto creator = registry->getPluginCreator(name.c_str(), "1", "");
if(creator == nullptr){
printf("%s plugin was not found in the plugin registry!", name.c_str());
ASSERT(false, ErrorCode::kUNSUPPORTED_NODE);
}
nvinfer1::PluginFieldCollection pluginFieldCollection;
pluginFieldCollection.nbFields = 0;
ONNXPlugin::TRTPlugin* plugin = (ONNXPlugin::TRTPlugin*)creator->createPlugin(name.c_str(), &pluginFieldCollection);
if(plugin == nullptr){
LOG_ERROR(name << " plugin was not found in the plugin registry!");
ASSERT(false, ErrorCode::kUNSUPPORTED_NODE);
}
std::vector> weightTensors;
for(int i = 0; i < weights.size(); ++i){
auto& weight = weights[i];
std::vector dims(weight.shape.d, weight.shape.d + weight.shape.nbDims);
std::shared_ptr dweight(new ONNXPlugin::Weight(dims, ONNXPlugin::DataType::Float32));
if(weight.type != ::onnx::TensorProto::FLOAT){
LOG_ERROR("unsupport weight type: " << weight.type);
}
memcpy(dweight->pdata_host_, weight.values, dweight->data_bytes_);
weightTensors.push_back(dweight);
}
plugin->pluginInit(name, info, weightTensors);
auto layer = ctx->network()->addPluginV2(inputTensors.data(), inputTensors.size(), *plugin);
std::vector outputs;
for( int i=0; i< layer->getNbOutputs(); ++i )
outputs.push_back(layer->getOutput(i));
return outputs;
}
} // namespace 仅仅通过 设置name就可以设置这个模块的名字
class MYSELUImpl(torch.autograd.Function):
# reference: https://pytorch.org/docs/1.10/onnx.html#torch-autograd-functions
@staticmethod
def symbolic(g, x, p):
print("==================================call symbolic")
return g.op("Plugin", x, p,
g.op("Constant", value_t=torch.tensor([3, 2, 1], dtype=torch.float32)),
name_s="MYSELU",
info_s=json.dumps(
dict(
attr1_s="这是字符串属性",
attr2_i=[1, 2, 3],
attr3_f=222
), ensure_ascii=False
)
)
@staticmethod
def forward(ctx, x, p):
return x * 1 / (1 + torch.exp(-x))并且对于attribute也不用单独的设置了,可以直接用json把这个dicts存进去
所以这里也是通过info读出来
OnnxAttrs attrs(node, ctx);
auto name = attrs.get("name", "");
auto info = attrs.get("info", ""); 传入cu里的时候也是通过info传入,之后再通过config的读取就可以读取出来各种类型的文件,这样就不用再设置字符串类型还是float32类型。
class MYSELU : public TRTPlugin {
public:
SetupPlugin(MYSELU);
virtual void config_finish() override{
printf("\033[33minit MYSELU config: %s\033[0m\n", config_->info_.c_str());
printf("weights count is %d\n", config_->weights_.size());
}
int enqueue(const std::vector& inputs, std::vector& outputs, const std::vector& weights, void* workspace, cudaStream_t stream) override{
int n = inputs[0].count();
const int nthreads = 512;
int block_size = n < nthreads ? n : nthreads;
int grid_size = (n + block_size - 1) / block_size;
MYSELU_kernel_fp32 <<>> (inputs[0].ptr(), outputs[0].ptr(), n);
return 0;
}
};
RegisterPlugin(MYSELU); 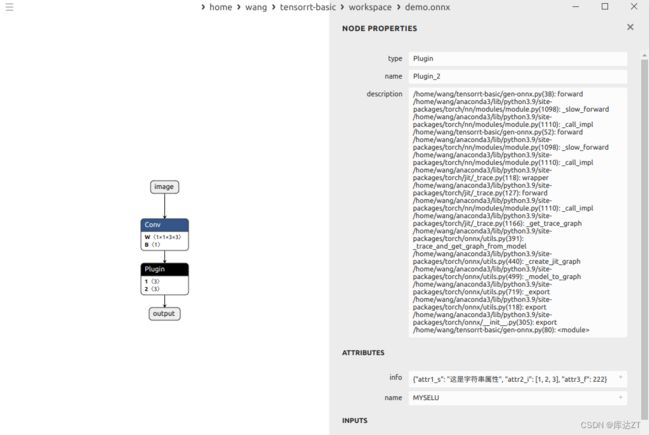
从导出的onnx文件也可以看出来,类型是plugin,name是MYSELU,剩下的都在info里
而且在这里creator什么的用的都是默认的实现
auto creator = registry->getPluginCreator(name.c_str(), "1", "");class class_##PluginCreator__ : public nvinfer1::IPluginCreator{ \
public: \
const char* getPluginName() const noexcept override{return #class_;} \
const char* getPluginVersion() const noexcept override{return "1";} \
const nvinfer1::PluginFieldCollection* getFieldNames() noexcept override{return &mFieldCollection;} \
\
nvinfer1::IPluginV2DynamicExt* createPlugin(const char* name, const nvinfer1::PluginFieldCollection* fc) noexcept override{ \
auto plugin = new class_(); \
mFieldCollection = *fc; \
mPluginName = name; \
return plugin; \
} \
\
nvinfer1::IPluginV2DynamicExt* deserializePlugin(const char* name, const void* serialData, size_t serialLength) noexcept override{ \
auto plugin = new class_(); \
plugin->pluginInit(name, serialData, serialLength); \
mPluginName = name; \
return plugin; \
} \
\
void setPluginNamespace(const char* libNamespace) noexcept override{mNamespace = libNamespace;} \
const char* getPluginNamespace() const noexcept override{return mNamespace.c_str();} \
\
private: \
std::string mNamespace; \
std::string mPluginName; \
nvinfer1::PluginFieldCollection mFieldCollection{0, nullptr}; \
}; \
REGISTER_TENSORRT_PLUGIN(class_##PluginCreator__);
在这里通过自定义ConfigPlugin可以将权重,输入等新信息全都输入到config中。
经过以上这些等等操作,就可以达成在cu里获取基本信息。
virtual void config_finish() override{
printf("\033[33minit MYSELU config: %s\033[0m\n", config_->info_.c_str());
printf("weights count is %d\n", config_->weights_.size());
}抑或是自定义实现enqueue这些操作:
int enqueue(const std::vector& inputs, std::vector& outputs, const std::vector& weights, void* workspace, cudaStream_t stream) override{
int n = inputs[0].count();
const int nthreads = 512;
int block_size = n < nthreads ? n : nthreads;
int grid_size = (n + block_size - 1) / block_size;
MYSELU_kernel_fp32 <<>> (inputs[0].ptr(), outputs[0].ptr(), n);
return 0;
}