flink sql 知其所以然(十):大家都用 cumulate window 计算累计指标啦
想啥呢,小宝贝,还不三连???(关注 + 点赞 + 再看),对博主的肯定,会督促博主持续的输出更多的优质实战内容!!!
1.序篇
源码公众号后台回复1.13.2 cumulate window 的奇妙解析之路获取。
此节就是窗口聚合章节的第三篇,上节介绍了 1.13 window tvf tumble window 实现,本节主要介绍 1.13. window tvf 的一个重磅更新,即 cumulate window。
本节从以下几个章节给大家详细介绍 cumulate window 的能力。
-
应用场景介绍
-
预期的效果
-
解决方案介绍
-
总结及展望篇
2.应用场景介绍
先来一个简单的小调查:在实时场景中,你见到过最多的指标需求场景是哪一种?
答案:博主相信,占比比较多的不是 PCU(即同时在线 PV,UV),而是周期内累计 PV,UV 指标(如每天累计到当前这一分钟的 PV,UV)。因为这类指标是一段周期内的累计状态,对分析师来说更具统计分析价值,而且几乎所有的复合指标都是基于此类指标的统计(不然离线为啥都要一天的数据,而不要一分钟的数据呢)。
本文要介绍的就是周期内累计 PV,UV 指标在 flink 1.13 版本的最优解决方案。
3.预期的效果
先来一个实际案例来看看在具体输入值的场景下,输出值应该长啥样。
指标:每天的截止当前分钟的累计 money(sum(money)),去重 id 数(count(distinct id))。每天代表窗口大小为 1 天,分钟代表移动步长为分钟级别。
来一波输入数据:
| time | id | money |
|---|---|---|
| 2021-11-01 00:01:00 | A | 3 |
| 2021-11-01 00:01:00 | B | 5 |
| 2021-11-01 00:01:00 | A | 7 |
| 2021-11-01 00:02:00 | C | 3 |
| 2021-11-01 00:03:00 | C | 10 |
预期输出数据:
| time | count distinct id | sum money |
|---|---|---|
| 2021-11-01 00:01:00 | 2 | 15 |
| 2021-11-01 00:02:00 | 3 | 18 |
| 2021-11-01 00:03:00 | 3 | 28 |
转化为折线图长这样:

当日累计
可以看到,其特点就在于,每一分钟的输出结果都是当天零点累计到当前的结果。
4.解决方案介绍
4.1.flink 1.13 之前
可选的解决方案有两种
-
tumble window(1天窗口) + early-fire(1分钟)
-
group by(1天) + minibatch(1分钟)
但是上述两种解决方案产出的都是 retract 流,关于 retract 流存在的缺点见如下文章:
[

踩坑记 | flink sql count 还有这种坑!
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247487969&idx=1&sn=7215b101f49bd5e62b81a746dc6b15e6&chksm=c1549d19f623140f84cd436dd02be7e6ae08e28e5117bff88166237c09c17ca491a3e88a3a3d&scene=21#wechat_redirect)
并且 tumble window + early-fire 的触发机制是基于处理时间而非事件时间,具体缺点见如下文章:
https://mp.weixin.qq.com/s/L8-RSS6v3Ppts60CWngiOA
4.2.flink 1.13 及之后
诞生了 cumulate window 解法,具体见官网链接:
https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/table/sql/queries/window-tvf/#cumulate
如下官网文档所示,介绍 cumulate window 的第一句话就是 cumulate window 非常适合于之前使用 tumble window + early-fire 的场景。可以说 cumulate window 就是在用户计算周期内累计 PV,UV 指标时,使用了 tumble window + early-fire 后发现这种方案存在了很多坑的情况下,而诞生的!

cumulate window
其计算机制如下图所示:
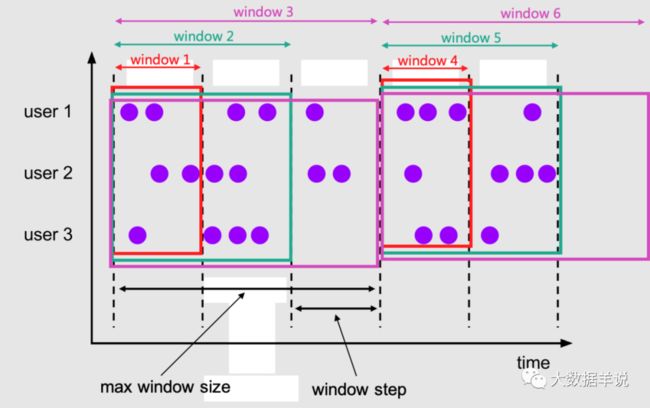
cumulate window
还是以刚刚的案例说明,以天为窗口,每分钟输出一次当天零点到当前分钟的累计值,在 cumulate window 中,其窗口划分规则如下:
-
[2021-11-01 00:00:00, 2021-11-01 00:01:00]
-
[2021-11-01 00:00:00, 2021-11-01 00:02:00]
-
[2021-11-01 00:00:00, 2021-11-01 00:03:00] …
-
[2021-11-01 00:00:00, 2021-11-01 23:58:00]
-
[2021-11-01 00:00:00, 2021-11-01 23:59:00]
第一个 window 统计的是一个区间的数据;第二个 window 统计的是第一区间和第二个区间的数据;第三个 window 统计的是第一区间,第二个区间和第三个区间的数据。
那么以 cumulate window 实现上述的需求,具体的 SQL 如下:
SELECT UNIX_TIMESTAMP(CAST(window_end AS STRING)) * 1000 as window_end,
window_start,
sum(money) as sum_money,
count(distinct id) as count_distinct_id
FROM TABLE(CUMULATE(
TABLE source_table
, DESCRIPTOR(row_time)
, INTERVAL '60' SECOND
, INTERVAL '1' DAY))
GROUP BY window_start,
window_end
其中 CUMULATE(TABLE source_table, DESCRIPTOR(row_time), INTERVAL '60' SECOND, INTERVAL '1' DAY) 中的INTERVAL '1' DAY 代表窗口大小为 1 天,INTERVAL '60' SECOND,窗口划分步长为 60s。
其中 window_start, window_end 字段是 cumulate window 自动生成的类型是 timestamp(3)。
window_start 固定为窗口的开始时间。window_end 为一个子窗口的结束时间。
最终结果如下。
输入数据:
| row_time | id | money |
|---|---|---|
| 2021-11-01 00:01:00 | A | 3 |
| 2021-11-01 00:01:00 | B | 5 |
| 2021-11-01 00:01:00 | A | 7 |
| 2021-11-01 00:02:00 | C | 3 |
| 2021-11-01 00:03:00 | C | 10 |
输出数据:
| window_end | window_start | sum_money | count_distinct_id |
|---|---|---|---|
| 2021-11-21T00:01 | 1635696000000 | 2 | 15 |
| 2021-11-21T00:02 | 1635696000000 | 3 | 18 |
| 2021-11-21T00:03 | 1635696000000 | 3 | 28 |
Notes:天级别窗口划分的时候一定要注意时区问题喔!https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/table/timezone/
4.3.cumulate window 原理解析
首先 cumulate window 是一个窗口,其窗口计算的触发也是完全由 watermark 推动的。与 tumble window 一样。
以上述天窗口分钟累计案例举例:cumulate window 维护了一个 slice state 和 merged state,slice state 就是每一分钟内窗口数据(叫做切片),merged state 的作用是当 watermark 推动到下一分钟时,这一分钟的 slice state 就会被 merge 到 merged stated 中,因此 merged state 中的值就是当天零点到当前这一分钟的累计值,我们的输出结果就是从 merged state 得到的。
4.4.cumulate window 怎么解决 tumble window + early-fire 的问题
- 问题1:tumble window + early-fire 处理时间触发的问题。
cumulate window 可以以事件时间推进进行触发。
- 问题1:tumble window + early-fire retract 流问题。
cumulate window 是 append 流,自然没有 retract 流的问题。
5.总结
源码公众号后台回复1.13.2 cumulate window 的奇妙解析之路获取。
本文主要介绍了 window tvf 实现的 cumulate window 聚合类指标的场景案例以及其运行原理:
-
介绍了周期内累计 PV,UV 是我们最常用的指标场景质疑。
-
在 tumble window + early-fire 或者 groupby + minibatch 计算周期内累计 PV,UV 存在各种问题是,诞生了 cumulate window 帮我们解决了这些问题,并以一个案例进行说明。
[

当我们在做流批一体时,我们在做什么?
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247489496&idx=1&sn=016e580c5932b232005ff1d5e345588a&chksm=c1549b20f6231236571444c621f5c94dedc06daad7db0fa662674e544424e4a0d0fb16df3168&scene=21#wechat_redirect)
[

flink sql 知其所以然(九):window tvf tumble window 的奇思妙解
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247489404&idx=1&sn=af13ff231b113e702024e9efe068c54f&chksm=c1549b84f62312924ce6aed7df2578fa4cbe5d21ec1fe7f45f1bef80b0cf2f6967e11b0f053c&scene=21#wechat_redirect)
[

flink sql 知其所以然(八):flink sql tumble window 的奇妙解析之路
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247489338&idx=1&sn=941d8f05e194182071e55550969bc49e&chksm=c1549bc2f62312d48b6cd7d322ecf466df5610643a803f65db4f06e360a80a9471b1e1f35634&scene=21#wechat_redirect)
[

flink sql 知其所以然(七):不会连最适合 flink sql 的 ETL 和 group agg 场景都没见过吧?
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247489235&idx=1&sn=66c2b95aa3e22069a12b3d53b6d1d9f3&chksm=c1549a2bf623133d7a75732b5cea4bc304bf06a53777963d5cac8406958114873294dc3e4699&scene=21#wechat_redirect)
[

flink sql 知其所以然(六)| flink sql 约会 calcite(看这篇就够了)
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247489112&idx=1&sn=21e86dab0e20da211c28cd0963b75ee2&chksm=c1549aa0f62313b6674833cd376b2a694752a154a63532ec9446c9c3013ef97f2d57b4e2eb64&scene=21#wechat_redirect)
[

flink sql 知其所以然(五)| 自定义 protobuf format
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488994&idx=1&sn=20236350b1c8cfc4ec5055687b35603d&chksm=c154991af623100c46c0ed224a8264be08235ab30c9f191df7400e69a8ee873a3b74859fb0b7&scene=21#wechat_redirect)