Learning a Deep Single Image Contrast Enhancer from Multi-Exposure Images阅读札记
Learning a Deep Single Image Contrast Enhancer from Multi-Exposure Images阅读札记
论文发表于2018年的TIP。
1 Abstract
存在问题:
照明条件差和动态范围有限,会导致图像曝光不足、曝光过度以及对比度低,如图(a)所示。
多曝光图像融合(MEF)方法:
可以恢复更多的图像细节,但多曝光图像的获取使成像过程复杂化,且相机抖动或者场景运动(人体运动、流水等)都会导致重影伪影,如图(b)所示。
单图像对比度增强(SICE)方法:
只需一张曝光图像作为输入(图(a)中带有红色框的图像),不会产生重影伪影,但恢复细节不如MEF方法,如图( c)所示。
本文方法:
基于MEF和SICE方法的利弊,提出一种SICE方法,可以近似MEF方法的对比度增强效果,且没有重影伪影,如图(d)所示。
本文贡献:
(1)建立了一个大规模的多曝光图像数据集,该数据集包含了不同曝光水平的低对比度图像及其对应的高质量参考图像。
(2)利用所构造的数据集,为SICE训练了一个设计良好的CNN
2 Multi-exposure Image Dataset and Reference Image Generation
2.1 Objectives
(1)数据集应包含足够的高分辨率多曝光图像序列,并覆盖多种场景——从室内和室外场景中收集大量序列,并确保数据集中的照片涵盖了广泛的场景、主题和照明条件,其中部分序列来自现有数据集。
(2)对于每个序列,生成高质量的参考图像——采用13种最先进的MEF和HDR算法来生成所有场景的高对比度参考图像,并进行主观实验来选择每个序列的最佳输出。
本文数据集部分样本序列如图所示:
2.2 Multi-Exposure Image Collection
(1)数据收集(使用7种不同的相机在不同的场景拍摄):
• 对于室内场景,设置静态环境并使用三脚架来捕捉对齐良好的图像序列,为每个室内场景收集7到18张图像,曝光级别根据场景的照明比率手动设置。
• 对于室外场景,使用连续包围模式自动拍摄多曝光图像序列,对于每个室外场景,收集多个序列(EV偏移 ± { 0.5 , 0.7 , 1.0 , 2.0 , 3.0 } ±\{0.5,0.7,1.0,2.0,3.0\} ±{0.5,0.7,1.0,2.0,3.0}),每个序列包含3到5张图像。
(2)数据筛选:
• 对于图像严重失真(如运动模糊、失焦和可见传感器噪声)或明显移动物体的序列直接丢弃。
• 对于重复的序列手动选择最匹配的一个。
2.3 Reference Image Generation
采用13种最先进的MEF和基于堆栈的HDR方法生成高质量的参考图像,邀请18位志愿者,为每个序列从13个高质量参考图像中主观选择最好的一个作为该序列最终参考图像。
2.4 Dataset
最终,本文数据集包括来自室内和室外场景的589个序列,包含4413个多曝光图像,大多数图像的分辨率在3000×2000到6000×4000之间,是论文发表时现有的最大的多曝光图像数据集(https://github.com/csjcai/SICE)
3 CNN-based SICE Learning
网络框架图

3.1 Network Overview
本文提出的CNN具有5种类型的层:
(1)Conv+PReLU:大小为3×3、5×5和9×9的64个滤波器(步长为1和2)用于生成64个特征图,PReLU(参数校正线性单元)作为激活函数。
(2)Deconv+PReLU:使用大小为9×9、5×5和3×3且步长为2和1的64个滤波器来生成64个特征图,并使用PReLU作为激活函数。
(3)Conv+BN+PReLU:使用大小为3×3的64个滤波器,并且在卷积和PReLU之间进行批量归一化。
(4)Conv:3个大小为1×1的滤波器用于重构输出。
(5)Skip connection:添加操作用于连接两个层的特征图。
⭐卷积和反卷积策略不仅避免了零填充引起的边界区域伪影,而且减少了跨步滤波器的计算负担。
⭐输入图像中正系数和负系数都包含输入图像的重要局部结构信息,ReLU激活函数简单地将负系数设置为0不是最好的选择。PReLU保留一定的负系数,以几乎为零的额外计算成本和很小的过拟合风险来改进模型拟合,使得 能够用较少的滤波器产生高质量的估计,如下图所示:

3.2 Enhancement Network
(1)亮度增强网络
由于亮度分量表示全局自然度,因此将网络的局部感受野设置得更大,以连接原始图像中的更多像素。为了增加感受野,同时防止跨步卷积操作导致的信息丢失,采用U-Net作为亮度增强网络。亮度增强网络细节如下表所示:

采用MSE作为损失函数:

L o r i g i n a l L_{original} Loriginal:输入图像的低频亮度分量
L r e f L_{ref} Lref:参考图像的低频亮度分量
F L ( ⋅ , Θ ) F_L (·,Θ) FL(⋅,Θ):参数为 Θ Θ Θ的亮度CNN映射函数
(2)细节增强网络
对细节增强网络采用残差学习策略,这种结构保证了输入信息可以通过所有参数层传播,不仅可以比直接映射网络更快而且收敛更稳定。细节增强网络细节如下表所示:

采用 l 1 l_1 l1-范数作为损失函数:

R o r i g i n a l R_{original} Roriginal:输入图像的高频细节分量
R r e f R_{ref} Rref:参考图像的高频细节分量
F R ( ⋅ , Ω ) F_R (·,Ω) FR(⋅,Ω):参数为 Ω Ω Ω的细节CNN映射函数
3.3 Whole Image Enhancement Network
将两个增强分量合并到一幅图像中,并引入另一个CNN以进一步将其细化为所需的参考图像。整个图像增强网络架构在细节增强网络的基础上加入批处理归一化(BN)操作。全图像增强网络细节如下表所示:

采用感知驱动的DSSIM标准作为损失函数:
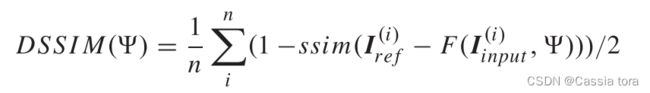
I i n p u t I_{input} Iinput:输入图像
I r e f I_{ref} Iref:参考图像
F ( ⋅ , Ψ ) F (·, Ψ) F(⋅,Ψ):参数为 Ψ Ψ Ψ的CNN映射函数
网络训练步骤:
(1)分别训练亮度增强网络和细节增强网络,学习权值 Θ Θ Θ和 Ω Ω Ω。
(2)将亮度增强网络和细节增强网络的结果作为输入,训练全图像增强网络学习权值 Ψ Ψ Ψ
(3)去掉亮度增强网络和细节增强网络的损失函数,以DSSIM作为损失函数对整个系统进行联合微调。
4 Experiment Result
4.1 Comparisons With SICE Methods
(1)对来自本文数据集的图像进行比较:
定性评估:
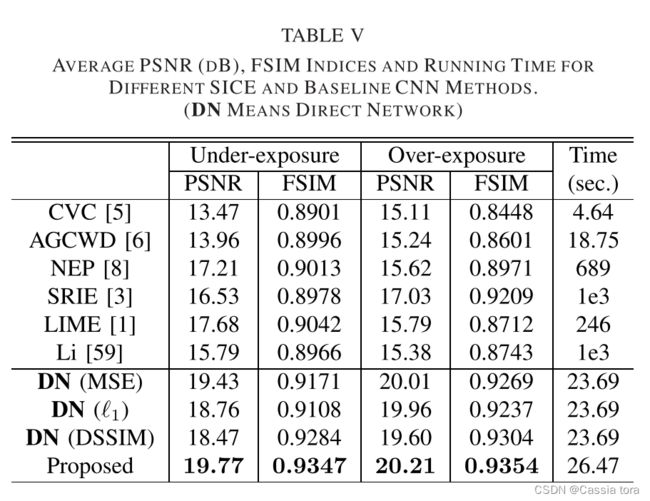
定量评估:
(2) 在本文数据集之外的图像上进行视觉比较:
4.2 Comparisons With MEF Methods
静态场景结果:

动态场景结果:

4.3 Failure Case
本文方法可能不能恢复大的和严重曝光过度的区域的细节,如图所示:
