kafka 3.0 日志定时清理(源码)
文章目录
- 1、定时任务入口
- 2、LopManager(这个是日志抽象层,实际逻辑不在这里)
-
- (1) 把日志清理加入定时任务中
- 3、清理符合条件的日志
-
- (1)deletableSegments(把需要删除的segment加入待删除的集合)
- (2) deleteSegments(对待删除的segment集合删除)
1、定时任务入口
这里选择kraft的模式启动的定时任务,所以入口是在
BrokerServer.scala文件中,如果选择ZooKeeper模式的入口在KafkaServer.scala
def startup(): Unit = {
if (!maybeChangeStatus(SHUTDOWN, STARTING)) return
try {
info("Starting broker")
/* start scheduler 开始定时任务*/,
kafkaScheduler = new KafkaScheduler(config.backgroundThreads)
kafkaScheduler.startup()
//省略。。。
//创建日志管理器,但不要启动它,因为我们需要延迟任何潜在的不干净关闭日志恢复
// 直到我们赶上元数据日志并拥有最新的主题和代理配置。
logManager = LogManager(config, initialOfflineDirs, metadataCache, kafkaScheduler, time,
brokerTopicStats, logDirFailureChannel, keepPartitionMetadataFile = true)
//省略。。。
} catch {
case e: Throwable =>
maybeChangeStatus(STARTING, STARTED)
fatal("Fatal error during broker startup. Prepare to shutdown", e)
shutdown()
throw e
}
}
2、LopManager(这个是日志抽象层,实际逻辑不在这里)
object LogManager {
val RecoveryPointCheckpointFile = "recovery-point-offset-checkpoint"
val LogStartOffsetCheckpointFile = "log-start-offset-checkpoint"
val ProducerIdExpirationCheckIntervalMs = 10 * 60 * 1000
def apply(config: KafkaConfig,
initialOfflineDirs: Seq[String],
configRepository: ConfigRepository,
kafkaScheduler: KafkaScheduler,
time: Time,
brokerTopicStats: BrokerTopicStats,
logDirFailureChannel: LogDirFailureChannel,
keepPartitionMetadataFile: Boolean): LogManager = {
val defaultProps = LogConfig.extractLogConfigMap(config)
LogConfig.validateValues(defaultProps)
val defaultLogConfig = LogConfig(defaultProps)
val cleanerConfig = LogCleaner.cleanerConfig(config)
new LogManager(logDirs = config.logDirs.map(new File(_).getAbsoluteFile),
initialOfflineDirs = initialOfflineDirs.map(new File(_).getAbsoluteFile),
configRepository = configRepository,
initialDefaultConfig = defaultLogConfig,
cleanerConfig = cleanerConfig,
recoveryThreadsPerDataDir = config.numRecoveryThreadsPerDataDir,
flushCheckMs = config.logFlushSchedulerIntervalMs,
flushRecoveryOffsetCheckpointMs = config.logFlushOffsetCheckpointIntervalMs,
flushStartOffsetCheckpointMs = config.logFlushStartOffsetCheckpointIntervalMs,
//log.retention.check.interval.ms 日志保留检查间隔 ms
retentionCheckMs = config.logCleanupIntervalMs,
maxPidExpirationMs = config.transactionalIdExpirationMs,
scheduler = kafkaScheduler,
brokerTopicStats = brokerTopicStats,
logDirFailureChannel = logDirFailureChannel,
time = time,
keepPartitionMetadataFile = keepPartitionMetadataFile,
interBrokerProtocolVersion = config.interBrokerProtocolVersion)
}
}
上面的new LopManager 是下面的
(1) 把日志清理加入定时任务中
/**
* The entry point to the kafka log management subsystem. The log manager is responsible for log creation, retrieval, and cleaning.
* All read and write operations are delegated to the individual log instances.
*kafka 日志管理子系统的入口点。日志管理器负责日志的创建、检索和清理。 所有读写操作都委托给各个日志实例
* The log manager maintains logs in one or more directories. New logs are created in the data directory
* with the fewest logs. No attempt is made to move partitions after the fact or balance based on
* size or I/O rate.
*日志管理器在一个或多个目录中维护日志。新日志在数据目录 中创建,日志最少。事后不会尝试移动分区或根据 大小或 I/O 速率进行平衡
* A background thread handles log retention by periodically truncating excess log segments.
* 后台线程通过定期截断多余的日志段来处理日志保留
*/
@threadsafe
class LogManager(logDirs: Seq[File],
initialOfflineDirs: Seq[File],
configRepository: ConfigRepository,
val initialDefaultConfig: LogConfig,
val cleanerConfig: CleanerConfig,
recoveryThreadsPerDataDir: Int,
val flushCheckMs: Long,
val flushRecoveryOffsetCheckpointMs: Long,
val flushStartOffsetCheckpointMs: Long,
val retentionCheckMs: Long,
val maxPidExpirationMs: Int,
interBrokerProtocolVersion: ApiVersion,
scheduler: Scheduler,
brokerTopicStats: BrokerTopicStats,
logDirFailureChannel: LogDirFailureChannel,
time: Time,
val keepPartitionMetadataFile: Boolean) extends Logging with KafkaMetricsGroup {
import LogManager._
//省略。。。。
/**
* Start the background threads to flush logs and do log cleanup
* 启动后台线程以刷新日志并进行日志清理
*/
def startup(topicNames: Set[String]): Unit = {
// ensure consistency between default config and overrides
val defaultConfig = currentDefaultConfig
startupWithConfigOverrides(defaultConfig, fetchTopicConfigOverrides(defaultConfig, topicNames))
}
private[log] def startupWithConfigOverrides(defaultConfig: LogConfig, topicConfigOverrides: Map[String, LogConfig]): Unit = {
loadLogs(defaultConfig, topicConfigOverrides) // this could take a while if shutdown was not clean
/* Schedule the cleanup task to delete old logs 安排清理任务以删除旧日志*/
if (scheduler != null) {
info("Starting log cleanup with a period of %d ms.".format(retentionCheckMs))
scheduler.schedule("kafka-log-retention",
//cleanupLogs 是清理日志的入口
cleanupLogs _,
delay = InitialTaskDelayMs,
period = retentionCheckMs,
TimeUnit.MILLISECONDS)
//省略。。。。。
}
if (cleanerConfig.enableCleaner) {
_cleaner = new LogCleaner(cleanerConfig, liveLogDirs, currentLogs, logDirFailureChannel, time = time)
_cleaner.startup()
}
}
}
3、清理符合条件的日志
/**
* Delete any eligible logs. Return the number of segments deleted.
* Only consider logs that are not compacted.
* 删除任何符合条件的日志。返回删除的段数。
* 只考虑未压缩的日志。
*/
def cleanupLogs(): Unit = {
debug("Beginning log cleanup...")
var total = 0
val startMs = time.milliseconds
//省略。。。。
try {
deletableLogs.foreach {
//topicPartition代表主题的分区,log是此topic,此分区的日志统计
case (topicPartition, log) =>
debug(s"Garbage collecting '${log.name}'")
total += log.deleteOldSegments()
val futureLog = futureLogs.get(topicPartition)
if (futureLog != null) {
// clean future logs 清理未来的日志
debug(s"Garbage collecting future log '${futureLog.name}'")
total += futureLog.deleteOldSegments()
}
}
} finally {
if (cleaner != null) {
cleaner.resumeCleaning(deletableLogs.map(_._1))
}
}
debug(s"Log cleanup completed. $total files deleted in " +
(time.milliseconds - startMs) / 1000 + " seconds")
}
上面log.deleteOldSegments() 调用的是Log.scala的deleteOldSegments
/**
* If topic deletion is enabled, delete any log segments that have either expired due to time based retention
* or because the log size is > retentionSize.
*如果启用了主题删除,请删除由于基于时间的保留 ,或由于日志大小大于保留大小而过期的任何日志段。
* Whether or not deletion is enabled, delete any log segments that are before the log start offset
* 无论是否启用删除,删除日志开始偏移量之前的所有日志段
*/
def deleteOldSegments(): Int = {
if (config.delete) {
deleteLogStartOffsetBreachedSegments() +
//删除超过规定大小的
deleteRetentionSizeBreachedSegments() +
//删除超过保存时间的
deleteRetentionMsBreachedSegments()
} else {
deleteLogStartOffsetBreachedSegments()
}
}
private def deleteRetentionMsBreachedSegments(): Int = {
//retention.ms 小于0代表不设置保存时间
if (config.retentionMs < 0) return 0
val startMs = time.milliseconds
def shouldDelete(segment: LogSegment, nextSegmentOpt: Option[LogSegment]): Boolean = {
startMs - segment.largestTimestamp > config.retentionMs
}
deleteOldSegments(shouldDelete, RetentionMsBreach)
}
private def deleteRetentionSizeBreachedSegments(): Int = {
//retention.bytes 小于0代表不删,或者当前topic的此分区的日志大小小于设置的值,也不用删
if (config.retentionSize < 0 || size < config.retentionSize) return 0
var diff = size - config.retentionSize
def shouldDelete(segment: LogSegment, nextSegmentOpt: Option[LogSegment]): Boolean = {
if (diff - segment.size >= 0) {
diff -= segment.size
true
} else {
false
}
}
deleteOldSegments(shouldDelete, RetentionSizeBreach)
}
/**
* Delete any log segments matching the given predicate function,
* starting with the oldest segment and moving forward until a segment doesn't match.
*删除与给定谓词函数匹配的任何日志段,
* 从最旧的段开始并向前移动,直到段不匹配
* @param predicate A function that takes in a candidate log segment and the next higher segment
* (if there is one) and returns true iff it is deletable
* 一个函数,它接受一个候选日志段和下一个更高的段 (如果有的话),如果它是可删除的,则返回 true
* @return The number of segments deleted
*/
private def deleteOldSegments(predicate: (LogSegment, Option[LogSegment]) => Boolean,
reason: SegmentDeletionReason): Int = {
lock synchronized {
//deletable,可以任务是可删除的segment集合
val deletable = deletableSegments(predicate)
if (deletable.nonEmpty)
//这里实际执行删除操作
deleteSegments(deletable, reason)
else
0
}
}
看上面的代码就知道,如果你配置了按最大超时时间和日志最大存储大小,那两个定时清理都会被执行
(1)deletableSegments(把需要删除的segment加入待删除的集合)
/**
* Find segments starting from the oldest until the user-supplied predicate is false or the segment
* containing the current high watermark is reached. We do not delete segments with offsets at or beyond
* the high watermark to ensure that the log start offset can never exceed it. If the high watermark
* has not yet been initialized, no segments are eligible for deletion.
*从最旧的开始查找段,直到用户提供的谓词为假或到达包含当前高水位线的段 。
* 我们不会删除偏移量等于或超过高水位线的段,以确保日志开始偏移量永远不会超过它。
* 如果高水位线尚未初始化,则没有段符合删除条件。
* A final segment that is empty will never be returned (since we would just end up re-creating it).
*永远不会返回空的最终段(因为我们最终会重新创建它)。
* @param predicate A function that takes in a candidate log segment and the next higher segment
* (if there is one) and returns true iff it is deletable
* 一个函数,它接受一个候选日志段和下一个更高的段(如果有的话),如果它是可删除的,则返回 true
* @return the segments ready to be deleted
*/
private def deletableSegments(predicate: (LogSegment, Option[LogSegment]) => Boolean): Iterable[LogSegment] = {
if (segments.isEmpty) {
Seq.empty
} else {
val deletable = ArrayBuffer.empty[LogSegment]
val segmentsIterator = segments.values.iterator
var segmentOpt = nextOption(segmentsIterator)
while (segmentOpt.isDefined) {
val segment = segmentOpt.get
val nextSegmentOpt = nextOption(segmentsIterator)
//upperBoundOffset 当前Segment最大偏移量, isLastSegmentAndEmpty 是否是最后一个Segment
val (upperBoundOffset: Long, isLastSegmentAndEmpty: Boolean) =
nextSegmentOpt.map {
nextSegment => (nextSegment.baseOffset, false)
}.getOrElse {
(logEndOffset, segment.size == 0)
}
//如果本segment最大偏移量 <= highWatermark 且在偏函数中返回true 且不是最后一个Segment, 则加入可删除队列中
if (highWatermark >= upperBoundOffset && predicate(segment, nextSegmentOpt) && !isLastSegmentAndEmpty) {
deletable += segment
segmentOpt = nextSegmentOpt
} else {
segmentOpt = Option.empty
}
}
deletable
}
}
这里需要注意,在segment加入待删除集合之前,必须有isLastSegmentAndEmpty的判断,代表的是如果此segment是最后一个(出现的条件就是此segment的大小长度还没超过segment.bytes,默认是1G),所以此segment就不会加入待删除的集合
注意: 通过上面的讲解的源码和说明,如果你每个分区的最后一个segment不超过segment.bytes ,那不会被日志清理清理掉
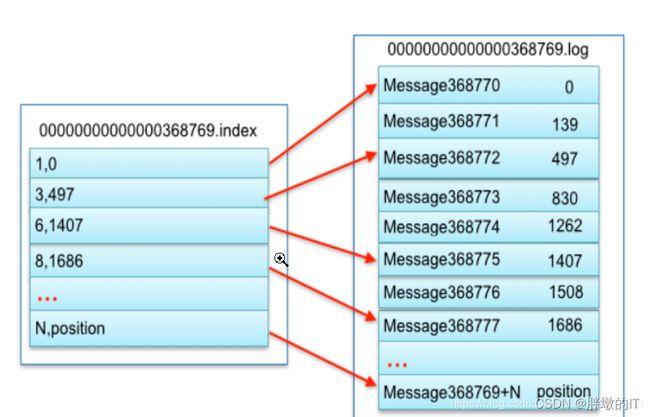
下面的每一个segment有什么,可以看Kafka的Log存储原理再析,下面是我复制过来的一张图
主要是index,log,timeindexs三种文件,

而index和log文件的映射是下面这种
(2) deleteSegments(对待删除的segment集合删除)
private def deleteSegments(deletable: Iterable[LogSegment], reason: SegmentDeletionReason): Int = {
maybeHandleIOException(s"Error while deleting segments for $topicPartition in dir ${dir.getParent}") {
val numToDelete = deletable.size
if (numToDelete > 0) {
// we must always have at least one segment, so if we are going to delete all the segments, create a new one first
//我们必须始终至少有一个段,所以如果我们要删除所有段,请先创建一个新段
if (numberOfSegments == numToDelete)
roll()
lock synchronized {
checkIfMemoryMappedBufferClosed()
// remove the segments for lookups 删除用于查找的段
removeAndDeleteSegments(deletable, asyncDelete = true, reason)
maybeIncrementLogStartOffset(segments.firstSegment.get.baseOffset, SegmentDeletion)
}
}
numToDelete
}
}
/**
* Roll the log over to a new active segment starting with the current logEndOffset.
* This will trim the index to the exact size of the number of entries it currently contains.
*将日志滚动到从当前 logEndOffset 开始的新活动段。 这会将索引修剪为它当前包含的条目数的确切大小
* @return The newly rolled segment
*/
def roll(expectedNextOffset: Option[Long] = None): LogSegment = {
maybeHandleIOException(s"Error while rolling log segment for $topicPartition in dir ${dir.getParent}") {
val start = time.hiResClockMs()
lock synchronized {
checkIfMemoryMappedBufferClosed()
//预计下一个偏移量,expectedNextOffset是none则是0,logEndOffset则是最后的offset
val newOffset = math.max(expectedNextOffset.getOrElse(0L), logEndOffset)
val logFile = Log.logFile(dir, newOffset)
if (segments.contains(newOffset)) { //说明segment的文件已经生成
// segment with the same base offset already exists and loaded 具有相同基本偏移量的段已存在并已加载
if (activeSegment.baseOffset == newOffset && activeSegment.size == 0) {//如果活跃的segment的startOffset等于newOffset并且活跃的segment的size=0
// We have seen this happen (see KAFKA-6388) after shouldRoll() returns true for an
// active segment of size zero because of one of the indexes is "full" (due to _maxEntries == 0).
//我们已经看到在 shouldRoll() 为大小为零的活动段返回 true 之后发生这种情况(参见 KAFKA-6388),因为其中一个索引是“满的”(由于 _maxEntries == 0)。
warn(s"Trying to roll a new log segment with start offset $newOffset " +
s"=max(provided offset = $expectedNextOffset, LEO = $logEndOffset) while it already " +
s"exists and is active with size 0. Size of time index: ${activeSegment.timeIndex.entries}," +
s" size of offset index: ${activeSegment.offsetIndex.entries}.")
//删除activeSegment
removeAndDeleteSegments(Seq(activeSegment), asyncDelete = true, LogRoll)
} else {
throw new KafkaException(s"Trying to roll a new log segment for topic partition $topicPartition with start offset $newOffset" +
s" =max(provided offset = $expectedNextOffset, LEO = $logEndOffset) while it already exists. Existing " +
s"segment is ${segments.get(newOffset)}.")
}
} else if (!segments.isEmpty && newOffset < activeSegment.baseOffset) {//segments存在并且低于活跃segment的startOffset
throw new KafkaException(
s"Trying to roll a new log segment for topic partition $topicPartition with " +
s"start offset $newOffset =max(provided offset = $expectedNextOffset, LEO = $logEndOffset) lower than start offset of the active segment $activeSegment")
} else {
val offsetIdxFile = offsetIndexFile(dir, newOffset)
val timeIdxFile = timeIndexFile(dir, newOffset)
val txnIdxFile = transactionIndexFile(dir, newOffset)
for (file <- List(logFile, offsetIdxFile, timeIdxFile, txnIdxFile) if file.exists) {
warn(s"Newly rolled segment file ${file.getAbsolutePath} already exists; deleting it first")
Files.delete(file.toPath)
}
segments.lastSegment.foreach(_.onBecomeInactiveSegment())
}
// take a snapshot of the producer state to facilitate recovery. It is useful to have the snapshot
// offset align with the new segment offset since this ensures we can recover the segment by beginning
// with the corresponding snapshot file and scanning the segment data. Because the segment base offset
// may actually be ahead of the current producer state end offset (which corresponds to the log end offset),
// we manually override the state offset here prior to taking the snapshot.
//拍摄生产者状态的快照以方便恢复。让快照
// 偏移量与新的段偏移量对齐很有用,因为这样可以确保我们可以通过
// 从相应的快照文件开始并扫描段数据来恢复段。因为段基偏移量
// 实际上可能在当前生产者状态结束偏移量之前(对应于日志结束偏移量),
// 我们在拍摄快照之前手动覆盖了这里的状态偏移量。
producerStateManager.updateMapEndOffset(newOffset)
producerStateManager.takeSnapshot()
val segment = LogSegment.open(dir,
baseOffset = newOffset,
config,
time = time,
//segment.bytes 规定segment的大小
initFileSize = config.initFileSize,
preallocate = config.preallocate)
//添加新的segment
addSegment(segment)
// We need to update the segment base offset and append position data of the metadata when log rolls.
// The next offset should not change.
//我们需要在日志滚动时更新段基偏移量并附加元数据的位置数据。 下一个偏移量不应该改变
updateLogEndOffset(nextOffsetMetadata.messageOffset)
// schedule an asynchronous flush of the old segment 安排旧段的异步刷新
scheduler.schedule("flush-log", () => flush(newOffset), delay = 0L)
info(s"Rolled new log segment at offset $newOffset in ${time.hiResClockMs() - start} ms.")
segment
}
}
}