【数据库学习】Postgres原理及底层实现
pg基础语法
1,事务原理
事务(transaction):
是用户定义的一组数据库操作,要么全做要么全不做,失败即回滚。
事务是恢复和并发控制的基本单元。
保存点(savePoint)
在一个大的事务中,可以把操作过程分成几个部分,第一个部分执行成功后可以建一个保存点,若后面的部分执行失败,则回滚到此保存点,而不必回滚整个事务。
事务的实现即:RDBMS采取何种技术确保事务的ACID特性?
回退(rollback):
撤销sql执行过程。事务管理可以管理insert、update、delete语句;不能回退create、drop操作。
RDBMS(Relational Database Management System,关系数据库管理系统)
是指包括相互联系的逻辑组织和存取这些数据的一套程序 (数据库管理系统软件)。
关系数据库管理系统就是管理关系数据库,并将数据逻辑组织的系统。
1)事务特性(ACID)
1>原子性(Atomic)
事务是数据库的逻辑工作单位。要么都做,要么都不做。==》通过MVCC保证
2> 一致性(Consistency)==》最终目的
事务完成时,数据必须处于一致状态,数据的完整性约束没有被破坏,事务在执行过程中发生错误,会被回滚到事务开始前的状态。
3>隔离性(Isolation)
事务允许多个用户对同一个数据进行并发访问,而不破坏数据的正确性和完整性。==》用锁和MVCC来保证。
读读不存在并发问题;
读写通过MVCC来解决并发问题;
写写通过加锁来解决并发问题。
4>永久性(Durability)
事务一旦提交,所做修改会永久的保存在数据库中。==》保证了db的可靠性,用WAL日志来实现
其中一致性是事务的最终目的,为了达到一致性需要保证原子性、隔离性、永久性。
那么pg是怎么完成ACID的呢?
2)pg隔离级别
在标准SQL规范中,定义了4个事务隔离级别(由低到高):
| 读未提交(RU级别、read uncommitted) | 读已提交(read committed) | 可重复读(repeatable read) | 序列化(serializable) | |
|---|---|---|---|---|
| 允许操作 | 允许事务读取未被其他事务提交的变更 | 允许事务读取已经被其他事务提交的变更 | 事务读取数据时,禁止其他事务对这个字段进行更新 | 所有事务都一个接一个地串行执行 |
| 可能存在问题 | 脏读、不可重复读、幻读 | 不可重复读、幻读 | 幻读==》添加间隙锁解决此类问题 | 数据安全。但是添加大量行锁会导致大量超时和锁竞争问题。 |
| 避免问题 | ||||
| 举例 | 事务读到了其他事务未提交的数据。其他事务回滚导致脏读。 | 同一个事务读了两次数据,分别读取了其他事务提交的内容,但是两次结果不一致。这就是不可重复读。 | 事务读了两次数据,不管数据怎么修改,都只读第一次的数据。==》导致幻读:每次select时,mvcc的read view不会变化。但是其他事务做了新增操作,真实的数据和当前的read view不同。 | |
| 数据库 | oracle、pg默认隔离级别 | mysql默认隔离级别 |
pg仅支持2种隔离级别:读已提交(默认)、可串行化。
事务隔离级别的实现:
- 读未提交/读已提交:每个query都会获取最新的快照CurrentSnapshotData
- 重复读:所有的query 获取相同的快照都为第1个query获取的快照FirstXactSnapshot
- 串行化:使用锁系统来实现
1>读已提交隔离级别(默认)
每个命令都是从一个新的快照开始执行的。
- 当前事务看不见其它未提交事务的数据;
- 当前事务可以看到自己未提交的数据;
- 一个事务里两个select,两次select读到的数据可能不是同一个快照。第二次select的时候会看到其它事务已提交的数据。
- 同一个事务中,第一次更新之后,其它事务获得锁进行数据的更新,当前事务中的更新操作需要等到其它事务结束或者回滚再进行操作。
为什么使用RC级别而不使用RR级别?
提高并发度并降低死锁概率。
2>可串行化隔离级别(开销大)
每个命令都是从事务开始时的快照开始执行的。
- 当前事务看不见其它未提交事务的数据;
- 当前事务可以看到自己未提交的数据;
- 只读事务不存在冲突:一个事务里两个select,两次select读到的数据一致。
- 串行化冲突:更新事务与其它更新事务冲突需要重试。
同一个事务中,第一次更新之后,其它事务获得锁进行数据的更新,当前事务中的更新操作需要等到其它事务结束或者回滚再进行操作。如果其它事务回滚,当前事务正常进行;如果其它事务提交,那么当前事务回滚(ERROR: could not serialize access due to concurrent update),需要重试。
3)多版本并发控制(MVCC,Multi-Version Concurrency Control)
MVCC是数据库并发访问时,保证数据一致性的一种方法。实现MVCC的方法有以下两种:
- 写新数据时,把原数据移到一个单独的位置,如回滚段中,其它用户读数据时,从回滚段中把原数据读出来。(Oracle和Mysql数据库中的InnoDB引擎使用这种方法)
- 写新数据时,原数据不删除,而是把新数据插入进来。(pg使用这种方法)==》相当于每个事务看到的都是之前一小段时间的数据快照(某一个数据库版本)。
1>原子性保证
事务ID:XID、txid(transaction id)
pg中每个事务开始时,事务管理器都会分配一个唯一id,从3开始递增。
32位无符号整数,取值空间:2^32-1;如果超过范围从头开始算,称为事务回卷。
pg中表中有以下4个内置表字段,每个tuple的更新时是先del旧的再insert新的tuple。
| 字段 | 说明 | 默认值 | 举例 |
|---|---|---|---|
| xmin | insert tuple 时的 xid | ||
| xmax | del tuple 时的 xid | 0,表示未删除 | |
| cmin | 事务内部 insert 的命令ID | 0,递增 | |
| cmax | 事务内部 del 的命令ID | 0,递增 | |
| ctid | 磁盘上的物理位置,格式:(page,offset) | (0,1)表示0号page的第1个位置。如果xmax=0,表示最新版本;如果xmax!=0,ctid指向更新后的元组,形成了版本链。 |
- insert tuple:
xmin=事务id xmax=0 ctid=(0,1),指向当前元组 - delete tuple:
xmax=事务id - update tuple,先delete,再insert:
tupleOld的xmax=事务id ctid指向新的元组,tupleNew的xmin=事务id ctid指向当前元组
原子性:通过当前事务id对tuple进行标记,不管是commit还是rollback操作都可以通过xmin和xmax保证事务的原子性。
2>事务隔离性保证
a)不同事务的可见性:xmin xmax
在不同事务中,可以根据xmin和xmax判断事务可见性。
快照(SnapshotData)
维护了以下一些信息:
- TransactionId xmin; // 记录了未提交并活跃的事务最小xid,如果t_xid < xmin则元组数据已提交:可见
- TransactionId xmax; //记录了已提交事务最大xid+1,如果t_xid >= xmax 则元组未提交:不可见
- TransactionId *xip; // 活动事务id列表
对于t_xid在[xmin, xmax)之间数据,需要结合clog日志判断其修改的数据是否可见
每次select获取当前db SnapshotData,判断数据的可见性。
区分元组t_xmin和快照s_xmin,对于当前元组数据:
- t_xmin
- t_xmin
- t_xmin
s_xmax,元组删除但未提交,可见; - 其它:需要结合clog进行判断。
- t_xmin
b)同一事务的可见性:cmin cmax
cmin、cmax 用于同一个事务中实现版本可见性判断
3>事务持久性保证
a)clog(commit log)日志
clog(commit log):
pg记录事务状态。包括以下四种:
transaction_status_in_progress =0x00:表示事务正在进行中
transaction_status_committed =0x01:表示事务已提交
transaction_status_aborted =0x02:表示事务已回滚
transaction_status_sub_committed =0x03:表示子事务已提交
结构:数组,由缓存(SLRU Buffer Pool )中一系列的8K页面组成。
数组下标对应事务txid,数组内容则为事务状态。每个事务状态2bit,一个块8KB可以存储8KB*8/2 = 32K个事务的状态。
当shutdown pg或Checkpoint运行时,CLOG数据会由内存写入pg_clog(pg 10后叫pg_xact)目录中的文件。这些文件被命名为0000,0001,最大256KB。当pg启动时,会加载这些文件用于初始化CLOG。
CLOG数据会不断增长,但并非所有数据都是必要的,清理过程也会定期清理掉不再需要的CLOG页面和文件。
pg可以通过调用三个内部函数——TransactionIdIsInProcess、TransactionIdDidCommit和TransactionIdDidAbort,读取CLOG返回所请求事务状态。
b)Hint Bits
判断元组的可见性非常频繁,每次从缓存或者磁盘读取clog信息依然不够高效,引入了Hint Bits概念。t_informask中存储的一些标志位保存了插入/删除该元组的事务的状态。
元组中的 Hint Bits采用延迟更新策略,并不会在事务提交或者回滚时主动更新所有操作过的元组Hint Bits。
等到第一次访问(可能是VACUUM,DML或SELECT)该元组并进行可见性判断时:
- 如果Hint Bits已设置,直接读取Hint Bits的值。
- 如果Hint Bits未设置,则调用函数从CLOG中读取事务状态。如果事务状态为COMMITTED或ABORTED,则将Hint Bits设置到元组的t_informask字段。如果事务状态为INPROCESS,由于其状态还未到达终态,无需设置Hint Bits。
4>MVCC的优缺点
pg在事务提交前,只需要访问原来的数据;提交后,系统更新元组的存储标识,直到Vaccum进程回收为止。
相比InnoDB和Oracle,pg多版本优势在于:
- 事务回滚可以立即完成;
- 数据可以进行很多更新,不必像Oracle和InnoDB那样需要经常保证回滚段不会被用完,也不会像Oracle数据库那样,经常遇到ORA-1555错误的困扰。
劣势在于:
- 旧数据需要Vaccum清理。
- 旧版本数据的存在降低查询速率,需要扫描更多的数据块。
4)表膨胀问题
1>Visibility Map机制:
官方文档:Routine Vacuuming
Visibility Map中标记了哪些page中是没有dead tuple的,数据量很小可以cache到内存中。这有两个好处:
- 当vacuum时,可以直接跳过这些page
- 进行index-only scan时,可以先检查下Visibility Map。这样减少fetch tuple时的可见性判断,从而减少IO操作,提高性能
2>vacuum(表空间优化、收缩表)
VACUUM寻找不再被别的任何事务任何人看到的行。这些行可能是页的中间几行。
一般pg会有个异步任务自动执行,如果突然有大量数据执行update全表等操作,会让磁盘空间瞬间翻倍,需要手动执行vacuum,但是这个操作会锁表,用的时候慎重。
--加表名指定表 不加表名表示全局处理
vacuum t_lxs;
--获取表空间大小
--vacuum允许 pg重用该空间,但是,它不会将该空间返回给操作系统。
SELECT pg_relation_size('t_lxs');--8192
DELETE FROM t_lxs;
--如果从表中的某个位置开始,ALL rows are dead,VACUUM可以截断表。
VACUUM t_lxs;
SELECT pg_relation_size('t_lxs');--0
--但是大表末尾总有那么几行数据,靠VACUUM几乎很难释放空间。通过使用VACUUM FULL重排数据的磁盘位置,可以解决表膨胀的问题。但是这个操作会直接锁表。一定要在业务低频使用时进行。
VACUUM FULL t_lxs;
5)事务id回卷
1>系统预留事务ID:0 1 2
0 1 2是系统预留ID,这三个ID比任何普通xid都要旧。
- InvalidTransactionId=0 无效的事务ID;表示还未分配事务ID。
- BootstrapTransactionId=1 表示系统表初始化时的事务ID;表示Initdb服务正在初始化系统表。
- FrozenTransactionId=2 冻结的事务ID。
2>回卷
xid一直递增达到2^32为最大值,然后继续从3开始,以前的xid比新的xid大,回卷后无法按xid大小判断数据可见性。
回卷问题导致事务id可见性的判断怎么解决?
- pg规定,最早和最新两个事务之间年龄差对多为231。==>事务冻结来保证
即:xid空间虽然有232,作为一个环被一分为二,对某个特定的xid,其后231个xid属于未来,均不可见;其前231个xid属于过去,可见。 - 俩个事务之间id的计算使用2^31取模的方法来进行事务的比较:
diff = (int32) (id1 - id2);来判断id1
举例:txid=100的事务,[101,231+100] 均为不可见事务;[231+101, 99] 均为可见事务。
 代码解析:
代码解析:
/*
* TransactionIdPrecedes --- is id1 logically < id2?
*/
bool TransactionIdPrecedes(TransactionId id1, TransactionId id2) // 结果返回一个bool值
{
int32 diff;
if (!TransactionIdIsNormal(id1) || !TransactionIdIsNormal(id2)) //若其中一个不是普通id,则其一定较新(较大)
return (id1 < id2);
diff = (int32) (id1 - id2);
return (diff < 0);
}
普通xid比较:diff = (int32) (id1 - id2);
注意:int 32带符号,第一位表示符号位,取值范围为 [-2(n-1), 2(n-1)-1],即[-231,231-1]。
当两个txid(32位)相减 (id1 - id2)>231时,发生回卷,转换位int32时符号位从0变成了1,(int 32) (id1 - id2)是个负数。此时id1
但是如果xid=100确实是很久很久的事务,那么对于231+101这个事务看见,此时上面的判断就是错的。为了避免这种问题,pg必须保证一个数据库中两个有效的事务之间的年龄最多是231(同一个数据库中,存在的最旧和最新两个事务txid相差不得超过231)。这时靠事务冻结来保证。
3>事务冻结(freeze)
当超过231时,就把旧的事务换成一个FrozenTransactionId=2的特殊事务,当正常事务ID与冻结事务ID比较时,会认为正常xid比FrozenTransactionId更新。
a)freeze实现:
- pg9.4之前freeze方法:
直接将符合条件的元组的t_xmin设置为2,回收原来的xid。但这样实现的问题是:
一)当前可见的数据页需要全部扫描,带来大量的IO扫描;
二)符合条件的元组需要更新xmin,造成大量脏页,带来大量IO - pg9.4后对freeze优化:
不直接修改t_xmin,而是:
一)只更新元组头结点的t_infomask为HEAP_XMIN_FROZEN,表示该元组已经被冻结过(frozen);
二)有些插入操作,也可以直接将记录置为frozen,例如大批量的COPY数据,insert into等;
三)如果整个page所有记录已经frozen,则在vm文件中标记为FROZEN,冻结清理会跳过该页,减少了IO扫描。
b)freeze优化:
freeze是被动触发的,可以调节pg的一些参数优化freeze,更多时候提倡用户进行主动预测需要freeze的时机,选择合适的时间(比如pg负载较低的时间)主动执行vacuum freeze命令。
目前已经有很多实现好的开源PostgreSQL vacuum freeze监控管理工具,比如flexible-freeze,能够:确定数据库的高峰和低峰期;在数据库低峰期创建一个cron job执行flexible_freeze.py;flexible_freeze.py会自动对具有最老XID的表进行vacuum freeze。
2,进程架构模型
启动pg,主进程为Postmaster(pg的bin目录下,是一个指向Postgres的链接)。Postmaster是整个数据库实例的总控进程,负责启动和关闭数据库实例,同时fork出一些与数据库实例相关的辅助进程,并对其进行管理。
| 辅助进程 | 作用 | 配置 |
|---|---|---|
| Logger | 系统日志 | 参数logging_collect设置为on时启动该辅助进程 |
每次客户端与数据库建立连接时,pg数据库都会启动一个服务进程来为该连接服务,故而是进程架构模型,而MySQL是线程架构模型。当某个服务进程报错时,Postmaster主进程会自动完成系统恢复,恢复过程中停掉所有的服务进程,然后进行数据的一致性恢复,恢复完成后数据库才能接受新的连接。
1)autovacuum进程
autovacuum 是 postgresql 里非常重要的一个服务端进程,能够自动运行,在一定条件下自动触发对 dead tuples 进行清理并对表进行分析。
在pg中更新、删除行后,数据行并不会马上从数据块中清理掉,而是需要等VACUUM时时清理。为了加快VACUUM速度并降低对系统I/O性能的影响,pg8.4.1之后为每个数据块文件加了一个后缀为“_vm”的文件(可见性映射表文件,VM文件)。这个文件为每个数据块存储了一个标志位,标记数据块中是否存在要清理的tuple。
VACUUM有两种方式:
- Lazy VACUUM :使用VM文件,扫描部分数据块。
- Full VACUUM :全量扫描数据块。
vacuum相关的配置:
| 参数名 | 说明 | 优化思路 |
|---|---|---|
| autovacuum | 默认为on,表示是否开起autovacuum。当需要冻结xid时,尽管此值为off,PG也会进行vacuum。 | |
| autovacuum_naptime | 下一次vacuum的时间,默认1min | 通过缩短实际,调整回收频率,减少每次回收量,可以减小wal压力 |
| log_autovacuum_min_duration | 向日志打印autovacuum的统计信息(以及资源消耗),大于阈值,输出这次autovacuum触发的事件的统计信息 。 “-1”表示不记录。“0”表示每次都记录。 | |
| autovacuum_max_workers | 最大同时运行的worker数量,不包含launcher本身。 | CPU核多、IO优秀时,当DELETE\UPDATE非常频繁时适量调多点。注意最多可能消耗这么多内存: # autovacuum_max_workers * autovacuum mem(autovacuum_work_mem) |
| autovacuum_vacuum_threshold | 默认50。与autovacuum_vacuum_scale_factor(默认值为20%)配合使用。当update,delete的tuples数量超过autovacuum_vacuum_scale_factor*table_size+autovacuum_vacuum_threshold时,进行vacuum。 | 改小可以降低vacuum触发条件,提高vacuum频率 |
| autovacuum_analyze_threshold | 默认50。与autovacuum_analyze_scale_factor(默认10%)配合使用。当update,insert,delete的tuples数量超过autovacuum_analyze_scale_factor*table_size+autovacuum_analyze_threshold时,进行analyze。 | 改小可以降低vacuum触发条件,提高vacuum频率 |
| autovacuum_freeze_max_age和autovacuum_multixact_freeze_max_age | 前者200 million,后者400 million。离下一次进行xid冻结的最大事务数。 如果表的事务ID年龄大于该值, 即使未开启autovacuum也会强制触发FREEZE,并告警Preventing Transaction ID Wraparound Failures。 | 设置较大值,减少因事务id消耗造成全表扫描的频率。(1000million、1200million) |
| autovacuum_vacuum_cost_delay | 如果为-1,取vacuum_cost_delay值。autovacuum触发的vacuum、freeze、analyze的平滑化调度。 | 设置过大,会导致AUTOVACUUM launcher触发的vacuum耗时过长。特别是大表,耗时会非常长,可能导致膨胀等问题。可以调小一点,0. |
| autovacuum_vacuum_cost_limit | 如果为-1,到vacuum_cost_limit的值,这个值是所有worker的累加值。 | |
| vacuum_freeze_table_age | 当表的年龄大于vacuum_freeze_table_age,则自动转换成vacuum freeze | 调高可以降低vacuum freeze的频率 |
| vacuum_multixact_freeze_table_age | 当表的年龄大于autovacuum_freeze_max_age,也会强制触发vacuum freeze | 调高可以降低vacuum freeze的频率 |
- 如果开启了autovacuum,当垃圾记录数大于 autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor*reltuples ,autovacuum launcher触发普通的vacuum。
当表的年龄大于vacuum_freeze_table_age,则自动转换成vacuum freeze。 - 如果开启了autovacuum,当新增记录数大于autovacuum_analyze_threshold + autovacuum_analyze_scale_factor*reltuples,autovacuum launcher触发analyze。
- 即使没有开启autovacuum,当表的年龄大于autovacuum_freeze_max_age,也会强制触发vacuum freeze。
3,pg物理存储结构:堆表结构
Relation: 表(table)或索引(Index)。
Page:磁盘中的数据块 。
Buffer:内存中的数据块。
1)堆表结构
每个表由若干文件组成(表大小超过 RELSEG_SIZE 个块就会被切分成多个文件);
每个文件由若干块(block)构成;
每个数据块存储了多行数据(tuple)。
堆表和索引是分开存储的,而mysql是索引组织的数据存储。
pg的索引存储:索引、tuple地址。
2)数据块(页)
数据块大小为 BLCKSZ,默认 8KB,最大为32KB。
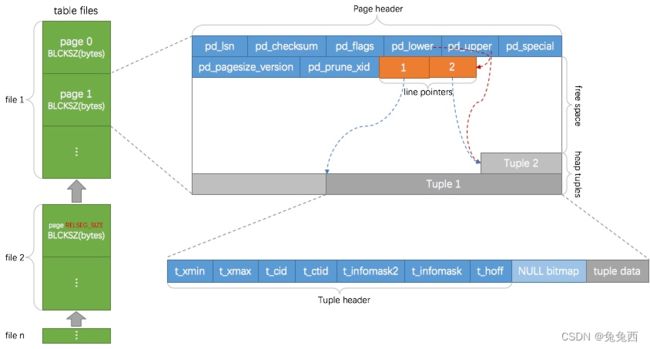
块的结构:
- 块头(Page Header) :
a. 块的checksum值;
b. 空闲空间的起始位置和结束位置;
c. 特殊数据的起始位置;
d. 其它信息。 - 行指针:向后顺序排列。是一个32bit的数字,具体结构:
a. 行内容偏移量,15bit;能表示的最大偏移量是215,因此pg中块最大为32kb
b. 指针的标记,2bit;
c. 行内容的长度,15bit。 - 空闲空间:行数据指针和行数据内容之间的空间。
- 行内容:从块尾向前反向排列。
3)Tuple(数据行、元组)
pg中元组由三部分组成——元组头结点、空值位图、用户数据。
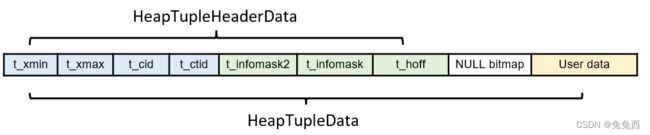
HeapTupleHeaderData结构:Database Page Layout,pg提供了pageinspect插件,可查看指定表对应的page header内容。
相关字段说明:
| 字段 | 说明 | 备注 |
|---|---|---|
| t_xmin | 保存插入该元组的事务txid(该元组由哪个事务插入) | 对应pgclass内置字段xmin |
| t_xmax | 保存更新或删除该元组的事务txid。若该元组尚未被删除或更新,则t_xmax=0,即invalid | 对应pgclass内置字段xmax |
| t_cid | 保存命令标识(command id,cid),指在该事务中,执行当前命令之前还执行过几条sql命令(从0开始计算) | 对应pgclass内置字段cmin cmax |
| t_ctid | 一个指针,保存指向自身或新元组的元组的标识符(tid) | 对应pgclass内置字段ctid |
| t_xvac | 存储的是VACUUM FULL 命令的事务ID | |
| t_infomask2 | number of attributes, plus various flag bits | |
| t_infomask | 各种标志位,标识元组的属性、状态 | 比如:是否具有空属性、是否具有变长的属性、是否包含外部存储的字段、事务提交状态 |
| t_hoff | offset to user data,行header的长度 |
4,锁机制
使用多版本并发控制(MVCC)比锁定模型(mysql的锁机制)的优势:读锁和写锁不再互斥。
1)pg常见锁
1>表锁
表锁由内置的 SQL 命令获得的,同时可以通过锁命令来明确获取。
| 表锁 | 获得情况 | 冲突对象 | 备注 |
|---|---|---|---|
| 访问共享(ACCESS SHARE) | SELECT读表 | ACCESS EXCLUSIVE | |
| 行共享(ROW SHARE | SELECT FOR UPDATE 和 SELECT FOR SHARE 读表 | EXCLUSIVE、 ACCESS EXCLUSIVE | |
| 行独占(ROW EXCLUSIVE) | UPDATE、INSERT 和 DELETE 读表 | SHARE, SHARE ROW EXCLUSIVE, EXCLUSIVE, ACCESS EXCLUSIVE | |
| 访问独占(ACCESS EXCLUSIVE) | ALTER TABLE,DROP TABLE,TRUNCATE,REINDEX,CLUSTER 和 VACUUM FULL 命令读表时获得 | 与所有模式冲突(包括其自身) | LOCK 命令的默认模式。保证事务是可以访问该表的唯一事务。 |
| 共享更新独占(SHARE UPDATE EXCLUSIVE) | VACUUM(不含FULL),ANALYZE,CREATE INDEX CONCURRENTLY,和一些 ALTER TABLE 的命令获得该锁 | ||
| 共享(SHARE) | CREATE INDEX 命令在查询中引用的表上获得该锁。 | ||
| 共享行独占(SHARE ROW EXCLUSIVE) | 不被任何命令隐式获取。 | ||
| 排他(EXCLUSIVE) | 这个锁模式在事务获得此锁时只允许读取操作并行。它不能由任何命令隐式获取。 |
2>行锁
行级锁不影响对数据的查询,它们只阻塞对同一行的写入。
行锁容易发生死锁。==》 pg自动侦测死锁条件,然后退出其中一个事务从而允许其它事务完成来解决死锁问题。
3>页面级别的共享/排他锁
用于控制共享缓冲池中表页面的读/写。这些锁在抓取或者更新一行后马上被释放。不需要过多关注
4>sql
- 死锁的查询与释放
--查死锁
select pid from pg_locks where relation= (
select oid from pg_class where relname='表名'
);
--释放锁
--方式1:
select pg_cancel_backend('上面查询到的pid');
--方式2:
select pg_terminate_backend('上面查询到的pid');
2)谓词锁定(pg不支持)
谓词锁定:
禁止当前事务插入另一个并发事务的where条件,直到其它任务提交
--隐患:当前事务的select中的where条件与另一个并发事务的insert内容相同,导致并发事务:A和B的执行顺序不同结果不同。
--事务1
SELECT ... WHERE class = 1;
Insert class = 10 ...
--事务1
SELECT ... WHERE class = 10;
Insert class = 1 ...
如何处理这种情况?
- insert select 合成一条sql
将业务逻辑融入了sql中,扩展性差。 - 加锁
- CAS
3)服务器参数说明
通过show 参数 sql语句可以查看当前设置值,修改后需要重启计算机才可以生效。
| 参数 | 默认值 | 说明 | 调优 |
|---|---|---|---|
| deadlock_timeout | 1s | 进行死锁检测之前在一个锁上等待的总时间(以毫秒计)。增加这个值就减少了浪费在无用的死锁检测上的时间,但是减慢了报告真正死锁错误的速度。 | 在一个高负载的服务器上,可能需要增大它。这个值的理想设置应该超过通常的事务时间 |
| log_lock_waits | off | 如果一个会话等待某个类型的锁的时间超过deadlock_timeout的值,该参数决定是否在数据库日志中记录这个信息。 | |
| max_locks_per_transaction | 64 | 共享锁表跟踪在 max_locks_per_transaction * ( max_connections + max_prepared_transactions ) 个对象(如表)上的锁。因此,在任何一个时刻,只有不超过这么多个可区分对象能够被锁住,超过这个数量会报错。 |
如果想在一个事务中使用很多不同表的查询(例如查询一个有很多子表的父表),则需要提高这个值。 |
| max_connections | 151 | 表示允许客户端并发连接的最大数量 | 最小值为1,最大值为100000 |
| max_prepared_transactions | 设置可以同时处于prepared状态的事务的最大数目 | 设置为0表示不使用预备事务;否则max_prepared_transactions至少与max_connections一样大,以便每个会话都可以有一个待处理的预备事务。 |
5, 主从同步
1)概念
主备数据库(Primary db,Master db)
备数据库(Standby db)
高可用:
Master db失败后,备数据库(Standby db)快速提升为Master db并提供服务。
高可靠性:
Master bd和Standby db存在数据同步,从而提高数据的可靠性。通常是一台master db提供读写,然后把数据同步到量一台standby db(只读)。
1>数据库备份分类
冷备 (Cold Standby)
定期对生产系统数据库备份,并将备份数据 存储在磁带、磁盘等介质上。备份的数据平时处于一种非激活的状态,直到故障发生导致生产数据库系统部可用时才激活。冷备数据的时效性取决于最近一次的数据库备份。数据库冷备的周期一般较长。
热备 (Warm Standby)
定期将数据备份到Standby db,当发生故障时,通过备用数据库的数据进行业务恢复。
主要是通过不断将WAL日志回放,加载到备份数据库来实现的。
时效性来自最近一次备份。
完全热备 (Hot Standby)
Standby db和master db完全同步,Standby 提供只读服务(pg9.x提供).
2)主从同步的方案
WAL日志:
作用:记录了db数据文件的每次变更,最初设计是为了db异常崩溃后,能够重放最后一次checkpoint之后的日志文件,把数据块推到最终的一致状态,避免数据丢失和不一致。如果备份数据块数据不一致,也可以通过重放WAL日志恢复数据到某个时间点(check point)。==>基于时间点备份(PITR,Point-in-Time Recovery)
目录:pg_wal下。(10版本之前是pg_xlog目录)
方案:(hot standby )
master db提供读写,通过WAL重放把数据同步到Standby db(只提供读)。
把WAL日志传送到另一台机器的方法有两种:
1>WAL日志归档(base-file)
- 写WAL日志;
- 日志写完后,scp命令远程备份WAL日志文件到standby db;
==》备库会落后主库一个WAL日志文件,具体落后多长时间取决于master db生成一个wal文件的时间。
2>流复制(streaming replication)
pg9.x版本之后支持。
有两种方式:
- 同步方式,几乎没有延时。
- 异步方式,落后时间取决于网络延迟和standby的i/o能力。
3>主备同步wal相关配置
| 参数名 | 说明 | 优化方案 |
|---|---|---|
| synchronous_commit | 如果双节点,设置为ON,如果是多副本,同步模式,建议设置为remote_write。如果磁盘性能很差,并且是OLTP业务。可以考虑设置为off降低COMMIT的RT,提高吞吐(设置为OFF时,可能丢失部分XLOG RECORD) | |
| full_page_writes | 如果文件系统支持COW例如ZFS,则建议设置为OFF。 如果文件系统可以保证datafile block size的原子写,在对齐后也可以设置为OFF。 | |
| wal_writer_delay | wal写的延迟 | 缩短延迟,加快wal写的速度 |
| wal_writer_flush_after | ||
| checkpoint_timeout | 不建议频繁做检查点,否则XLOG会产生很多的FULL PAGE WRITE(when full_page_writes=on) | 提高该值,降低FULL PAGE WRITE,较少XLOG,降低wal压力 |
| max_wal_size | 建议等于SHARED BUFFER,或2倍。 | |
| min_wal_size | 建议是SHARED BUFFER的2分之一 | |
| wal_receiver_status_interval | 反馈给主节点自己已经接受( replies )到数据信息。 | 减小,加快反馈速度 |
| wal_buffers | 基于shared_buffers,shared_buffers/32 | 增大,加快wal落盘速度 |
4>相关问题解决
- 主从混乱
--pg排查:确定当前是否有主从混乱问题 如果role是一master多standby说明正常
show pool_nodes;
| node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change |
|---|---|---|---|---|---|---|---|---|---|
| 0 | xx.cn | 5432 | up | 1.000000 | primary | 200706 | true 0 | 2020-03-13 12:36:59 |
其中:
status:pgpool状态 (up、down)
role:primary (主节点) standby(从节点)
replication_delay:复制延迟。如果延时过大需要重建备库。
解决:
/postgresql/postgresql.conf位置下修改配置:
max_wal_size = 16GB
min_wal_size = 4GB
--登录主库,数据库重新加载配置
select pg_reload_conf();
3)备库激活
重建备库:
/postgresql/recovery.conf文件修改:(有这个文件的表示是从结点,主结点文件为recovery.done)
recovery_target_timeline = 'latest'
standby_mode = 'on'
primary_conninfo = 'host=postgresql.host port=5432 user=repuser password=xxx'
--重启数据库、重启pgpool即可
0,参考资料
PgSQL · 特性分析 · MVCC机制浅析
PgSQL · 特性分析 · 事务ID回卷问题
PgSQL · 引擎特性 · PostgreSQL Hint Bits 简介