2023网络安全面试题汇总(附答题解析+配套资料)
随着国家政策的扶持,网络安全行业也越来越为大众所熟知,相应的想要进入到网络安全行业的人也越来越多,为了更好地进行工作,除了学好网络安全知识外,还要应对企业的面试。
所以在这里我归总了一些网络安全方面的常见面试题,希望对大家有所帮助。
内容来自于社群内毕业生在毕业前持续整理、收集的安全岗面试题及面试经验分享~
注:所有的资料都整理成了PDF,面试题和答案将会持续更新,因为无论如何也不可能覆盖所有的面试题。

目录
一、字节跳动-渗透测试实习生
二、深信服-漏洞研究员实习
三、字节跳动-安全研究实习生
四、长亭科技-安全服务工程师
五、腾讯-安全技术实习生
六、小鹏汽车-安全工程师
七、大厂高频面试题汇总
7.1、SQL注入防护方法
7.2、常见的Web安全漏洞
7.3、给你一个网站你是如何来渗透测试的?
7.4、渗透测试流程
7.5、SQL注入类型
7.6、SQL注入的原理
7.7、如何进行SQL注入的防御
7.8、sqlmap,怎么对一个注入点注入?
7.9、mysql的网站注入,5.0以上和5.0以下有什么区别?
7.10、MySQL存储引擎?
7.11、什么是事务?
7.12、读锁和写锁
7.13、MySQL的索引
7.14、ORDER BY在注入的运用
7.15、GPC是什么?GPC之后怎么绕过?
7.16、Mysql一个@和两个@什么区别
7.17、注入/绕过常用的函数
7.18、盲注和延时注入的共同点?
7.19、如何拿一个网站的webshell?
7.20、sql注入写文件都有哪些函数?
7.21、各种写shell的问题
7.22、sql注入写文件都有哪些函数?
7.23、sql二次注入
7.24、SQL和NoSQL的区别
一、字节跳动-渗透测试实习生
- 自我介绍
- 渗透的流程
- 信息收集如何处理子域名爆破的泛解析问题
- 如何绕过CDN查找真实ip
- phpinfo你会关注哪些信息
- 有没有了解过权限维持
- 说一个你感觉不错的漏洞,展开讲讲
- 输出到href的XSS如何防御
- samesite防御CSRF的原理
- CSRF防御
- json格式的CSRF如何防御
- 浏览器解析顺序和解码顺序
- 过滤逗号的SQL注入如何绕过
- 过滤limit后的逗号如何绕过
- fastjson相关漏洞
- 说一个你知道的python相关的漏洞(SSTI原理,利用过程,payload相关的东西)开放性问答
二、深信服-漏洞研究员实习
- 自我介绍
- 在xx实习的时候做什么东西
- 渗透测试的思路简单说一下
- 护网在里面担当一个什么样的角色
- 红队的一些思路
- 拿下系统后有没有做横向
- 前段时间那个log4j有研究吗,可以简单说一下吗
- (继上一个问题)有哪些混淆绕过的方法
- 内存马有没有了解过
- 冰蝎、哥斯拉这些工具有没有了解过
- 做攻击队的时候有没有研究过什么攻击,比如研究一些工具还是魔改什么的
- 那么多漏洞和攻击,比较擅长哪一个
- 说一下shiro反序列化的形成原因、利用链
- 对一些bypass的方法有没有了解过,有什么姿势可以简单介绍一下
- 反问
三、字节跳动-安全研究实习生
- 你投的岗位是安全研究实习生,你了解我们这边主要是做什么的吗
- 自我介绍
- 现在有什么比较想做的方向吗,比如你写的代码审计、攻防演练、你在学校的研究方向(密码学)其实是三个大方向,现在有什么比较想做的吗
- 有没有审过开源框架、cms、中间件之类的
- 面试官介绍了工作内容
- 我看你简历上有几段实习经历和项目经历,先聊一下实习经历吧,在A主要做什么的
- 详细聊聊入侵测试主要在做什么,遇到的问题
- 关于入侵检测产生大量误报的原因,有没有分析过,有没有比较好的解决方法
- 和A比起来,B的应该就比较偏攻击方对吧,有打仗(雾,面试官好像确实是这么说的)有代码审计,聊一下在B主要做了些什么
- 审表达式引擎的步骤和思路
- 刚刚你说的审计听起来好像和普通开发的审计差不多,都是通过程序流、文档去做,有没有从安全方面入手审计一些项目
- xxe是怎么造成的,从代码层面来看
- 我看你简历有很多攻防演练经历对吧,这几段攻防演练经历有没有哪一次印象比较深刻的,挑一个聊一聊
- 你的这次攻击好像更多的是利用弱口令,有没有一些更有技巧的方法
- 这个头像上传的webshell是怎么上传的
- 还有什么其他的检验方式?要怎么绕过?
- 这两天log4j漏洞很火,有没有去了解一下
- 面试官最后介绍业务
- 反问环节
四、长亭科技-安全服务工程师
- 自我介绍
- web渗透测试有没有过实战
- 讲一下sql注入原理
- 有没有从代码层面了解过sql注入的成因(反问代码层面指的是不是sql语句,答是)
- 了不了解xss,有没有从代码层面了解xss的原理
- 对owasp top10漏洞哪个比较了解
- 讲一讲怎么防御sql注入
- sql注入怎么绕过过滤
- 问了护网时xx有没有成为靶标,有没有对攻击队行为做过研判
- 在xx护网时的工作内容,有没有做过流量包、数据包的研判
- 学校攻防演练时担任的角色,主要工作内容,渗透测试的思路,有什么成果(这个问的还是挺细的,具体到分配的任务、有没有拿下主机或者域控、攻防演练的形式和持续时间等都聊了)
- 平时ctf打的多不多,有什么成绩
- 平时会不会关注一些新颖的漏洞,会不会做代码审计,比如shiro漏洞等有没有做过漏洞复现
- 对钓鱼邮件这些有没有什么了解(因为上面聊xx护网时说了钓鱼邮件和微信钓鱼的事)
- 目前学习的方向是什么
- 最后介绍人才需求
- 反问环节
五、腾讯-安全技术实习生
- 自我介绍
- sql注入了解吗,讲一讲二次注入的原理
- 二次注入要怎么修复
- sql注入过waf了解吗,若一个sql注入过滤了information关键词,怎么绕过
- Redis未授权访问
- 渗透测试的一个完整流程
- 打ctf的时候有没有遇到什么印象特别深的题目
- 文件下载漏洞有没有什么比较好的利用方式
- 利用文件下载漏洞找文件名具体是找什么文件名(读取文件一般会读取哪些文件)(ctf中?实战中?)
- 命令执行漏洞,http不出网有什么比较好的处理方法(发散一点说)
- 接上一题,通过隧道通信,详细讲讲通过什么类型的隧道,讲讲具体操作
- 漏洞预警
- 有没有复现过中间件类型的漏洞(有没有完整的复现过漏洞)
- 在学校的攻防演练中扮演的角色的主要职责是什么
六、小鹏汽车-安全工程师
- 自我介绍
- 有没有挖过src?
- 平时web渗透怎么学的,有实战吗?有过成功发现漏洞的经历吗?
- 做web渗透时接触过哪些工具
- xxe漏洞是什么?ssrf是什么?
- 打ctf的时候负责什么方向的题
- 为什么要搞信息安全,对安全这一块有多大的兴趣,以后会不会转行,还是打算一直从事安全方面工作
- 自己平时怎么学安全的,如果让你做一个新的方向(app安全),会投入多少时间去学习,还是说有自己想做的方向
- 聊一聊代码审计的流程
- 平时是怎么做代码审计的
- 有没有审计过开源框架、CMS?
- 怎么判断一个数据库是mysql还是oracle的?
- sql注入的种类,利用方式?
- 聊一聊sql注入的原理及防御思路
- 做开发的时候用的是什么语言
- 做java开发的时候用过什么框架,能不能做java安全开发
- 有没有做过安卓开发
- 有没有用python写过工具?
- msf利用的是哪个漏洞,有没有成功反弹?
- 护网的时候主要做了些什么,聊一聊对安全产品的理解
- 公司现在需要做app安全的人,现在要你做的话,你会去学吗,或者说感兴趣吗,还是说有别的想做的,不想做app安全,能投入多少时间去学
- 内网渗透了解吗?聊一聊内网渗透的思路
七、大厂高频面试题汇总
这次花了三个月的时间整理各大安全厂商的网络安全职位(包括但不仅限于:安全服务工程师,安全运营工程师,安全,安全攻防工程师“)的面试问题。
话不多说,让我们一起学习吧
目前来说还有非常多的不严谨和冗余,恳请小伙伴们指正修改!
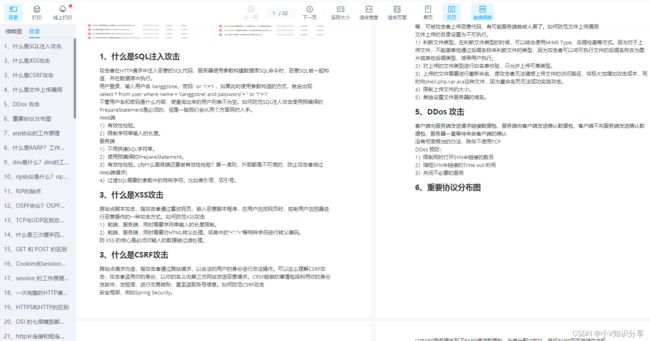
7.1、SQL注入防护方法
- 失效的身份认证和会话管理
- 跨站脚本攻击XSS
- 直接引用不安全的对象
- 安全配置错误
- 敏感信息泄露
- 缺少功能级的访问控制
- 跨站请求伪造CSRF
- 使用含有已知漏洞的组件
- 未验证的重定向和转发
7.2、常见的Web安全漏洞
- SQL注入
- XSS
- 文件遍历、文件上传、文件下载
- 垂直越权、水平越权
- 逻辑漏洞
- 首先对于新人来说,大多数同学都是没有实战经验的,对应面试官提问聊聊你的渗透测试实战,但很多人却无从开口。
7.3、给你一个网站你是如何来渗透测试的?
在获取书面授权的前提下。
1)信息收集
获取域名的whois信息,获取注册者邮箱姓名电话等。
查询服务器旁站以及子域名站点,因为主站一般比较难,所以先看看旁站有没有通用性的cms或者其他漏洞。
查看服务器操作系统版本,web中间件,看看是否存在已知的漏洞,比如IIS,APACHE,NGINX的解析漏洞
查看IP,进行IP地址端口扫描,对响应的端口进行漏洞探测,比如 rsync,心脏出血,mysql,ftp,ssh弱口令等
扫描网站目录结构,看看是否可以遍历目录,或者敏感文件泄漏,比如php探针
google hack 进一步探测网站的信息,后台,敏感文件
2)漏洞扫描
开始检测漏洞,如XSS,XSRF,sql注入,代码执行,命令执行,越权访问,目录读取,任意文件读取,下载,文件包含,
远程命令执行,弱口令,上传,编辑器漏洞,暴力破解等
3)漏洞利用
利用以上的方式拿到webshell,或者其他权限
4)权限提升
提权服务器,比如windows下mysql的udf提权,serv-u提权,windows低版本的漏洞,如iis6,pr,巴西烤肉,
linux藏牛漏洞,linux内核版本漏洞提权,linux下的mysql system提权以及oracle低权限提权
5) 日志清理
6)总结报告及修复方案
7.4、渗透测试流程
- 项目访谈
- 信息收集:whois、网站源IP、旁站、C段网站、服务器系统版本、容器版本、程序版本、数据库类型、二级域名、防火墙、维护者信息
- 漏洞扫描:Nessus, AWVS
- 手动挖掘:逻辑漏洞
- 验证漏洞
- 修复建议
- (如果有)基线检查/复验漏洞
- 输出报告
- 概述
- 测试基本信息
- 测试范围
- 测试时间
- 测试任务
- 测试过程
- 信息安全风险综合分析
- 整体风险分析
- 风险影响分析
- 系统安全分析
- 安全漏洞列表
- 解决方案建议
- 复测报告
- SQL面试题
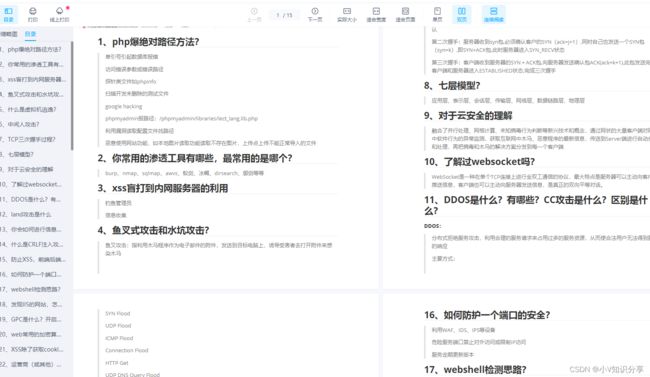
7.5、SQL注入类型
- 基于报错注入
- 基于布尔的注入,根据返回页面判断条件真假的注入
- 基于时间的盲注,不能根据页面返回内容判断任何信息,用条件语句查看时间延迟语句是否执行(即页面返回时间是否增加)来判断。
- 宽字节注入
- 联合查询,可以使用 union 的情况下的注入。
- 堆查询注入,可以同时执行多条语句的执行时的注入。
7.6、SQL注入的原理
通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。通常未经检查或者未经充分检查的用户输入数据或代码编写问题,意外变成了代码被执行。
7.7、如何进行SQL注入的防御
- 关闭应用的错误提示
- 加waf
- 对输入进行过滤
- 限制输入长度
- 限制好数据库权限,drop/create/truncate等权限谨慎grant
- 预编译好sql语句,python和Php中一般使用?作为占位符。这种方法是从编程框架方面解决利用占位符参数的sql注入,只能说一定程度上防止注入。还有缓存溢出、终止字符等。
- 数据库信息加密安全(引导到密码学方面)。不采用md5因为有彩虹表,一般是一次md5后加盐再md5
- 清晰的编程规范,结对/自动化代码 review ,加大量现成的解决方案(PreparedStatement,ActiveRecord,歧义字符过滤, 只可访问存储过程 balabala)已经让 SQL 注入的风险变得非常低了。
- 具体的语言如何进行防注入,采用什么安全框架
7.8、sqlmap,怎么对一个注入点注入?
- 如果是get型号,直接,sqlmap -u “诸如点网址”.
- 如果是post型诸如点,可以sqlmap -u "注入点网址” --data=“post的参数”
- 如果是cookie,X-Forwarded-For等,可以访问的时候,用burpsuite抓包,注入处用*号替换,放到文件里,然后sqlmap -r “文件地址”
7.9、mysql的网站注入,5.0以上和5.0以下有什么区别?
10年前就出了5.0,现在都到5.7了,没啥意义的问题
5.0以下没有information_schema这个系统表,无法列表名等,只能暴力跑表名。
5.0以下是多用户单操作,5.0以上是多用户多操做。
7.10、MySQL存储引擎?
1、InnoDB:主流的存储引擎。支持事务、支持行锁、支持非锁定读、支持外键约束
为MySQL提供了具有提交、回滚和崩溃恢复能力的事物安全(ACID兼容)存储引擎。InnoDB锁定在行级并且也在 SELECT语句中提供一个类似Oracle的非锁定读。这些功能增加了多用户部署和性能。在SQL查询中,可以自由地将InnoDB类型的表和其他MySQL的表类型混合起来,甚至在同一个查询中也可以混合
InnoDB存储引擎为在主内存中缓存数据和索引而维持它自己的缓冲池。InnoDB将它的表和索引在一个逻辑表空间中,表空间可以包含数个文件(或原始磁盘文件)。这与MyISAM表不同,比如在MyISAM表中每个表被存放在分离的文件中。InnoDB表可以是任何尺寸,即使在文 件尺寸被限制为2GB的操作系统上
InnoDB支持外键完整性约束,存储表中的数据时,每张表的存储都按主键顺序存放,如果没有显示在表定义时指定主键,InnoDB会为每一行生成一个6字节的ROWID,并以此作为主键
2、MyISAM:访问速度快,不支持事务,逐渐被淘汰
3、MEMORY:BTREE索引或者HASH索引。将表中数据放在内存中,并发性能差。
4、MERGE、Archive等等不常用的
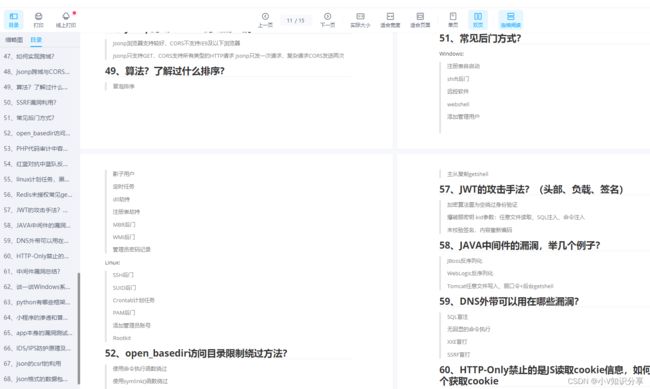
7.11、什么是事务?
事务是一组原子性的SQL语句或者说是一个独立的工作单元,如果数据库引擎能够成功对数据库应用这组SQL语句,那么就执行,如果其中有任何一条语句因为崩溃或其它原因无法执行,那么所有的语句都不会执行。也就是说,事务内的语句,要么全部执行成功,要么全部执行失败。
举个银行应用的典型例子:
假设银行的数据库有两张表:支票表和储蓄表,现在某个客户A要从其支票账户转移2000元到其储蓄账户,那么至少需求三个步骤:
a.检查A的支票账户余额高于2000元;
b.从A的支票账户余额中减去2000元;
c.在A的储蓄账户余额中增加2000元。
这三个步骤必须要打包在一个事务中,任何一个步骤失败,则必须要回滚所有的步骤,否则A作为银行的客户就可能要莫名损失2000元,就出问题了。这就是一个典型的事务,这个事务是不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,不可能只执行其中一部分,这也是事务的原子性特征。
7.12、读锁和写锁
读锁是共享的,即相互不阻塞的,多个客户在同一时刻可以读取同一资源,互不干扰。写锁是排他的,即一个写锁会阻塞其它的写锁和读锁,只有这样,才能确保给定时间内,只有一个用户能执行写入,防止其它用户读取正在写入的同一资源。写锁优先级高于读锁。
7.13、MySQL的索引
索引是帮助MySQL高效获取数据的数据结构。MYISAM和InnoDB存储引擎只支持BTree索引;MEMORY和HEAP储存引擎可以支持HASH和BTREE索引。
7.14、ORDER BY在注入的运用
order by后面可以加字段名,表达式和字段的位置,字段的位置需要是整数型。
7.15、GPC是什么?GPC之后怎么绕过?
如果magic_quotes_gpc=On,PHP解析器就会自动为post、get、cookie过来的数据增加转义字符“\”,以确保这些数据不会引起程序,特别是数据库语句因为特殊字符(认为是php的字符)引起的污染。
7.16、Mysql一个@和两个@什么区别
@为用户变量,使用SET @var1=1赋值
@@ 为系统变量 ,包括全局变量show global variables \G;和会话变量show session variables \G;

7.17、注入/绕过常用的函数
1、基于布尔SQL盲注
left(database(),1)>'s'
ascii(substr((select table_name information_schema.tables where tables_schema=database()limit 0,1),1,1))=101 --+
ascii(substr((select database()),1,1))=98
ORD(MID((SELECT IFNULL(CAST(username AS CHAR),0x20)FROM security.users ORDER BY id LIMIT 0,1),1,1))>98%23
regexp正则注入 select user() regexp '^[a-z]';
select user() like 'ro%'
2、基于报错的SQL盲注
1)and extractvalue(1, concat(0x7e,(select @@version),0x7e))】】】
2)通过floor报错 向下取整
3)+and updatexml(1, concat(0x7e,(secect @@version),0x7e),1)
4).geometrycollection()select * from test where id=1 and geometrycollection((select * from(select * from(select user())a)b));
5).multipoint()select * from test where id=1 and multipoint((select * from(select * from(select user())a)b));
6).polygon()select * from test where id=1 and polygon((select * from(select * from(select user())a)b));
7).multipolygon()select * from test where id=1 and multipolygon((select * from(select * from(select user())a)b));
8).linestring()select * from test where id=1 and linestring((select * from(select * from(select user())a)b));
9).multilinestring()select * from test where id=1 and multilinestring((select * from(select * from(select user())a)b));
10).exp()select * from test where id=1 and exp(~(select * from(select user())a));
3、延时注入如何来判断?
if(ascii(substr(“hello”, 1, 1))=104, sleep(5), 1)
7.18、盲注和延时注入的共同点?
都是一个字符一个字符的判断
7.19、如何拿一个网站的webshell?
上传,后台编辑模板,sql注入写文件,命令执行,代码执行,
一些已经爆出的cms漏洞,比如dedecms后台可以直接建立脚本文件,wordpress上传插件包含脚本文件zip压缩包等
7.20、sql注入写文件都有哪些函数?
select ‘一句话’ into outfile ‘路径’
select ‘一句话’ into dumpfile ‘路径’
select ‘’ into dumpfile ‘d:\wwwroot\baidu.com\nvhack.php’;
7.21、各种写shell的问题
1、写shell用什么函数?
select ' into outfile 'D:/shelltest.php'
dumpfile
file_put_contents
2、outfile不能用了怎么办?
select unhex('udf.dll hex code') into dumpfile 'c:/mysql/mysql server 5.1/lib/plugin/xxoo.dll';可以UDF提权
3、dumpfile和outfile有什么不一样?outfile适合导库,在行末尾会写入新行并转义,因此不能写入二进制可执行文件。
4、sleep()能不能写shell?
5、写shell的条件?
用户权限
目录读写权限
防止命令执行:disable_functions,禁止了disable_functions=phpinfo,exec,passthru,shell_exec,system,proc_open,popen,curl_exec,curl_multi_exec,parse_ini_file,show_source,但是可以用dl扩展执行命令或者ImageMagick漏洞
open_basedir: 将用户可操作的文件限制在某目录下
7.22、sql注入写文件都有哪些函数?
select ‘一句话’ into outfile ‘路径’
select ‘一句话’ into dumpfile ‘路径’
select ‘’ into dumpfile ‘d:\wwwroot\baidu.com\nvhack.php’;
7.23、sql二次注入
第一次进行数据库插入数据的时候,仅仅只是使用了 addslashes 或者是借助 get_magic_quotes_gpc 对其中的特殊字符进行了转义,在写入数据库的时候还是保留了原来的数据,但是数据本身还是脏数据。
在将数据存入到了数据库中之后,开发者就认为数据是可信的。在下一次进行需要进行查询的时候,直接从数据库中取出了脏数据,没有进行进一步的检验和处理,这样就会造成SQL的二次注入。
交友网站,填写年龄处是一个注入点,页面会显示出与你相同年龄的用户有几个。使用and 1=1确定注入点,用order by探测列数,union select探测输出点是第几列,
暴库 group_concat(schema_name) from information_schema.schemata
暴表 group_concat(table_name) from information_schema.schemata where table_schema='hhh'
获取数据 concat(flag) from flag
修复:在从数据库或文件中取数据的时候,也要进行转义或者过滤。
7.24、SQL和NoSQL的区别
SQL关系型数据库,NoSQL(Not only SQL)非关系型数据库
1.SQL优点
关系型数据库是指用关系数学模型来表示的数据,其中是以二维表的形式描述数据。
结构稳定,不易修改,常用联表查询
查询能力高,可以操作很复杂的查询
一致性高,处理数据会使用封锁保证数据不被改变
表具有逻辑性,易于理解
2.SQL缺点
不适用高并发读写
不适用海量数据高效读写
层次多,扩展性低
维护一致性开销大
涉及联表查询,复杂,慢
3.NoSQL优点
采用键值对存储数据
由于数据之间没有关系,所以易扩展,也易于查询
数据结构灵活,每个数据都可以有不同的结构
由于降低了一致性的要求,所以查询速度更快
4.比较
非关系型数据库的产生是因为随着网站的进化,并发性增加,扩展性高,一致性要求降低。这样关系型数据库最重要的一致性维护就显得有点多余,并且消耗着性能。因此有了非关系型数据库,它可以算是关系型数据库的一种弱化的结果,在海量数据存储和查询上更胜一筹。
两种数据库没有好坏之分,只是使用的环境不一样。关系型数据库可以说是更严谨的,可靠性更强的数据库,在对于数据精度要求高的环境,比如说银行系统这样自然是像mysql这样的数据库适合。非关系型数据库胜在处理大数据的速度,但是对于数据的准确度没有那么高,对于操作量大的环境比如当前大部分web2.0的网站更加适用一些。
由于文章字数限制,剩下的面试题都已整理好pdf文档以图片的形式展示
需要剩下完整面试题的伙伴可以在评论区发送【求分享】,我挨个发,或者关注后自动发送哦