安装nvidia-docker及安装过程出现的问题
因为实验需要用到nvidia-docker,所以需要在Ubuntu18.04服务器安装,以下为我的安装记录:
关于nvidia-docker,英伟达官方是有文件教我们该怎么安装的:官方文档
简单来说,就是按照文档走一遍,但是还是会出现一些小问题,所以在这里记录一下(所有的命令都是需要有sudo权限的,我实在root用户下进行操作的,所有命令前面没有加sudo):
首先是安装docker
我用的服务器本身会有docker,所以直接跳过了这一步,
基于docker进行nvidia-docker的安装:
第一步启动docker
curl https://get.docker.com | sh \
&& sudo systemctl --now enable docker
这一步基本不会有什么问题
第二步是在源中增加支持nvidia-docker的部分
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
第三步是更新源
apt-get update
这一步我就开始报错了:
![]()
E: Conflicting values set for option Signed-By regarding source https://nvidia.github.io/libnvidia-container/stable/ubuntu18.04/amd64/ /: /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg !=
E: The list of sources could not be read.
在网上有找到英伟达官方处理该种情况的文章:地址
一般是删除grep -l "nvidia.github.io" /etc/apt/sources.list.d/* | grep -vE "/nvidia-container-toolkit.list\$"该命令运行结果的文件就能够处理,这里我是按照这个办法成功处理的
之后分别是安装英伟达容器的toolkit、配置 Docker 守护进程以识别 NVIDIA 容器运行、重启docker。
apt-get install -y nvidia-container-toolkit
nvidia-ctk runtime configure --runtime=docker
systemctl restart docker
最后是对安装结果的测试,以下是官方给出的测试命令:
sudo docker run --rm --runtime=nvidia --gpus all nvidia/cuda:11.6.2-base-ubuntu20.04 nvidia-smi
这里要注意的是nvidia/cuda:11.6.2-base-ubuntu20.04这一部分,需要的是适合你的cuda版本以及Ubuntu版本,而不是盲目的抄这条命令。
一般运行成功的话,会出现下面这种结果(如果是第一次运行这个命令的话,可能会需要一段时间等他的一些东西下载好):
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.51.06 Driver Version: 450.51.06 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 34C P8 9W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
官方文档到此为止。
测试出错
但是我在运行上面这条命令的时候还是会报错,报错具体内容没有记录,但是大致意思就是版本不匹配,找了很多教程,发现了这条命令可行:
docker run -it --rm --name test --gpus all ubuntu:latest
但是这条命令运行出来会是直接在命令行进入docker界面,需要再次输入nvidia-smi才会输出上述结果,如下:
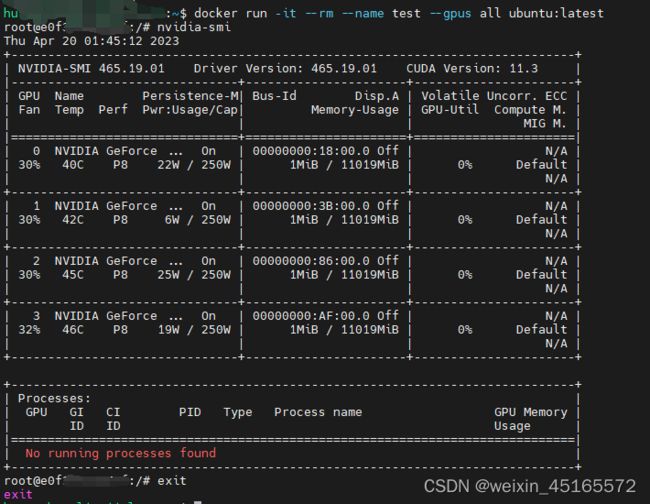
第一行是服务器的终端命令,第二行是进入docker以后的命令。
其他错误
但是其实我在这些命令结束以后,使用nvidia-docker还是会有报错,报错结果是nvidia-docker: command not found,具体原因没搞明白,有点偷懒,直接在网上找了安装nvidia-docker的教程进行安装(这些教程大部分不同于英伟达的,安装了nvidia-docker2,这么一个东西),直接从安装英伟达docker这个步骤开始教程:
- 增加nvidia-docker存储库
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \ sudo apt-key add - curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-docker.list | \ sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update - 安装
apt-gei install nvidia-docker2 - 重启docker
service docker restart - 测试
nvidia-docker
结果:
我这里是一路下来就直接测试成功了
添加用户
还有一个要注意的是,需要考虑你作为普通用户是不能使用docker的,需要管理员将你的账号添加到docker这个用户组里,你才能使用docker:
usermod -aG docker <用户名>
systemctl restart docker